 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMONET -- Virtual Cell Painting of Brightfield Images and Time Lapses Using Reference Consistent Diffusion
Dec 12, 2025Cell painting is a popular technique for creating human-interpretable, high-contrast images of cell morphology. There are two major issues with cell paint: (1) it is labor-intensive and (2) it requires chemical fixation, making the study of cell dynamics impossible. We train a diffusion model (Morphological Observation Neural Enhancement Tool, or MONET) on a large dataset to predict cell paint channels from brightfield images. We show that model quality improves with scale. The model uses a consistency architecture to generate time-lapse videos, despite the impossibility of obtaining cell paint video training data. In addition, we show that this architecture enables a form of in-context learning, allowing the model to partially transfer to out-of-distribution cell lines and imaging protocols. Virtual cell painting is not intended to replace physical cell painting completely, but to act as a complementary tool enabling novel workflows in biological research.
MUMU: Bootstrapping Multimodal Image Generation from Text-to-Image Data
Jun 26, 2024We train a model to generate images from multimodal prompts of interleaved text and images such as "a <picture of a man> man and his <picture of a dog> dog in an <picture of a cartoon> animated style." We bootstrap a multimodal dataset by extracting semantically meaningful image crops corresponding to words in the image captions of synthetically generated and publicly available text-image data. Our model, MUMU, is composed of a vision-language model encoder with a diffusion decoder and is trained on a single 8xH100 GPU node. Despite being only trained on crops from the same image, MUMU learns to compose inputs from different images into a coherent output. For example, an input of a realistic person and a cartoon will output the same person in the cartoon style, and an input of a standing subject and a scooter will output the subject riding the scooter. As a result, our model generalizes to tasks such as style transfer and character consistency. Our results show the promise of using multimodal models as general purpose controllers for image generation.
Attention Sorting Combats Recency Bias In Long Context Language Models
Sep 28, 2023



Current language models often fail to incorporate long contexts efficiently during generation. We show that a major contributor to this issue are attention priors that are likely learned during pre-training: relevant information located earlier in context is attended to less on average. Yet even when models fail to use the information from a relevant document in their response, they still pay preferential attention to that document compared to an irrelevant document at the same position. We leverage this fact to introduce ``attention sorting'': perform one step of decoding, sort documents by the attention they receive (highest attention going last), repeat the process, generate the answer with the newly sorted context. We find that attention sorting improves performance of long context models. Our findings highlight some challenges in using off-the-shelf language models for retrieval augmented generation.
Diagnosis Uncertain Models For Medical Risk Prediction
Jun 29, 2023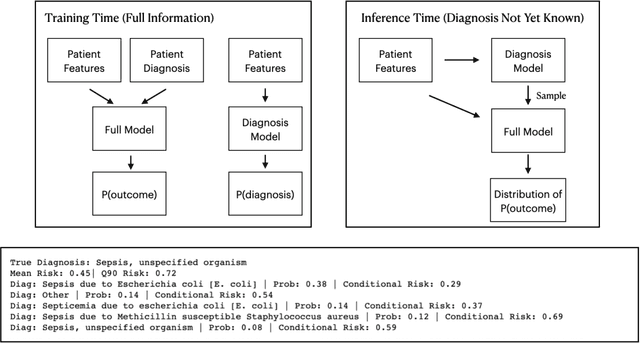
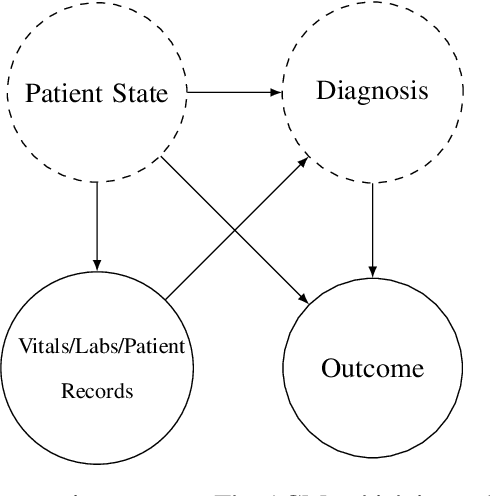
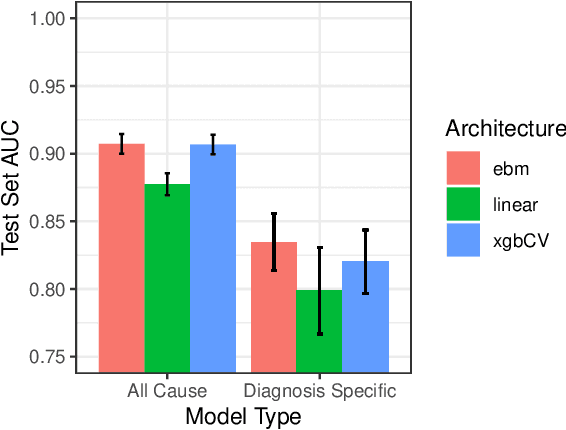
We consider a patient risk models which has access to patient features such as vital signs, lab values, and prior history but does not have access to a patient's diagnosis. For example, this occurs in a model deployed at intake time for triage purposes. We show that such `all-cause' risk models have good generalization across diagnoses but have a predictable failure mode. When the same lab/vital/history profiles can result from diagnoses with different risk profiles (e.g. E.coli vs. MRSA) the risk estimate is a probability weighted average of these two profiles. This leads to an under-estimation of risk for rare but highly risky diagnoses. We propose a fix for this problem by explicitly modeling the uncertainty in risk prediction coming from uncertainty in patient diagnoses. This gives practitioners an interpretable way to understand patient risk beyond a single risk number.
An Attract-Repel Decomposition of Undirected Networks
Jun 17, 2021
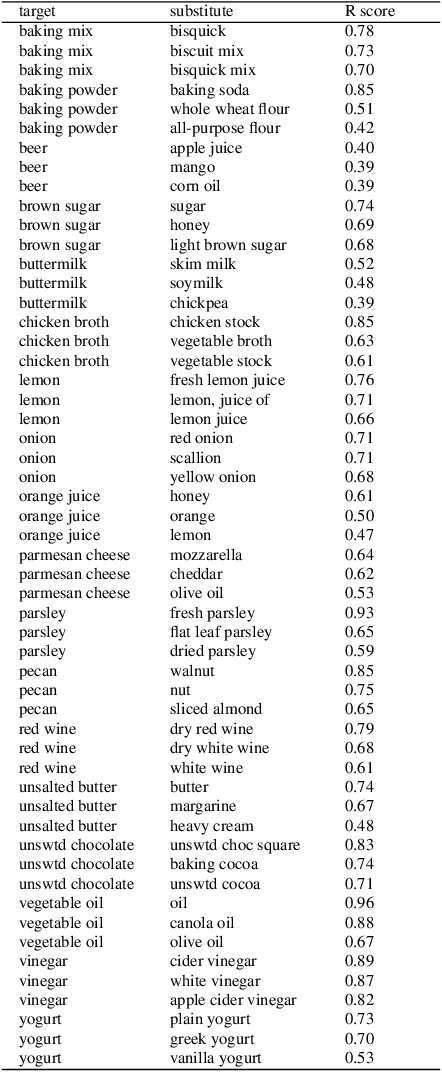
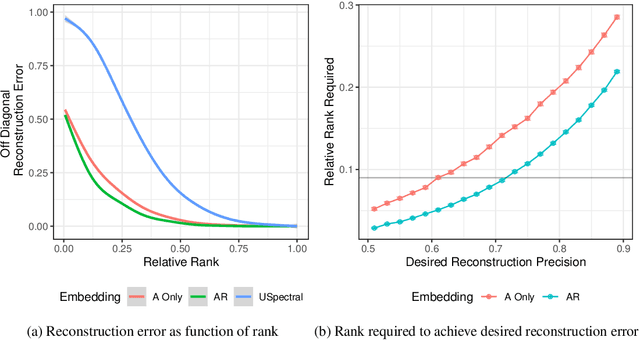
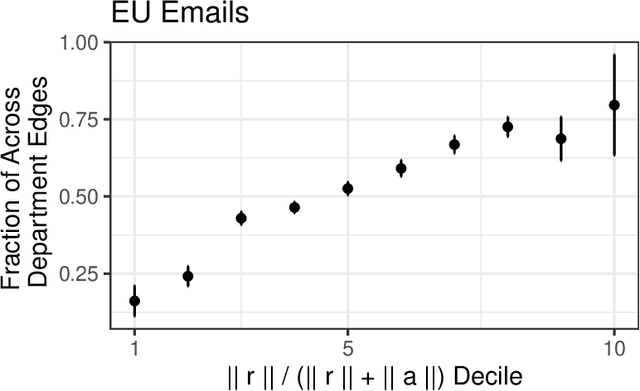
Dot product latent space embedding is a common form of representation learning in undirected graphs (e.g. social networks, co-occurrence networks). We show that such models have problems dealing with 'intransitive' situations where A is linked to B, B is linked to C but A is not linked to C. Such situations occur in social networks when opposites attract (heterophily) and in co-occurrence networks when there are substitute nodes (e.g. the presence of Pepsi or Coke, but rarely both, in otherwise similar purchase baskets). We present a simple expansion which we call the attract-repel (AR) decomposition: a set of latent attributes on which similar nodes attract and another set of latent attributes on which similar nodes repel. We demonstrate the AR decomposition in real social networks and show that it can be used to measure the amount of latent homophily and heterophily. In addition, it can be applied to co-occurrence networks to discover roles in teams and find substitutable ingredients in recipes.
Evaluating and Rewarding Teamwork Using Cooperative Game Abstractions
Jun 16, 2020

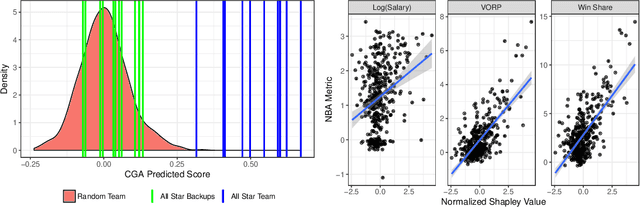

Can we predict how well a team of individuals will perform together? How should individuals be rewarded for their contributions to the team performance? Cooperative game theory gives us a powerful set of tools for answering these questions: the Characteristic Function (CF) and solution concepts like the Shapley Value (SV). There are two major difficulties in applying these techniques to real world problems: first, the CF is rarely given to us and needs to be learned from data. Second, the SV is combinatorial in nature. We introduce a parametric model called cooperative game abstractions (CGAs) for estimating CFs from data. CGAs are easy to learn, readily interpretable, and crucially allow linear-time computation of the SV. We provide identification results and sample complexity bounds for CGA models as well as error bounds in the estimation of the SV using CGAs. We apply our methods to study teams of artificial RL agents as well as real world teams from professional sports.
Fair Division Without Disparate Impact
Jun 06, 2019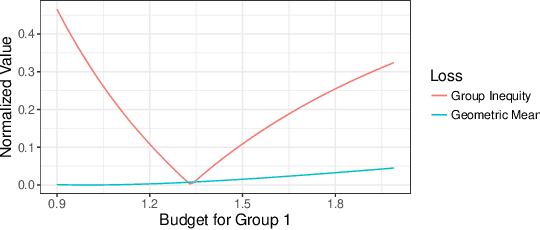
We consider the problem of dividing items between individuals in a way that is fair both in the sense of distributional fairness and in the sense of not having disparate impact across protected classes. An important existing mechanism for distributionally fair division is competitive equilibrium from equal incomes (CEEI). Unfortunately, CEEI will not, in general, respect disparate impact constraints. We consider two types of disparate impact measures: requiring that allocations be similar across protected classes and requiring that average utility levels be similar across protected classes. We modify the standard CEEI algorithm in two ways: equitable equilibrium from equal incomes, which removes disparate impact in allocations, and competitive equilibrium from equitable incomes which removes disparate impact in attained utility levels. We show analytically that removing disparate impact in outcomes breaks several of CEEI's desirable properties such as envy, regret, Pareto optimality, and incentive compatibility. By contrast, we can remove disparate impact in attained utility levels without affecting these properties. Finally, we experimentally evaluate the tradeoffs between efficiency, equity, and disparate impact in a recommender-system based market.
Robust Multi-agent Counterfactual Prediction
Apr 03, 2019
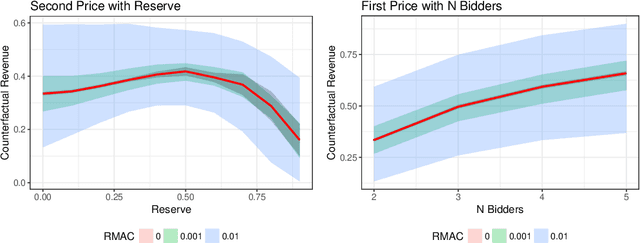
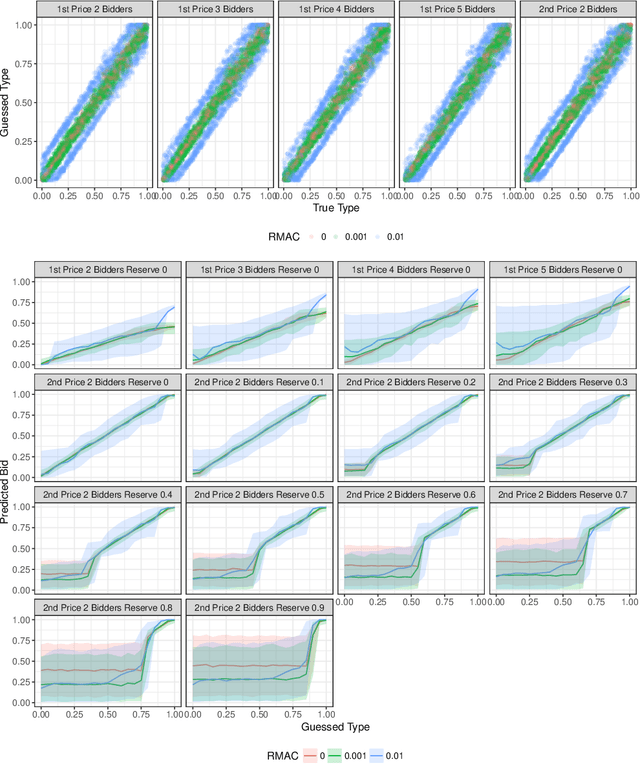
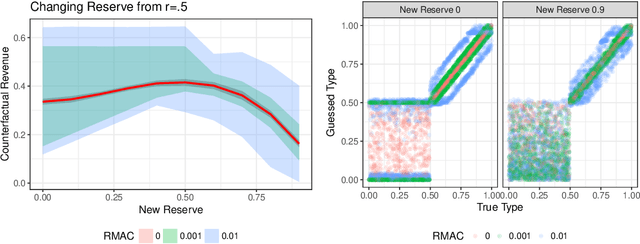
We consider the problem of using logged data to make predictions about what would happen if we changed the `rules of the game' in a multi-agent system. This task is difficult because in many cases we observe actions individuals take but not their private information or their full reward functions. In addition, agents are strategic, so when the rules change, they will also change their actions. Existing methods (e.g. structural estimation, inverse reinforcement learning) make counterfactual predictions by constructing a model of the game, adding the assumption that agents' behavior comes from optimizing given some goals, and then inverting observed actions to learn agent's underlying utility function (a.k.a. type). Once the agent types are known, making counterfactual predictions amounts to solving for the equilibrium of the counterfactual environment. This approach imposes heavy assumptions such as rationality of the agents being observed, correctness of the analyst's model of the environment/parametric form of the agents' utility functions, and various other conditions to make point identification possible. We propose a method for analyzing the sensitivity of counterfactual conclusions to violations of these assumptions. We refer to this method as robust multi-agent counterfactual prediction (RMAC). We apply our technique to investigating the robustness of counterfactual claims for classic environments in market design: auctions, school choice, and social choice. Importantly, we show RMAC can be used in regimes where point identification is impossible (e.g. those which have multiple equilibria or non-injective maps from type distributions to outcomes).
Discovering Context Effects from Raw Choice Data
Feb 08, 2019
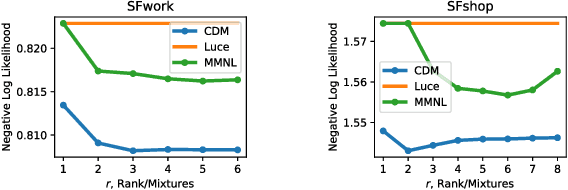
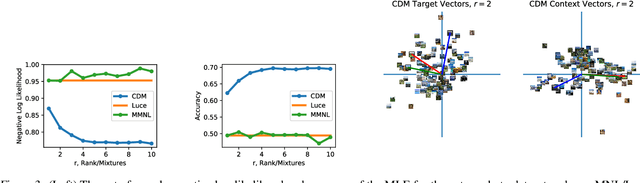
Many applications in preference learning assume that decisions come from the maximization of a stable utility function. Yet a large experimental literature shows that individual choices and judgements can be affected by "irrelevant" aspects of the context in which they are made. An important class of such contexts is the composition of the choice set. In this work, our goal is to discover such choice set effects from raw choice data. We introduce an extension of the Multinomial Logit (MNL) model, called the context dependent random utility model (CDM), which allows for a particular class of choice set effects. We show that the CDM can be thought of as a second-order approximation to a general choice system, can be inferred optimally using maximum likelihood and, importantly, is easily interpretable. We apply the CDM to both real and simulated choice data to perform principled exploratory analyses for the presence of choice set effects.
Computing large market equilibria using abstractions
Jan 18, 2019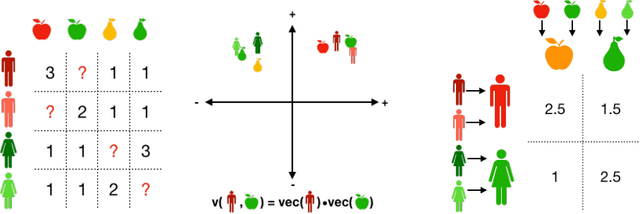
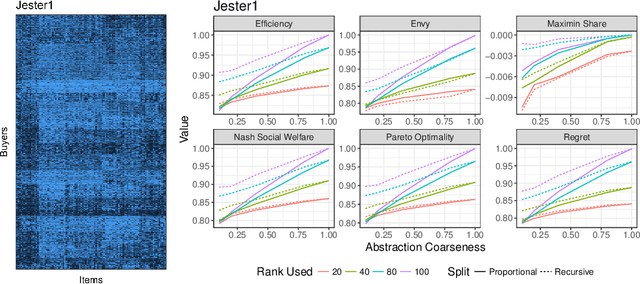
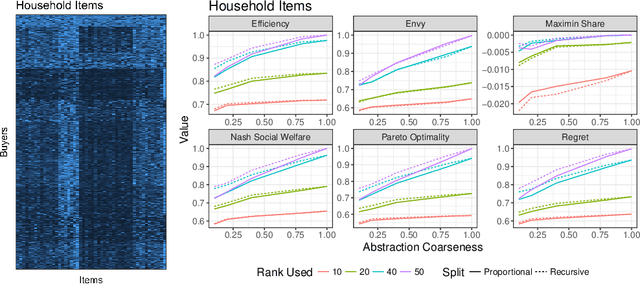
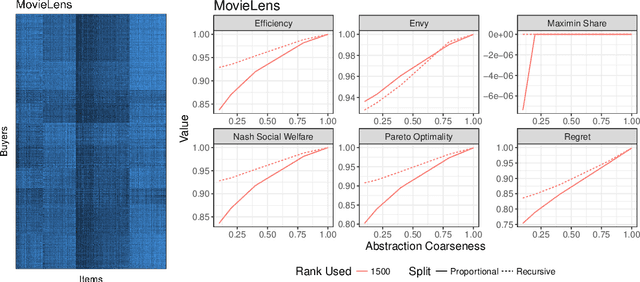
Computing market equilibria is an important practical problem for market design (e.g. fair division, item allocation). However, computing equilibria requires large amounts of information (e.g. all valuations for all buyers for all items) and compute power. We consider ameliorating these issues by applying a method used for solving complex games: constructing a coarsened abstraction of a given market, solving for the equilibrium in the abstraction, and lifting the prices and allocations back to the original market. We show how to bound important quantities such as regret, envy, Nash social welfare, Pareto optimality, and maximin share when the abstracted prices and allocations are used in place of the real equilibrium. We then study two abstraction methods of interest for practitioners: 1) filling in unknown valuations using techniques from matrix completion, 2) reducing the problem size by aggregating groups of buyers/items into smaller numbers of representative buyers/items and solving for equilibrium in this coarsened market. We find that in real data allocations/prices that are relatively close to equilibria can be computed from even very coarse abstractions.