 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Contrastive Distillation Is a Sample-Efficient Self-Supervised Loss Policy for Transfer Learning
Dec 21, 2022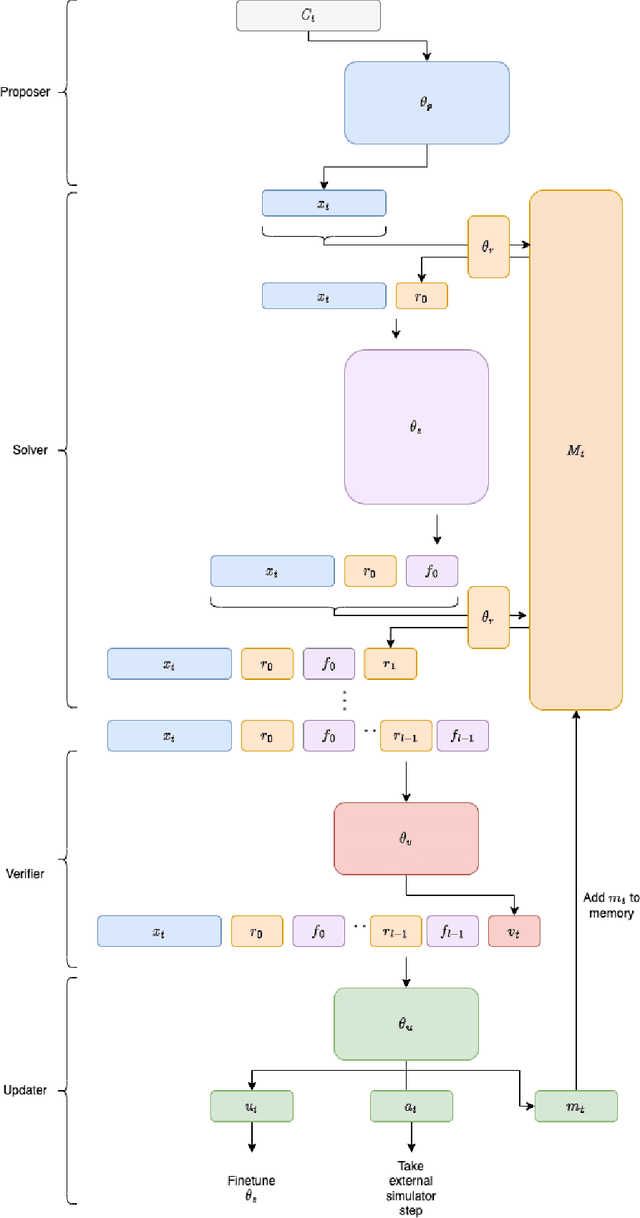

Traditional approaches to RL have focused on learning decision policies directly from episodic decisions, while slowly and implicitly learning the semantics of compositional representations needed for generalization. While some approaches have been adopted to refine representations via auxiliary self-supervised losses while simultaneously learning decision policies, learning compositional representations from hand-designed and context-independent self-supervised losses (multi-view) still adapts relatively slowly to the real world, which contains many non-IID subspaces requiring rapid distribution shift in both time and spatial attention patterns at varying levels of abstraction. In contrast, supervised language model cascades have shown the flexibility to adapt to many diverse manifolds, and hints of self-learning needed for autonomous task transfer. However, to date, transfer methods for language models like few-shot learning and fine-tuning still require human supervision and transfer learning using self-learning methods has been underexplored. We propose a self-supervised loss policy called contrastive distillation which manifests latent variables with high mutual information with both source and target tasks from weights to tokens. We show how this outperforms common methods of transfer learning and suggests a useful design axis of trading off compute for generalizability for online transfer. Contrastive distillation is improved through sampling from memory and suggests a simple algorithm for more efficiently sampling negative examples for contrastive losses than random sampling.
Executive Function: A Contrastive Value Policy for Resampling and Relabeling Perceptions via Hindsight Summarization?
Apr 27, 2022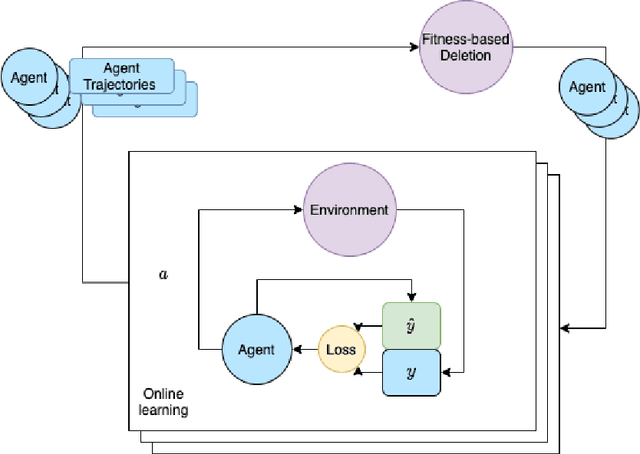
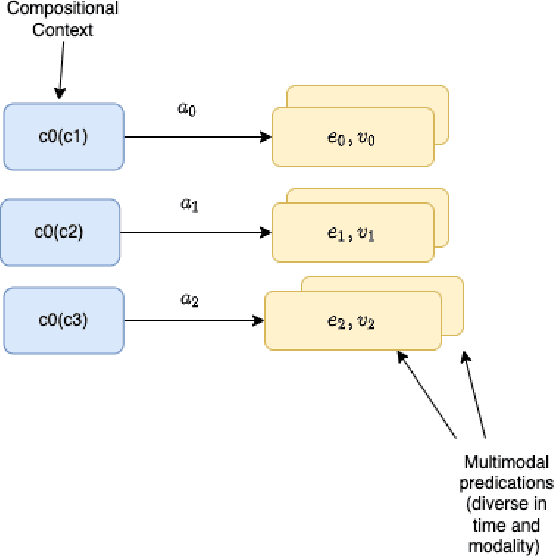
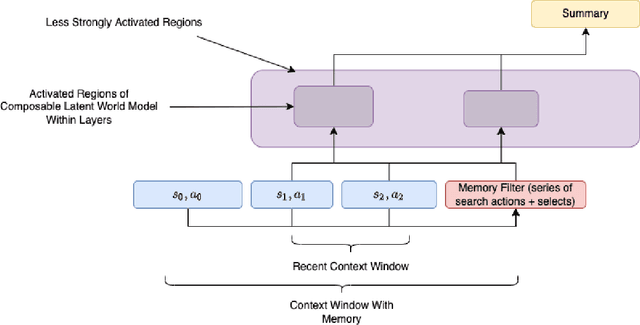
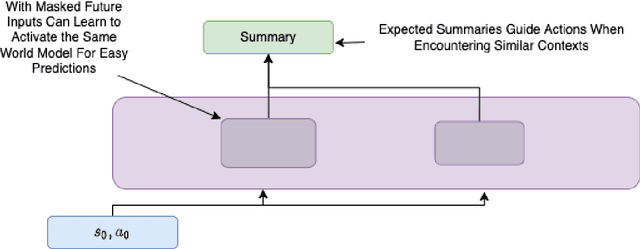
We develop the few-shot continual learning task from first principles and hypothesize an evolutionary motivation and mechanism of action for executive function as a contrastive value policy which resamples and relabels perception data via hindsight summarization to minimize attended prediction error, similar to an online prompt engineering problem. This is made feasible by the use of a memory policy and a pretrained network with inductive biases for a grammar of learning and is trained to maximize evolutionary survival. We show how this model of executive function can be used to implement hypothesis testing as a stream of consciousness and may explain observations of human few-shot learning and neuroanatomy.
An End-to-End Architecture for Keyword Spotting and Voice Activity Detection
Nov 28, 2016


We propose a single neural network architecture for two tasks: on-line keyword spotting and voice activity detection. We develop novel inference algorithms for an end-to-end Recurrent Neural Network trained with the Connectionist Temporal Classification loss function which allow our model to achieve high accuracy on both keyword spotting and voice activity detection without retraining. In contrast to prior voice activity detection models, our architecture does not require aligned training data and uses the same parameters as the keyword spotting model. This allows us to deploy a high quality voice activity detector with no additional memory or maintenance requirements.