 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeting for long-term outcomes
Oct 29, 2020
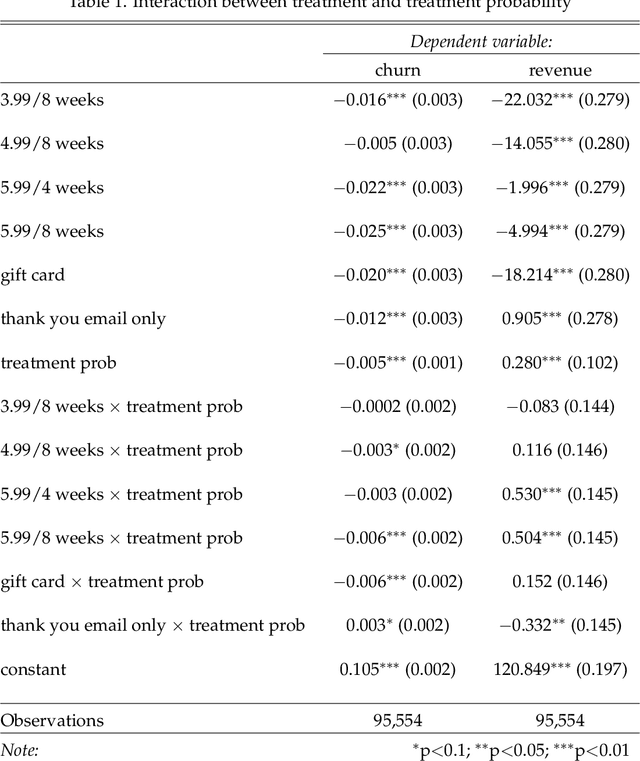
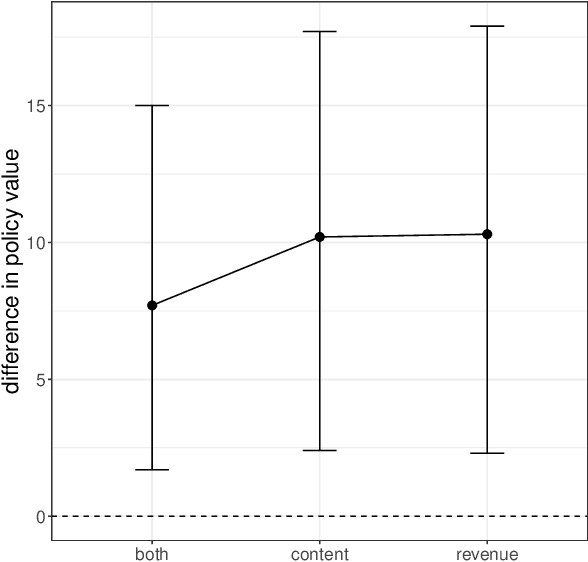
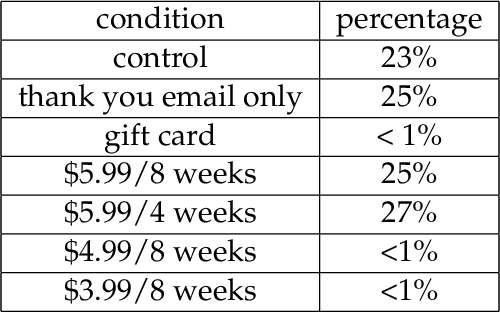
Decision-makers often want to target interventions (e.g., marketing campaigns) so as to maximize an outcome that is observed only in the long-term. This typically requires delaying decisions until the outcome is observed or relying on simple short-term proxies for the long-term outcome. Here we build on the statistical surrogacy and off-policy learning literature to impute the missing long-term outcomes and then approximate the optimal targeting policy on the imputed outcomes via a doubly-robust approach. We apply our approach in large-scale proactive churn management experiments at The Boston Globe by targeting optimal discounts to its digital subscribers to maximize their long-term revenue. We first show that conditions for validity of average treatment effect estimation with imputed outcomes are also sufficient for valid policy evaluation and optimization; furthermore, these conditions can be somewhat relaxed for policy optimization. We then validate this approach empirically by comparing it with a policy learned on the ground truth long-term outcomes and show that they are statistically indistinguishable. Our approach also outperforms a policy learned on short-term proxies for the long-term outcome. In a second field experiment, we implement the optimal targeting policy with additional randomized exploration, which allows us to update the optimal policy for each new cohort of customers to account for potential non-stationarity. Over three years, our approach had a net-positive revenue impact in the range of $4-5 million compared to The Boston Globe's current policies.
Scalable bundling via dense product embeddings
Jan 31, 2020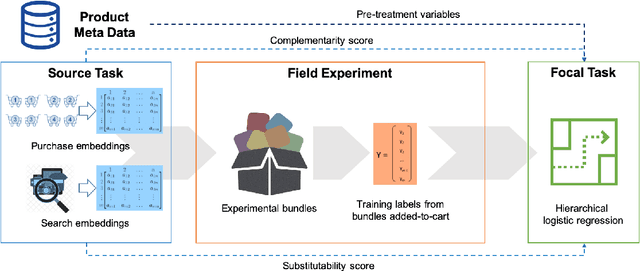
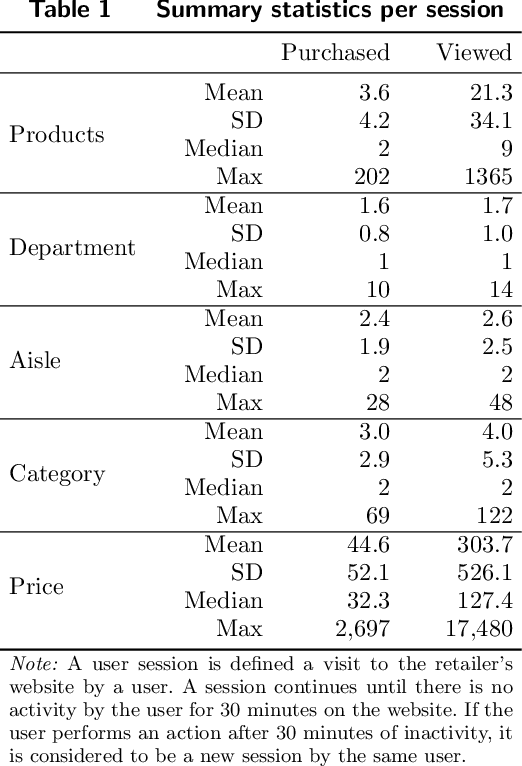
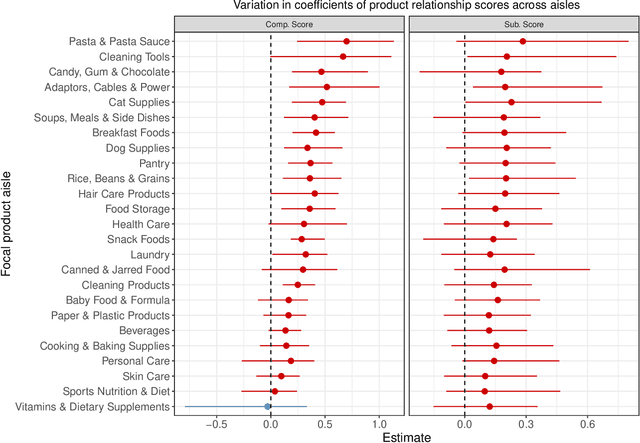
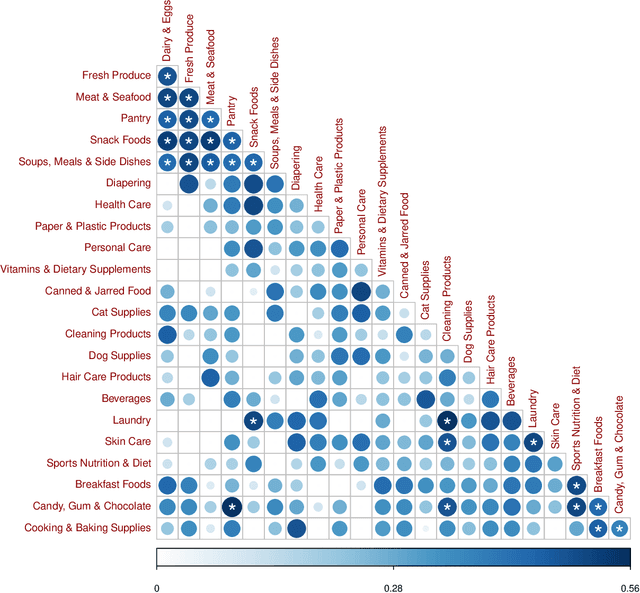
Bundling, the practice of jointly selling two or more products at a discount, is a widely used strategy in industry and a well examined concept in academia. Historically, the focus has been on theoretical studies in the context of monopolistic firms and assumed product relationships, e.g., complementarity in usage. We develop a new machine-learning-driven methodology for designing bundles in a large-scale, cross-category retail setting. We leverage historical purchases and consideration sets created from clickstream data to generate dense continuous representations of products called embeddings. We then put minimal structure on these embeddings and develop heuristics for complementarity and substitutability among products. Subsequently, we use the heuristics to create multiple bundles for each product and test their performance using a field experiment with a large retailer. We combine the results from the experiment with product embeddings using a hierarchical model that maps bundle features to their purchase likelihood, as measured by the add-to-cart rate. We find that our embeddings-based heuristics are strong predictors of bundle success, robust across product categories, and generalize well to the retailer's entire assortment.
Bias and high-dimensional adjustment in observational studies of peer effects
Jun 14, 2017

Peer effects, in which the behavior of an individual is affected by the behavior of their peers, are posited by multiple theories in the social sciences. Other processes can also produce behaviors that are correlated in networks and groups, thereby generating debate about the credibility of observational (i.e. nonexperimental) studies of peer effects. Randomized field experiments that identify peer effects, however, are often expensive or infeasible. Thus, many studies of peer effects use observational data, and prior evaluations of causal inference methods for adjusting observational data to estimate peer effects have lacked an experimental "gold standard" for comparison. Here we show, in the context of information and media diffusion on Facebook, that high-dimensional adjustment of a nonexperimental control group (677 million observations) using propensity score models produces estimates of peer effects statistically indistinguishable from those from using a large randomized experiment (220 million observations). Naive observational estimators overstate peer effects by 320% and commonly used variables (e.g., demographics) offer little bias reduction, but adjusting for a measure of prior behaviors closely related to the focal behavior reduces bias by 91%. High-dimensional models adjusting for over 3,700 past behaviors provide additional bias reduction, such that the full model reduces bias by over 97%. This experimental evaluation demonstrates that detailed records of individuals' past behavior can improve studies of social influence, information diffusion, and imitation; these results are encouraging for the credibility of some studies but also cautionary for studies of rare or new behaviors. More generally, these results show how large, high-dimensional data sets and statistical learning techniques can be used to improve causal inference in the behavioral sciences.
Learning causal effects from many randomized experiments using regularized instrumental variables
Jun 01, 2017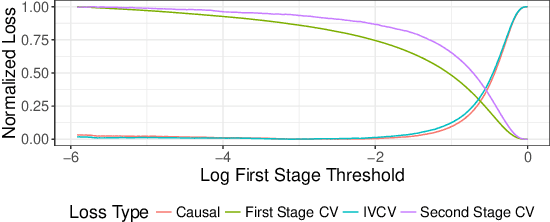
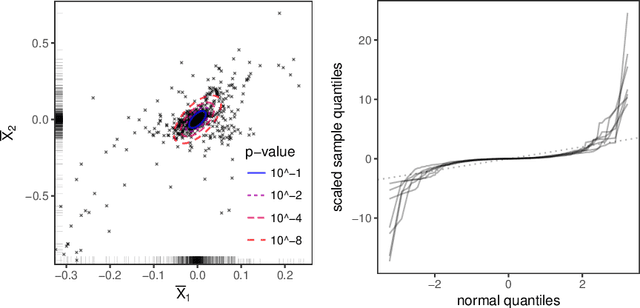
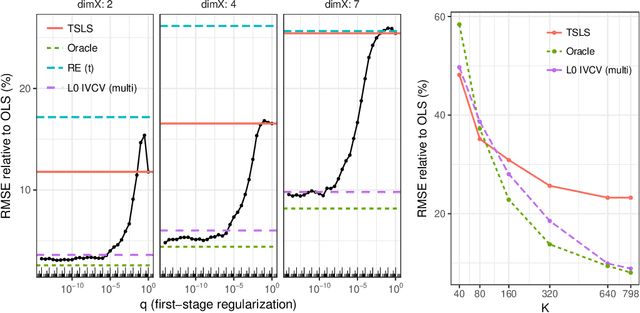
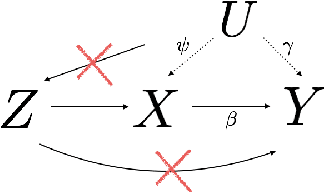
Scientific and business practices are increasingly resulting in large collections of randomized experiments. Analyzed together, these collections can tell us things that individual experiments in the collection cannot. We study how to learn causal relationships between variables from the kinds of collections faced by modern data scientists: the number of experiments is large, many experiments have very small effects, and the analyst lacks metadata (e.g., descriptions of the interventions). Here we use experimental groups as instrumental variables (IV) and show that a standard method (two-stage least squares) is biased even when the number of experiments is infinite. We show how a sparsity-inducing l0 regularization can --- in a reversal of the standard bias--variance tradeoff in regularization --- reduce bias (and thus error) of interventional predictions. Because we are interested in interventional loss minimization we also propose a modified cross-validation procedure (IVCV) to feasibly select the regularization parameter. We show, using a trick from Monte Carlo sampling, that IVCV can be done using summary statistics instead of raw data. This makes our full procedure simple to use in many real-world applications.
Thompson sampling with the online bootstrap
Oct 15, 2014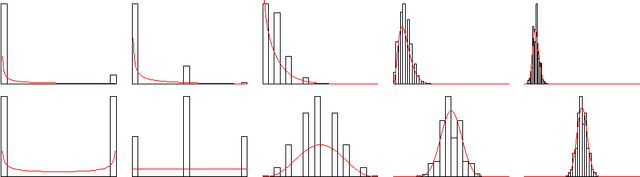
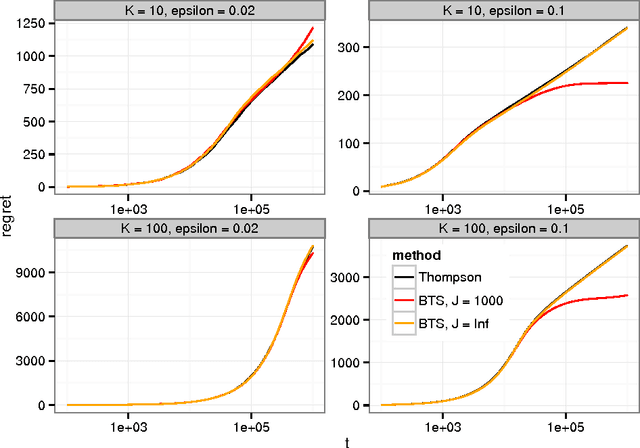
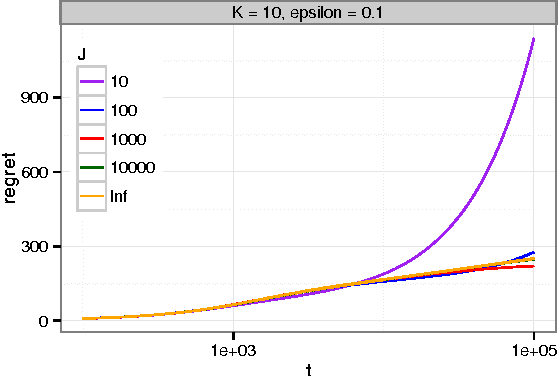
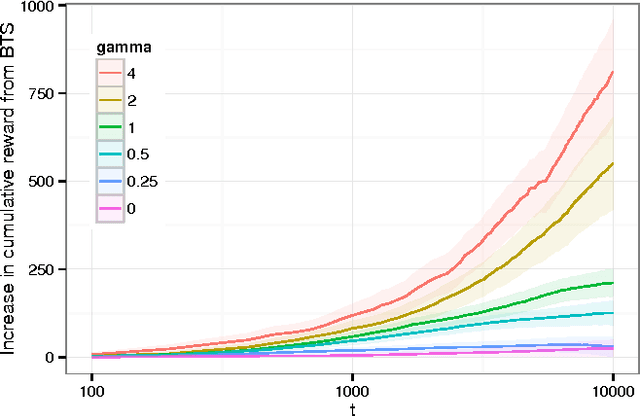
Thompson sampling provides a solution to bandit problems in which new observations are allocated to arms with the posterior probability that an arm is optimal. While sometimes easy to implement and asymptotically optimal, Thompson sampling can be computationally demanding in large scale bandit problems, and its performance is dependent on the model fit to the observed data. We introduce bootstrap Thompson sampling (BTS), a heuristic method for solving bandit problems which modifies Thompson sampling by replacing the posterior distribution used in Thompson sampling by a bootstrap distribution. We first explain BTS and show that the performance of BTS is competitive to Thompson sampling in the well-studied Bernoulli bandit case. Subsequently, we detail why BTS using the online bootstrap is more scalable than regular Thompson sampling, and we show through simulation that BTS is more robust to a misspecified error distribution. BTS is an appealing modification of Thompson sampling, especially when samples from the posterior are otherwise not available or are costly.