 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLIVE: Online Low-Rank Incremental Learning for Efficient Adaptive Exoskeletons
Jun 03, 2026Wearable exoskeleton systems hold promise for restoring mobility in individuals with physical impairments, yet most existing controllers rely on static gait policies that lack the ability to adapt to dynamic real-world environments or individual user characteristics. We present \olive (\underline{O}nline \underline{L}ow-rank \underline{I}ncremental Learning for Efficient Adapti\underline{ve} Exoskeletons), a parameter-efficient online adaptation framework that continuously personalizes exoskeleton control during deployment. \olive decomposes the adaptive component of the control policy into a low-rank residual form~$\dW = \At\Bt^\top$ with rank~$r!\ll!\min(d,k)$, reducing online update cost from $\mathcal{O}(dk)$ to $\mathcal{O}(r(d{+}k))$ while preserving the stability of a pretrained base controller~$\Wz$. Parameters are updated via a reward-shaped policy gradient driven purely by on-body sensor feedback (EMG, IMU, vibration), eliminating dependence on offline reference trajectories. A gating mechanism modulates the strength of personalization based on contextual state, and a dynamic rank scheduler adapts the update dimensionality to terrain complexity -- allocating minimal capacity on simple flat terrain and expanding to higher-rank updates on demanding uneven surfaces -- enabling robust performance across diverse activities: flat walking, stair navigation, slopes, and uneven terrain. Experiments on the wearable platform demonstrate that \olive achieves +13, +22, and +15 percentage-point improvements in gait smoothness, effort reduction, and motion stability over the strongest baseline, converging within $\sim$1{,}800 walking steps at 7.4,ms end-to-end latency. Our code implementation is available at https://github.com/FastLM/OLIVE.
Selecting Feature Interactions for Generalized Additive Models by Distilling Foundation Models
Apr 14, 2026Identifying meaningful feature interactions is a central challenge in building accurate and interpretable models for tabular data. Generalized additive models (GAMs) have shown great success at modeling tabular data, but often rely on heuristic procedures to select interactions, potentially missing higher-order or context-dependent effects. To meet this challenge, we propose TabDistill, a method that leverages tabular foundation models and post-hoc distillation methods. Our key intuition is that tabular foundation models implicitly learn rich, adaptive feature dependencies through large-scale representation learning. Given a dataset, TabDistill first fits a tabular foundation model to the dataset, and then applies a post-hoc interaction attribution method to extract salient feature interactions from it. We evaluate these interactions by then using them as terms in a GAM. Across tasks, we find that interactions identified by TabDistill lead to consistent improvements in downstream GAMs' predictive performance. Our results suggest that tabular foundation models can serve as effective, data-driven guides for interaction discovery, bridging high-capacity models and interpretable additive frameworks.
MKA: Memory-Keyed Attention for Efficient Long-Context Reasoning
Mar 21, 2026As long-context language modeling becomes increasingly important, the cost of maintaining and attending to large Key/Value (KV) caches grows rapidly, becoming a major bottleneck in both training and inference. While prior works such as Multi-Query Attention (MQA) and Multi-Latent Attention (MLA) reduce memory by sharing or compressing KV features, they often trade off representation quality or incur runtime overhead. We propose Memory-Keyed Attention (MKA), a hierarchical attention mechanism that integrates multi-level KV caches (local, session, and long-term) and learns to route attention across them dynamically. We further introduce Route-Fused MKA (FastMKA), a broadcast-routed variant that fuses memory sources before attention computation for improved efficiency. Experiments on different sequence lengths show that FastMKA achieves a favorable accuracy-efficiency trade-off: comparable perplexity to MLA while achieving up to 5x faster training throughput and 1.8x lower evaluation latency. These results highlight MKA as a practical and extensible framework for efficient long-context attention.
AdaCorrection: Adaptive Offset Cache Correction for Accurate Diffusion Transformers
Feb 13, 2026Diffusion Transformers (DiTs) achieve state-of-the-art performance in high-fidelity image and video generation but suffer from expensive inference due to their iterative denoising structure. While prior methods accelerate sampling by caching intermediate features, they rely on static reuse schedules or coarse-grained heuristics, which often lead to temporal drift and cache misalignment that significantly degrade generation quality. We introduce \textbf{AdaCorrection}, an adaptive offset cache correction framework that maintains high generation fidelity while enabling efficient cache reuse across Transformer layers during diffusion inference. At each timestep, AdaCorrection estimates cache validity with lightweight spatio-temporal signals and adaptively blends cached and fresh activations. This correction is computed on-the-fly without additional supervision or retraining. Our approach achieves strong generation quality with minimal computational overhead, maintaining near-original FID while providing moderate acceleration. Experiments on image and video diffusion benchmarks show that AdaCorrection consistently improves generation performance.
FastCache: Fast Caching for Diffusion Transformer Through Learnable Linear Approximation
May 26, 2025Diffusion Transformers (DiT) are powerful generative models but remain computationally intensive due to their iterative structure and deep transformer stacks. To alleviate this inefficiency, we propose FastCache, a hidden-state-level caching and compression framework that accelerates DiT inference by exploiting redundancy within the model's internal representations. FastCache introduces a dual strategy: (1) a spatial-aware token selection mechanism that adaptively filters redundant tokens based on hidden state saliency, and (2) a transformer-level cache that reuses latent activations across timesteps when changes are statistically insignificant. These modules work jointly to reduce unnecessary computation while preserving generation fidelity through learnable linear approximation. Theoretical analysis shows that FastCache maintains bounded approximation error under a hypothesis-testing-based decision rule. Empirical evaluations across multiple DiT variants demonstrate substantial reductions in latency and memory usage, with best generation output quality compared to other cache methods, as measured by FID and t-FID. Code implementation of FastCache is available on GitHub at https://github.com/NoakLiu/FastCache-xDiT.
Patient-Specific Models of Treatment Effects Explain Heterogeneity in Tuberculosis
Nov 16, 2024
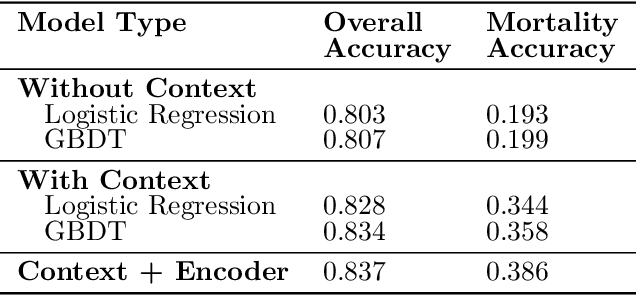
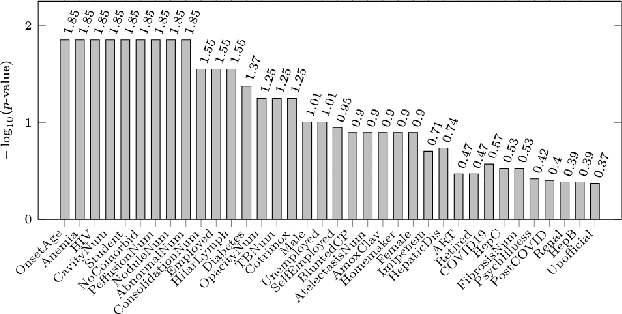
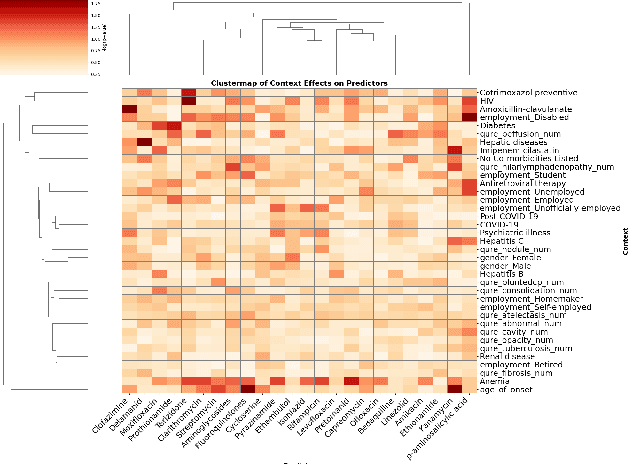
Tuberculosis (TB) is a major global health challenge, and is compounded by co-morbidities such as HIV, diabetes, and anemia, which complicate treatment outcomes and contribute to heterogeneous patient responses. Traditional models of TB often overlook this heterogeneity by focusing on broad, pre-defined patient groups, thereby missing the nuanced effects of individual patient contexts. We propose moving beyond coarse subgroup analyses by using contextualized modeling, a multi-task learning approach that encodes patient context into personalized models of treatment effects, revealing patient-specific treatment benefits. Applied to the TB Portals dataset with multi-modal measurements for over 3,000 TB patients, our model reveals structured interactions between co-morbidities, treatments, and patient outcomes, identifying anemia, age of onset, and HIV as influential for treatment efficacy. By enhancing predictive accuracy in heterogeneous populations and providing patient-specific insights, contextualized models promise to enable new approaches to personalized treatment.
Data Science with LLMs and Interpretable Models
Feb 22, 2024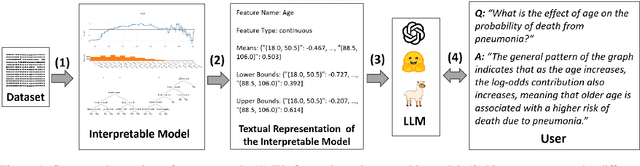
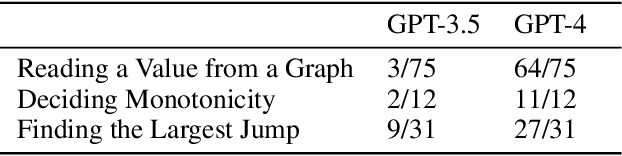


Recent years have seen important advances in the building of interpretable models, machine learning models that are designed to be easily understood by humans. In this work, we show that large language models (LLMs) are remarkably good at working with interpretable models, too. In particular, we show that LLMs can describe, interpret, and debug Generalized Additive Models (GAMs). Combining the flexibility of LLMs with the breadth of statistical patterns accurately described by GAMs enables dataset summarization, question answering, and model critique. LLMs can also improve the interaction between domain experts and interpretable models, and generate hypotheses about the underlying phenomenon. We release \url{https://github.com/interpretml/TalkToEBM} as an open-source LLM-GAM interface.
Executive Function: A Contrastive Value Policy for Resampling and Relabeling Perceptions via Hindsight Summarization?
Apr 27, 2022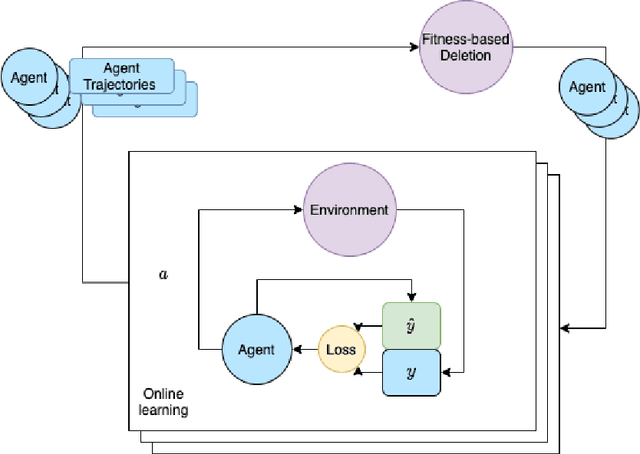
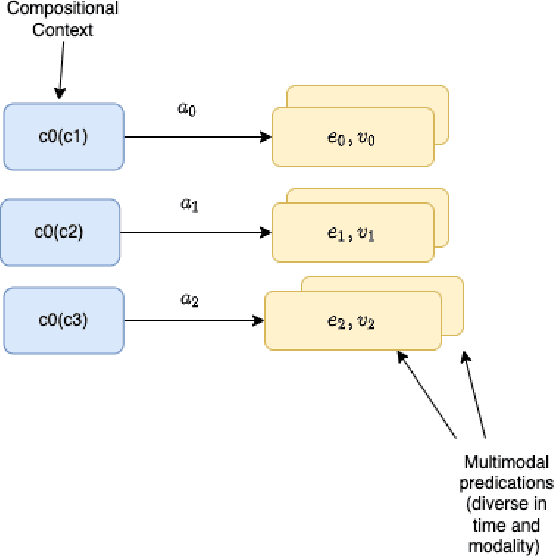
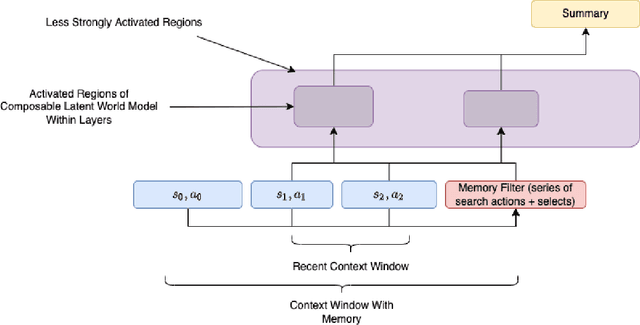
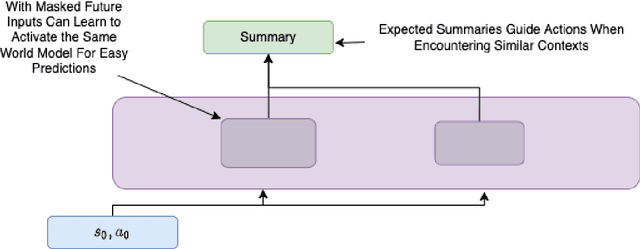
We develop the few-shot continual learning task from first principles and hypothesize an evolutionary motivation and mechanism of action for executive function as a contrastive value policy which resamples and relabels perception data via hindsight summarization to minimize attended prediction error, similar to an online prompt engineering problem. This is made feasible by the use of a memory policy and a pretrained network with inductive biases for a grammar of learning and is trained to maximize evolutionary survival. We show how this model of executive function can be used to implement hypothesis testing as a stream of consciousness and may explain observations of human few-shot learning and neuroanatomy.
NOTMAD: Estimating Bayesian Networks with Sample-Specific Structures and Parameters
Nov 01, 2021



Context-specific Bayesian networks (i.e. directed acyclic graphs, DAGs) identify context-dependent relationships between variables, but the non-convexity induced by the acyclicity requirement makes it difficult to share information between context-specific estimators (e.g. with graph generator functions). For this reason, existing methods for inferring context-specific Bayesian networks have favored breaking datasets into subsamples, limiting statistical power and resolution, and preventing the use of multidimensional and latent contexts. To overcome this challenge, we propose NOTEARS-optimized Mixtures of Archetypal DAGs (NOTMAD). NOTMAD models context-specific Bayesian networks as the output of a function which learns to mix archetypal networks according to sample context. The archetypal networks are estimated jointly with the context-specific networks and do not require any prior knowledge. We encode the acyclicity constraint as a smooth regularization loss which is back-propagated to the mixing function; in this way, NOTMAD shares information between context-specific acyclic graphs, enabling the estimation of Bayesian network structures and parameters at even single-sample resolution. We demonstrate the utility of NOTMAD and sample-specific network inference through analysis and experiments, including patient-specific gene expression networks which correspond to morphological variation in cancer.
How Interpretable and Trustworthy are GAMs?
Jun 11, 2020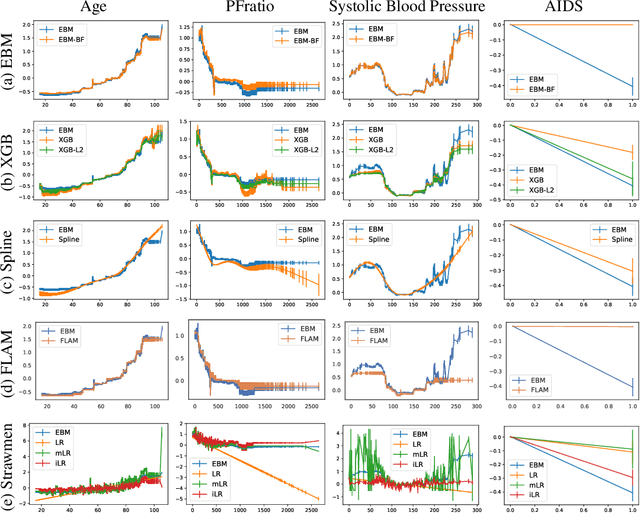
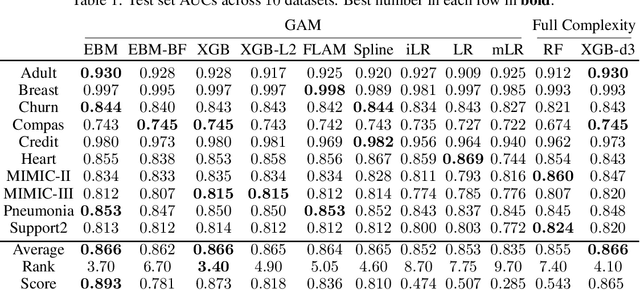

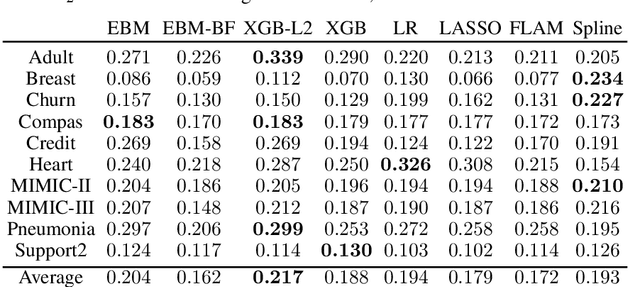
Generalized additive models (GAMs) have become a leading model class for data bias discovery and model auditing. However, there are a variety of algorithms for training GAMs, and these do not always learn the same things. Statisticians originally used splines to train GAMs, but more recently GAMs are being trained with boosted decision trees. It is unclear which GAM model(s) to believe, particularly when their explanations are contradictory. In this paper, we investigate a variety of different GAM algorithms both qualitatively and quantitatively on real and simulated datasets. Our results suggest that inductive bias plays a crucial role in model explanations and tree-based GAMs are to be recommended for the kinds of problems and dataset sizes we worked with.