 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow AI Agents Reshape Knowledge Work: Autonomy, Efficiency, and Scope
Jun 05, 2026Frontier AI systems are bridging the gap between intelligence and utility by shifting from conversational assistants to autonomous agents that execute tasks end to end. Using production data from Perplexity's Search and Computer products, we study this transition by examining how AI agents accelerate and reshape knowledge work. Three key empirical findings emerge. First, using sessions with near-identical initial query pairs as natural experiments for the same underlying task attempted with both products, Computer performs 26 minutes of autonomous work per user session, versus 33 seconds for Search. Computer automates task decomposition and execution that Search users might otherwise manually orchestrate and implement. As a result, Computer shifts follow-up query distribution toward higher-order work such as verification and extension. Autonomy also increases execution quality, with per-query dissatisfaction rates 55% lower on Computer than on Search. Second, due to its autonomy advantage, Computer reduces completion time from 269 to 36 minutes on matched tasks, lowering estimated time and cost by 87% and 94%, respectively, compared to humans equipped with Search alone. Third, Computer changes the scope of work that users attempt: Computer queries more often cross occupational boundaries, require higher-order cognition, draw on broader expertise, take the form of composite tasks that bundle interdependent subtasks into a single query, and unlock work activities that are essentially absent from Search usage among the same users. Together, the evidence indicates that AI agents accelerate workflows, enhance output quality, reduce costs, and expand the breadth and depth of automated work.
DRACO: a Cross-Domain Benchmark for Deep Research Accuracy, Completeness, and Objectivity
Feb 12, 2026We present DRACO (Deep Research Accuracy, Completeness, and Objectivity), a benchmark of complex deep research tasks. These tasks, which span 10 domains and draw on information sources from 40 countries, originate from anonymized real-world usage patterns within a large-scale deep research system. Tasks are sampled from a de-identified dataset of Perplexity Deep Research requests, then filtered and augmented to ensure that the tasks are anonymized, open-ended and complex, objectively evaluable, and representative of the broad scope of real-world deep research use cases. Outputs are graded against task-specific rubrics along four dimensions: factual accuracy (accuracy), breadth and depth of analysis (including completeness), presentation quality (including objectivity), and citation quality. DRACO is publicly available at https://hf.co/datasets/perplexity-ai/draco.
The Adoption and Usage of AI Agents: Early Evidence from Perplexity
Dec 10, 2025



This paper presents the first large-scale field study of the adoption, usage intensity, and use cases of general-purpose AI agents operating in open-world web environments. Our analysis centers on Comet, an AI-powered browser developed by Perplexity, and its integrated agent, Comet Assistant. Drawing on hundreds of millions of anonymized user interactions, we address three fundamental questions: Who is using AI agents? How intensively are they using them? And what are they using them for? Our findings reveal substantial heterogeneity in adoption and usage across user segments. Earlier adopters, users in countries with higher GDP per capita and educational attainment, and individuals working in digital or knowledge-intensive sectors -- such as digital technology, academia, finance, marketing, and entrepreneurship -- are more likely to adopt or actively use the agent. To systematically characterize the substance of agent usage, we introduce a hierarchical agentic taxonomy that organizes use cases across three levels: topic, subtopic, and task. The two largest topics, Productivity & Workflow and Learning & Research, account for 57% of all agentic queries, while the two largest subtopics, Courses and Shopping for Goods, make up 22%. The top 10 out of 90 tasks represent 55% of queries. Personal use constitutes 55% of queries, while professional and educational contexts comprise 30% and 16%, respectively. In the short term, use cases exhibit strong stickiness, but over time users tend to shift toward more cognitively oriented topics. The diffusion of increasingly capable AI agents carries important implications for researchers, businesses, policymakers, and educators, inviting new lines of inquiry into this rapidly emerging class of AI capabilities.
Targeting for long-term outcomes
Oct 29, 2020
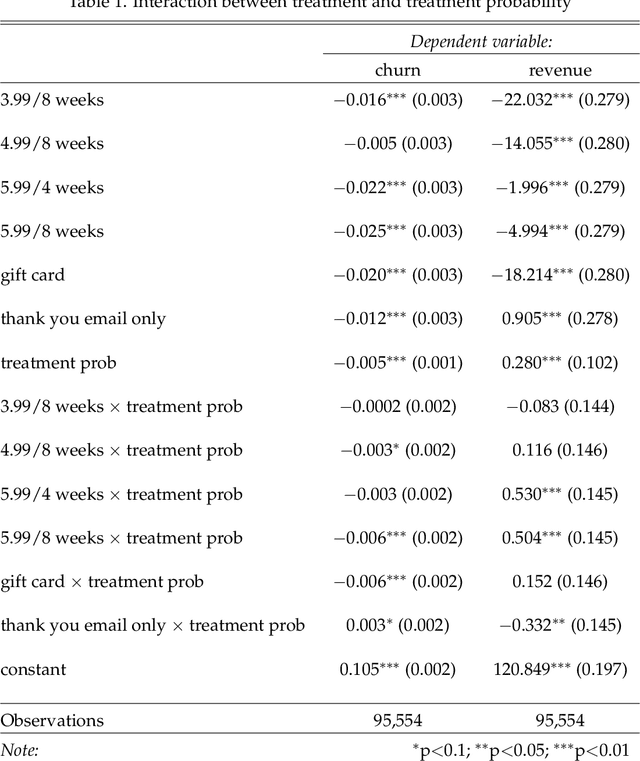
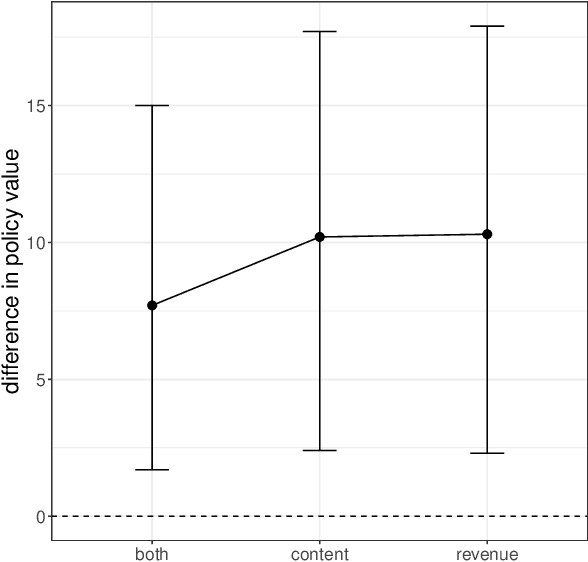
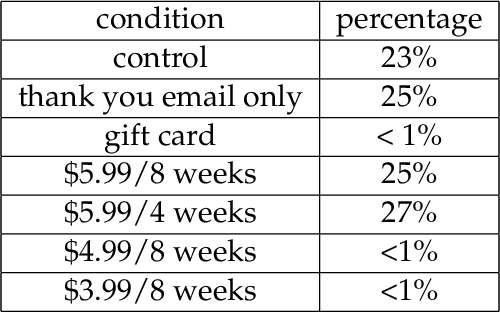
Decision-makers often want to target interventions (e.g., marketing campaigns) so as to maximize an outcome that is observed only in the long-term. This typically requires delaying decisions until the outcome is observed or relying on simple short-term proxies for the long-term outcome. Here we build on the statistical surrogacy and off-policy learning literature to impute the missing long-term outcomes and then approximate the optimal targeting policy on the imputed outcomes via a doubly-robust approach. We apply our approach in large-scale proactive churn management experiments at The Boston Globe by targeting optimal discounts to its digital subscribers to maximize their long-term revenue. We first show that conditions for validity of average treatment effect estimation with imputed outcomes are also sufficient for valid policy evaluation and optimization; furthermore, these conditions can be somewhat relaxed for policy optimization. We then validate this approach empirically by comparing it with a policy learned on the ground truth long-term outcomes and show that they are statistically indistinguishable. Our approach also outperforms a policy learned on short-term proxies for the long-term outcome. In a second field experiment, we implement the optimal targeting policy with additional randomized exploration, which allows us to update the optimal policy for each new cohort of customers to account for potential non-stationarity. Over three years, our approach had a net-positive revenue impact in the range of $4-5 million compared to The Boston Globe's current policies.