 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable bundling via dense product embeddings
Paper and Code
Jan 31, 2020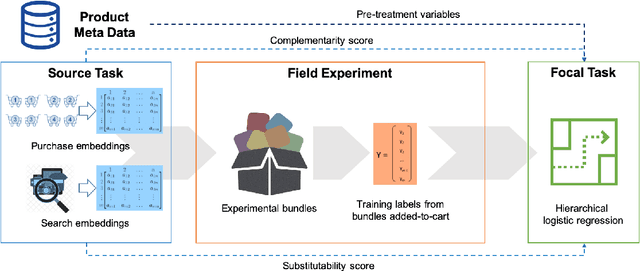
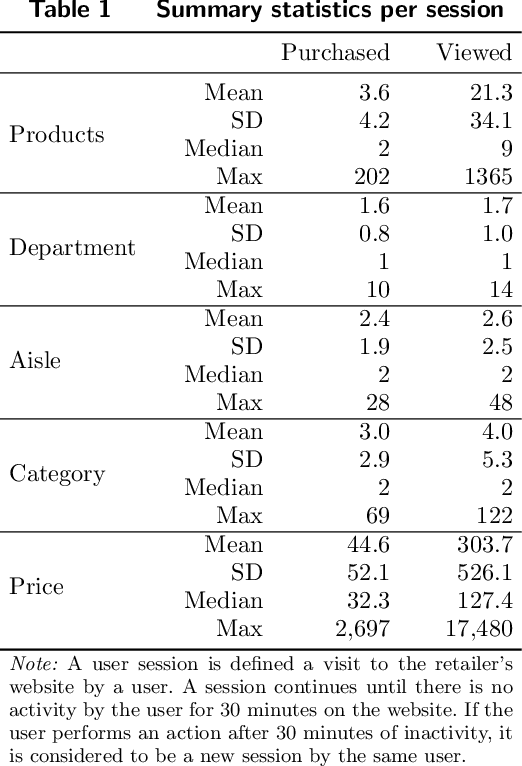
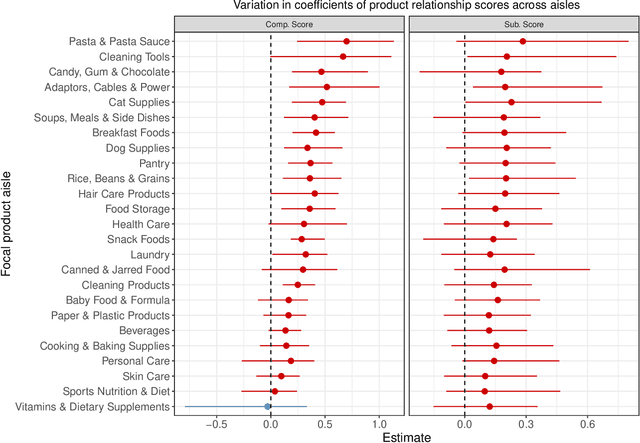
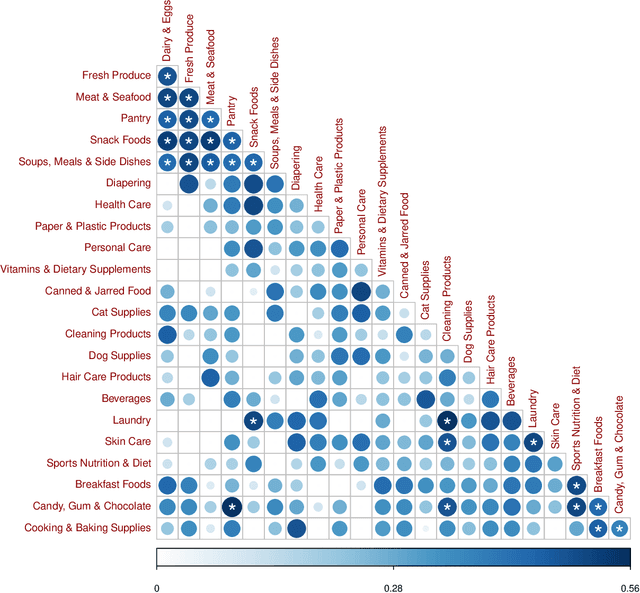
Bundling, the practice of jointly selling two or more products at a discount, is a widely used strategy in industry and a well examined concept in academia. Historically, the focus has been on theoretical studies in the context of monopolistic firms and assumed product relationships, e.g., complementarity in usage. We develop a new machine-learning-driven methodology for designing bundles in a large-scale, cross-category retail setting. We leverage historical purchases and consideration sets created from clickstream data to generate dense continuous representations of products called embeddings. We then put minimal structure on these embeddings and develop heuristics for complementarity and substitutability among products. Subsequently, we use the heuristics to create multiple bundles for each product and test their performance using a field experiment with a large retailer. We combine the results from the experiment with product embeddings using a hierarchical model that maps bundle features to their purchase likelihood, as measured by the add-to-cart rate. We find that our embeddings-based heuristics are strong predictors of bundle success, robust across product categories, and generalize well to the retailer's entire assortment.