 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance Estimation to Support Assistive Drones for the Visually Impaired using Robust Calibration
Mar 31, 2025Autonomous navigation by drones using onboard sensors, combined with deep learning and computer vision algorithms, is impacting a number of domains. We examine the use of drones to autonomously assist Visually Impaired People (VIPs) in navigating outdoor environments while avoiding obstacles. Here, we present NOVA, a robust calibration technique using depth maps to estimate absolute distances to obstacles in a campus environment. NOVA uses a dynamic-update method that can adapt to adversarial scenarios. We compare NOVA with SOTA depth map approaches, and with geometric and regression-based baseline models, for distance estimation to VIPs and other obstacles in diverse and dynamic conditions. We also provide exhaustive evaluations to validate the robustness and generalizability of our methods. NOVA predicts distances to VIP with an error <30cm and to different obstacles like cars and bicycles with a maximum of 60cm error, which are better than the baselines. NOVA also clearly out-performs SOTA depth map methods, by upto 5.3-14.6x.
Scalable bundling via dense product embeddings
Jan 31, 2020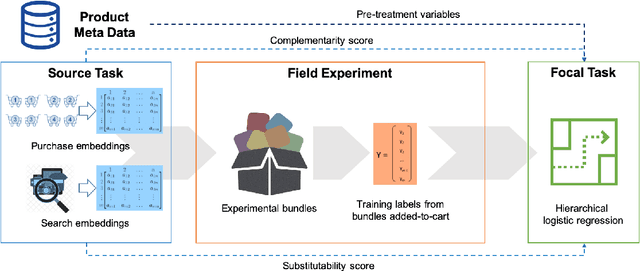
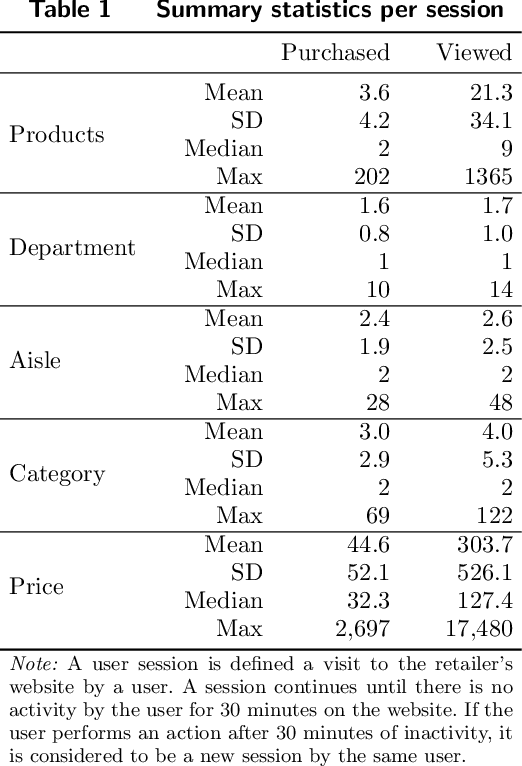
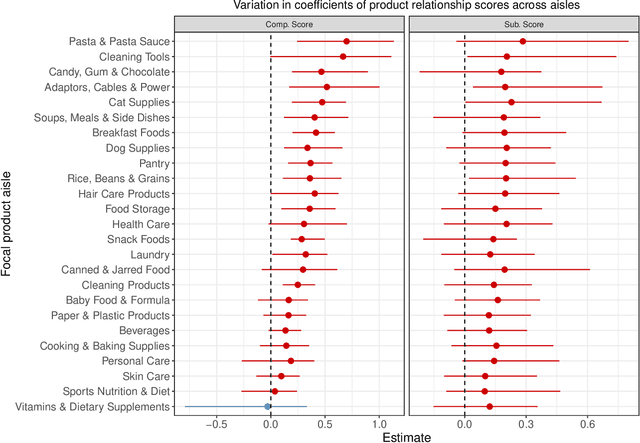
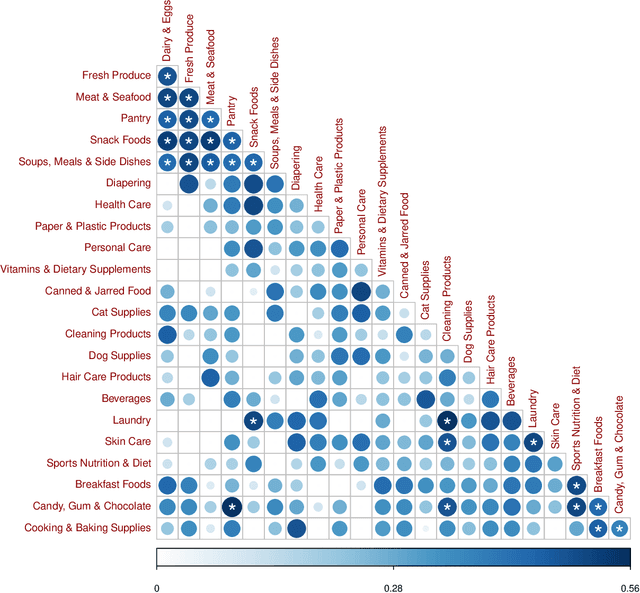
Bundling, the practice of jointly selling two or more products at a discount, is a widely used strategy in industry and a well examined concept in academia. Historically, the focus has been on theoretical studies in the context of monopolistic firms and assumed product relationships, e.g., complementarity in usage. We develop a new machine-learning-driven methodology for designing bundles in a large-scale, cross-category retail setting. We leverage historical purchases and consideration sets created from clickstream data to generate dense continuous representations of products called embeddings. We then put minimal structure on these embeddings and develop heuristics for complementarity and substitutability among products. Subsequently, we use the heuristics to create multiple bundles for each product and test their performance using a field experiment with a large retailer. We combine the results from the experiment with product embeddings using a hierarchical model that maps bundle features to their purchase likelihood, as measured by the add-to-cart rate. We find that our embeddings-based heuristics are strong predictors of bundle success, robust across product categories, and generalize well to the retailer's entire assortment.