 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAMformer: In-Context Learning for Generalized Additive Models
Oct 06, 2024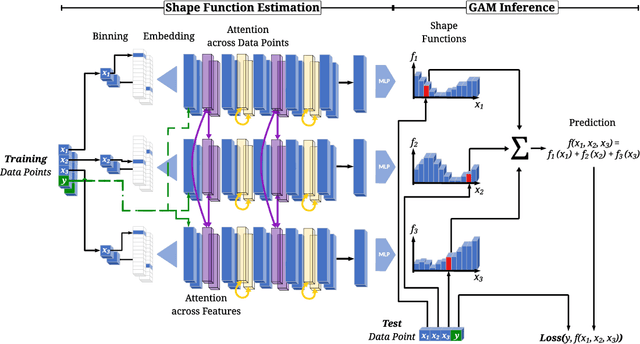
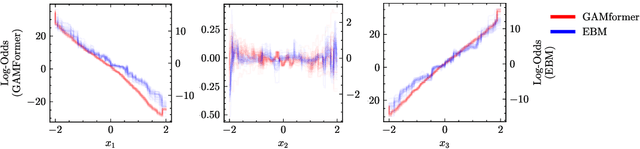

Generalized Additive Models (GAMs) are widely recognized for their ability to create fully interpretable machine learning models for tabular data. Traditionally, training GAMs involves iterative learning algorithms, such as splines, boosted trees, or neural networks, which refine the additive components through repeated error reduction. In this paper, we introduce GAMformer, the first method to leverage in-context learning to estimate shape functions of a GAM in a single forward pass, representing a significant departure from the conventional iterative approaches to GAM fitting. Building on previous research applying in-context learning to tabular data, we exclusively use complex, synthetic data to train GAMformer, yet find it extrapolates well to real-world data. Our experiments show that GAMformer performs on par with other leading GAMs across various classification benchmarks while generating highly interpretable shape functions.
Elephants Never Forget: Memorization and Learning of Tabular Data in Large Language Models
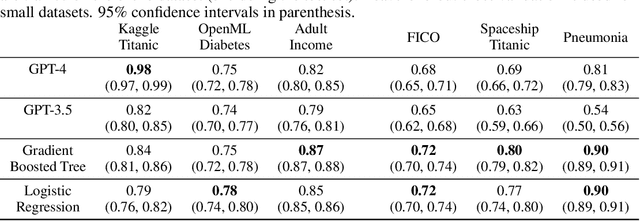
Apr 09, 2024While many have shown how Large Language Models (LLMs) can be applied to a diverse set of tasks, the critical issues of data contamination and memorization are often glossed over. In this work, we address this concern for tabular data. Specifically, we introduce a variety of different techniques to assess whether a language model has seen a tabular dataset during training. This investigation reveals that LLMs have memorized many popular tabular datasets verbatim. We then compare the few-shot learning performance of LLMs on datasets that were seen during training to the performance on datasets released after training. We find that LLMs perform better on datasets seen during training, indicating that memorization leads to overfitting. At the same time, LLMs show non-trivial performance on novel datasets and are surprisingly robust to data transformations. We then investigate the in-context statistical learning abilities of LLMs. Without fine-tuning, we find them to be limited. This suggests that much of the few-shot performance on novel datasets is due to the LLM's world knowledge. Overall, our results highlight the importance of testing whether an LLM has seen an evaluation dataset during pre-training. We make the exposure tests we developed available as the tabmemcheck Python package at https://github.com/interpretml/LLM-Tabular-Memorization-Checker
Elephants Never Forget: Testing Language Models for Memorization of Tabular Data
Mar 11, 2024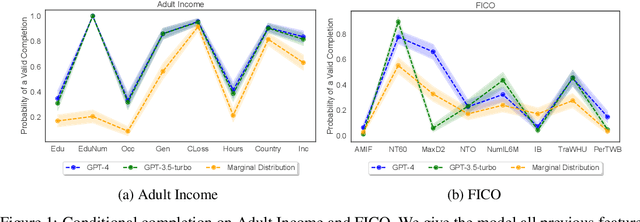
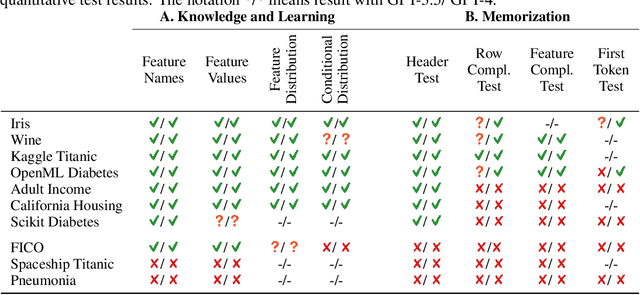
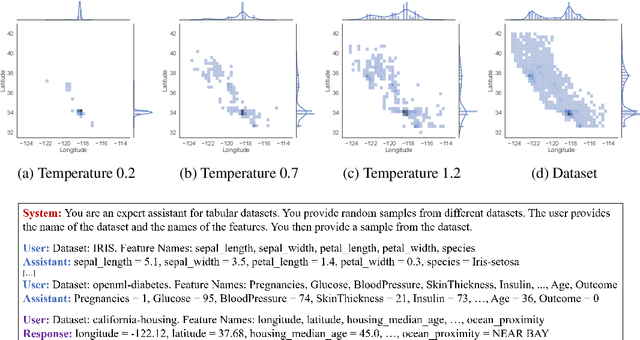
While many have shown how Large Language Models (LLMs) can be applied to a diverse set of tasks, the critical issues of data contamination and memorization are often glossed over. In this work, we address this concern for tabular data. Starting with simple qualitative tests for whether an LLM knows the names and values of features, we introduce a variety of different techniques to assess the degrees of contamination, including statistical tests for conditional distribution modeling and four tests that identify memorization. Our investigation reveals that LLMs are pre-trained on many popular tabular datasets. This exposure can lead to invalid performance evaluation on downstream tasks because the LLMs have, in effect, been fit to the test set. Interestingly, we also identify a regime where the language model reproduces important statistics of the data, but fails to reproduce the dataset verbatim. On these datasets, although seen during training, good performance on downstream tasks might not be due to overfitting. Our findings underscore the need for ensuring data integrity in machine learning tasks with LLMs. To facilitate future research, we release an open-source tool that can perform various tests for memorization \url{https://github.com/interpretml/LLM-Tabular-Memorization-Checker}.
Data Science with LLMs and Interpretable Models
Feb 22, 2024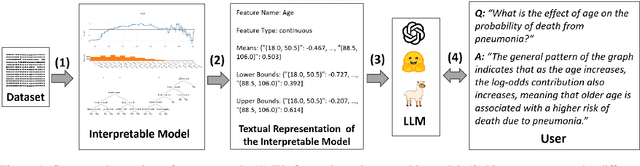
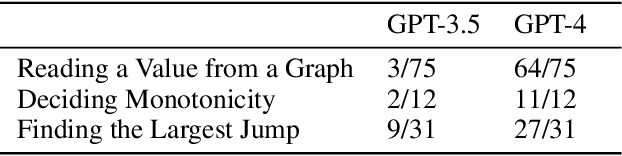


Recent years have seen important advances in the building of interpretable models, machine learning models that are designed to be easily understood by humans. In this work, we show that large language models (LLMs) are remarkably good at working with interpretable models, too. In particular, we show that LLMs can describe, interpret, and debug Generalized Additive Models (GAMs). Combining the flexibility of LLMs with the breadth of statistical patterns accurately described by GAMs enables dataset summarization, question answering, and model critique. LLMs can also improve the interaction between domain experts and interpretable models, and generate hypotheses about the underlying phenomenon. We release \url{https://github.com/interpretml/TalkToEBM} as an open-source LLM-GAM interface.
Rethinking Interpretability in the Era of Large Language Models
Jan 30, 2024

Interpretable machine learning has exploded as an area of interest over the last decade, sparked by the rise of increasingly large datasets and deep neural networks. Simultaneously, large language models (LLMs) have demonstrated remarkable capabilities across a wide array of tasks, offering a chance to rethink opportunities in interpretable machine learning. Notably, the capability to explain in natural language allows LLMs to expand the scale and complexity of patterns that can be given to a human. However, these new capabilities raise new challenges, such as hallucinated explanations and immense computational costs. In this position paper, we start by reviewing existing methods to evaluate the emerging field of LLM interpretation (both interpreting LLMs and using LLMs for explanation). We contend that, despite their limitations, LLMs hold the opportunity to redefine interpretability with a more ambitious scope across many applications, including in auditing LLMs themselves. We highlight two emerging research priorities for LLM interpretation: using LLMs to directly analyze new datasets and to generate interactive explanations.
Explaining high-dimensional text classifiers
Nov 22, 2023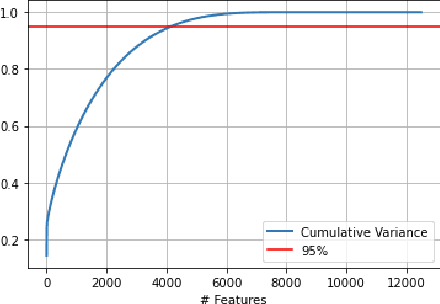

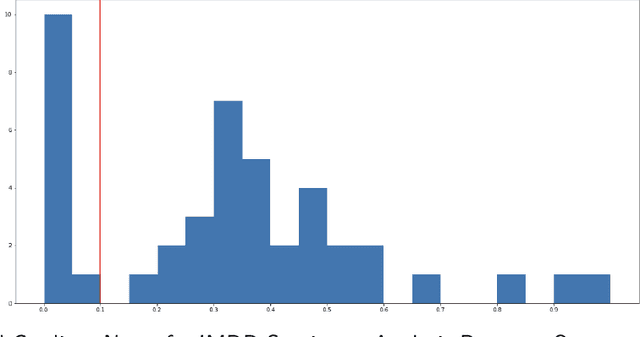

Explainability has become a valuable tool in the last few years, helping humans better understand AI-guided decisions. However, the classic explainability tools are sometimes quite limited when considering high-dimensional inputs and neural network classifiers. We present a new explainability method using theoretically proven high-dimensional properties in neural network classifiers. We present two usages of it: 1) On the classical sentiment analysis task for the IMDB reviews dataset, and 2) our Malware-Detection task for our PowerShell scripts dataset.
Interpretable Predictive Models to Understand Risk Factors for Maternal and Fetal Outcomes
Oct 16, 2023Although most pregnancies result in a good outcome, complications are not uncommon and can be associated with serious implications for mothers and babies. Predictive modeling has the potential to improve outcomes through better understanding of risk factors, heightened surveillance for high risk patients, and more timely and appropriate interventions, thereby helping obstetricians deliver better care. We identify and study the most important risk factors for four types of pregnancy complications: (i) severe maternal morbidity, (ii) shoulder dystocia, (iii) preterm preeclampsia, and (iv) antepartum stillbirth. We use an Explainable Boosting Machine (EBM), a high-accuracy glass-box learning method, for prediction and identification of important risk factors. We undertake external validation and perform an extensive robustness analysis of the EBM models. EBMs match the accuracy of other black-box ML methods such as deep neural networks and random forests, and outperform logistic regression, while being more interpretable. EBMs prove to be robust. The interpretability of the EBM models reveals surprising insights into the features contributing to risk (e.g. maternal height is the second most important feature for shoulder dystocia) and may have potential for clinical application in the prediction and prevention of serious complications in pregnancy.
LLMs Understand Glass-Box Models, Discover Surprises, and Suggest Repairs
Aug 07, 2023We show that large language models (LLMs) are remarkably good at working with interpretable models that decompose complex outcomes into univariate graph-represented components. By adopting a hierarchical approach to reasoning, LLMs can provide comprehensive model-level summaries without ever requiring the entire model to fit in context. This approach enables LLMs to apply their extensive background knowledge to automate common tasks in data science such as detecting anomalies that contradict prior knowledge, describing potential reasons for the anomalies, and suggesting repairs that would remove the anomalies. We use multiple examples in healthcare to demonstrate the utility of these new capabilities of LLMs, with particular emphasis on Generalized Additive Models (GAMs). Finally, we present the package $\texttt{TalkToEBM}$ as an open-source LLM-GAM interface.
Diagnosis Uncertain Models For Medical Risk Prediction
Jun 29, 2023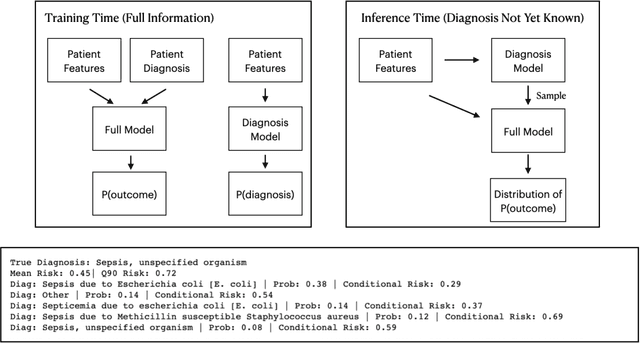
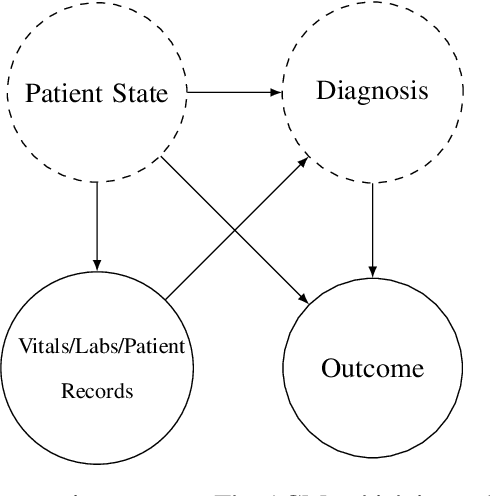
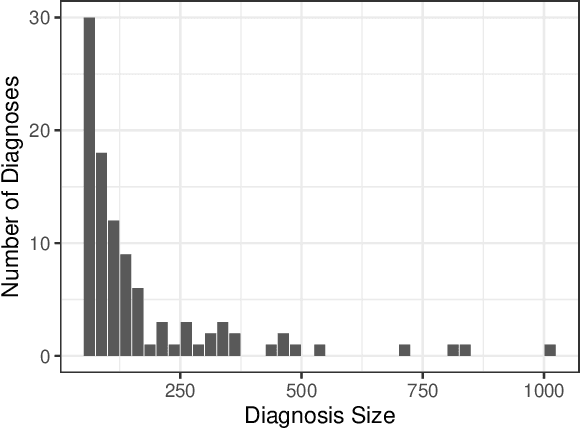
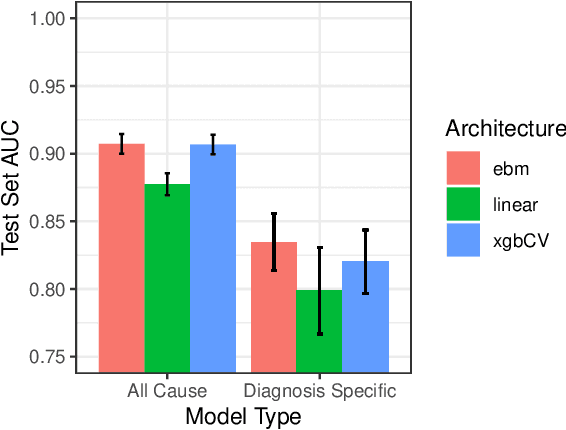
We consider a patient risk models which has access to patient features such as vital signs, lab values, and prior history but does not have access to a patient's diagnosis. For example, this occurs in a model deployed at intake time for triage purposes. We show that such `all-cause' risk models have good generalization across diagnoses but have a predictable failure mode. When the same lab/vital/history profiles can result from diagnoses with different risk profiles (e.g. E.coli vs. MRSA) the risk estimate is a probability weighted average of these two profiles. This leads to an under-estimation of risk for rare but highly risky diagnoses. We propose a fix for this problem by explicitly modeling the uncertainty in risk prediction coming from uncertainty in patient diagnoses. This gives practitioners an interpretable way to understand patient risk beyond a single risk number.
Extending Explainable Boosting Machines to Scientific Image Data
May 25, 2023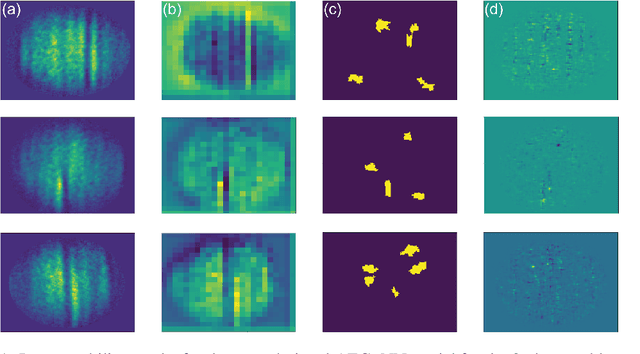
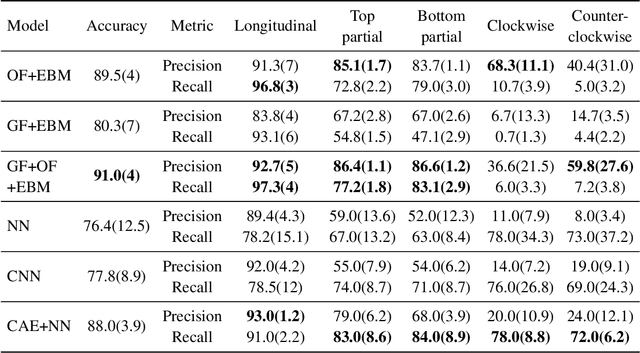
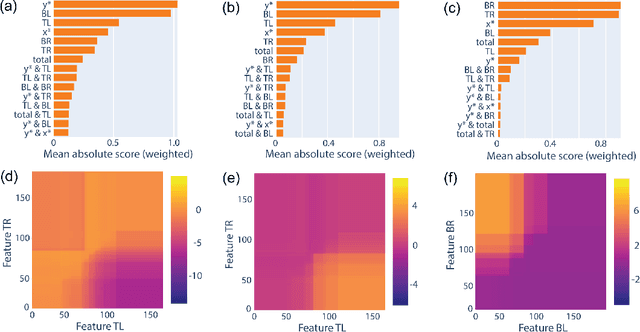
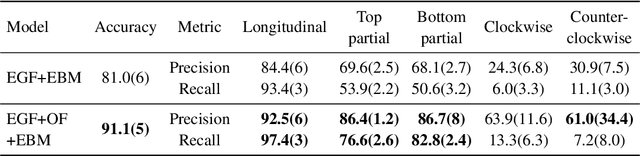
As the deployment of computer vision technology becomes increasingly common in applications of consequence such as medicine or science, the need for explanations of the system output has become a focus of great concern. Unfortunately, many state-of-the-art computer vision models are opaque, making their use challenging from an explanation standpoint, and current approaches to explaining these opaque models have stark limitations and have been the subject of serious criticism. In contrast, Explainable Boosting Machines (EBMs) are a class of models that are easy to interpret and achieve performance on par with the very best-performing models, however, to date EBMs have been limited solely to tabular data. Driven by the pressing need for interpretable models in science, we propose the use of EBMs for scientific image data. Inspired by an important application underpinning the development of quantum technologies, we apply EBMs to cold-atom soliton image data, and, in doing so, demonstrate EBMs for image data for the first time. To tabularize the image data we employ Gabor Wavelet Transform-based techniques that preserve the spatial structure of the data. We show that our approach provides better explanations than other state-of-the-art explainability methods for images.