 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLIP: Adapting Vision-Language models with Hypernetworks
Dec 21, 2024Self-supervised vision-language models trained with contrastive objectives form the basis of current state-of-the-art methods in AI vision tasks. The success of these models is a direct consequence of the huge web-scale datasets used to train them, but they require correspondingly large vision components to properly learn powerful and general representations from such a broad data domain. This poses a challenge for deploying large vision-language models, especially in resource-constrained environments. To address this, we propose an alternate vision-language architecture, called HyperCLIP, that uses a small image encoder along with a hypernetwork that dynamically adapts image encoder weights to each new set of text inputs. All three components of the model (hypernetwork, image encoder, and text encoder) are pre-trained jointly end-to-end, and with a trained HyperCLIP model, we can generate new zero-shot deployment-friendly image classifiers for any task with a single forward pass through the text encoder and hypernetwork. HyperCLIP increases the zero-shot accuracy of SigLIP trained models with small image encoders by up to 3% on ImageNet and 5% on CIFAR-100 with minimal training throughput overhead.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
AcceleratedLiNGAM: Learning Causal DAGs at the speed of GPUs
Mar 06, 2024Existing causal discovery methods based on combinatorial optimization or search are slow, prohibiting their application on large-scale datasets. In response, more recent methods attempt to address this limitation by formulating causal discovery as structure learning with continuous optimization but such approaches thus far provide no statistical guarantees. In this paper, we show that by efficiently parallelizing existing causal discovery methods, we can in fact scale them to thousands of dimensions, making them practical for substantially larger-scale problems. In particular, we parallelize the LiNGAM method, which is quadratic in the number of variables, obtaining up to a 32-fold speed-up on benchmark datasets when compared with existing sequential implementations. Specifically, we focus on the causal ordering subprocedure in DirectLiNGAM and implement GPU kernels to accelerate it. This allows us to apply DirectLiNGAM to causal inference on large-scale gene expression data with genetic interventions yielding competitive results compared with specialized continuous optimization methods, and Var-LiNGAM for causal discovery on U.S. stock data.
Understanding prompt engineering may not require rethinking generalization
Oct 06, 2023
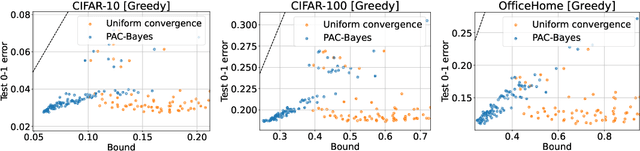
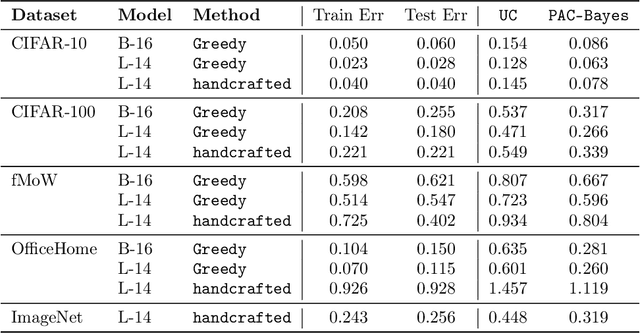
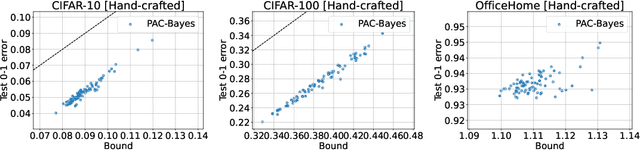
Zero-shot learning in prompted vision-language models, the practice of crafting prompts to build classifiers without an explicit training process, has achieved impressive performance in many settings. This success presents a seemingly surprising observation: these methods suffer relatively little from overfitting, i.e., when a prompt is manually engineered to achieve low error on a given training set (thus rendering the method no longer actually zero-shot), the approach still performs well on held-out test data. In this paper, we show that we can explain such performance well via recourse to classical PAC-Bayes bounds. Specifically, we show that the discrete nature of prompts, combined with a PAC-Bayes prior given by a language model, results in generalization bounds that are remarkably tight by the standards of the literature: for instance, the generalization bound of an ImageNet classifier is often within a few percentage points of the true test error. We demonstrate empirically that this holds for existing handcrafted prompts and prompts generated through simple greedy search. Furthermore, the resulting bound is well-suited for model selection: the models with the best bound typically also have the best test performance. This work thus provides a possible justification for the widespread practice of prompt engineering, even if it seems that such methods could potentially overfit the training data.
Partial Identifiability for Domain Adaptation
Jun 10, 2023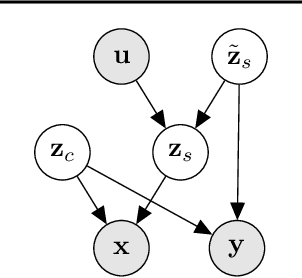

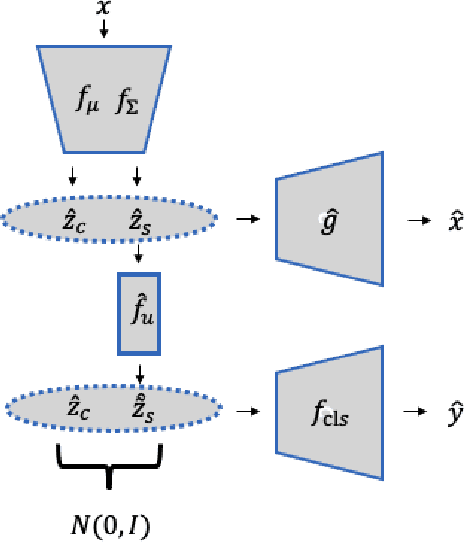

Unsupervised domain adaptation is critical to many real-world applications where label information is unavailable in the target domain. In general, without further assumptions, the joint distribution of the features and the label is not identifiable in the target domain. To address this issue, we rely on the property of minimal changes of causal mechanisms across domains to minimize unnecessary influences of distribution shifts. To encode this property, we first formulate the data-generating process using a latent variable model with two partitioned latent subspaces: invariant components whose distributions stay the same across domains and sparse changing components that vary across domains. We further constrain the domain shift to have a restrictive influence on the changing components. Under mild conditions, we show that the latent variables are partially identifiable, from which it follows that the joint distribution of data and labels in the target domain is also identifiable. Given the theoretical insights, we propose a practical domain adaptation framework called iMSDA. Extensive experimental results reveal that iMSDA outperforms state-of-the-art domain adaptation algorithms on benchmark datasets, demonstrating the effectiveness of our framework.
Pattern Detection in the Activation Space for Identifying Synthesized Content
May 27, 2021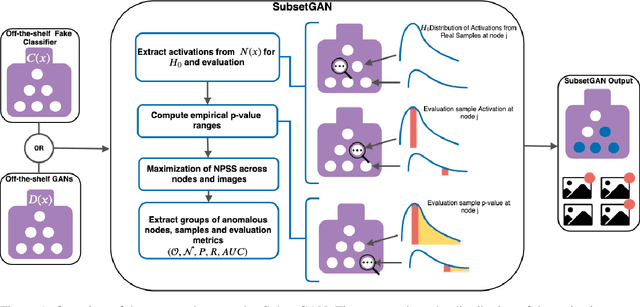
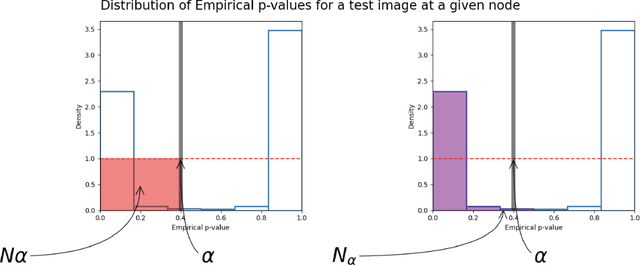

Generative Adversarial Networks (GANs) have recently achieved unprecedented success in photo-realistic image synthesis from low-dimensional random noise. The ability to synthesize high-quality content at a large scale brings potential risks as the generated samples may lead to misinformation that can create severe social, political, health, and business hazards. We propose SubsetGAN to identify generated content by detecting a subset of anomalous node-activations in the inner layers of pre-trained neural networks. These nodes, as a group, maximize a non-parametric measure of divergence away from the expected distribution of activations created from real data. This enable us to identify synthesised images without prior knowledge of their distribution. SubsetGAN efficiently scores subsets of nodes and returns the group of nodes within the pre-trained classifier that contributed to the maximum score. The classifier can be a general fake classifier trained over samples from multiple sources or the discriminator network from different GANs. Our approach shows consistently higher detection power than existing detection methods across several state-of-the-art GANs (PGGAN, StarGAN, and CycleGAN) and over different proportions of generated content.
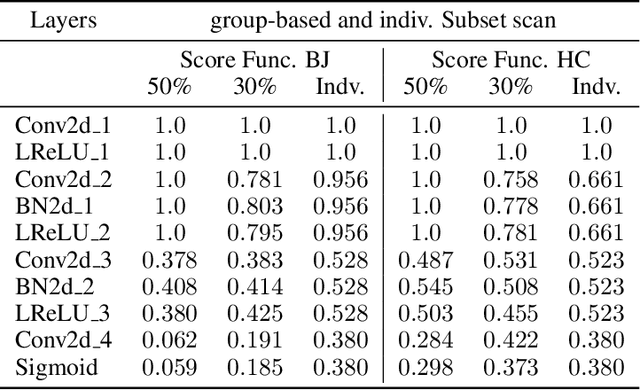
Towards creativity characterization of generative models via group-based subset scanning
Apr 01, 2021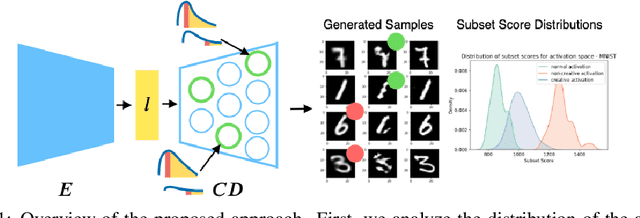
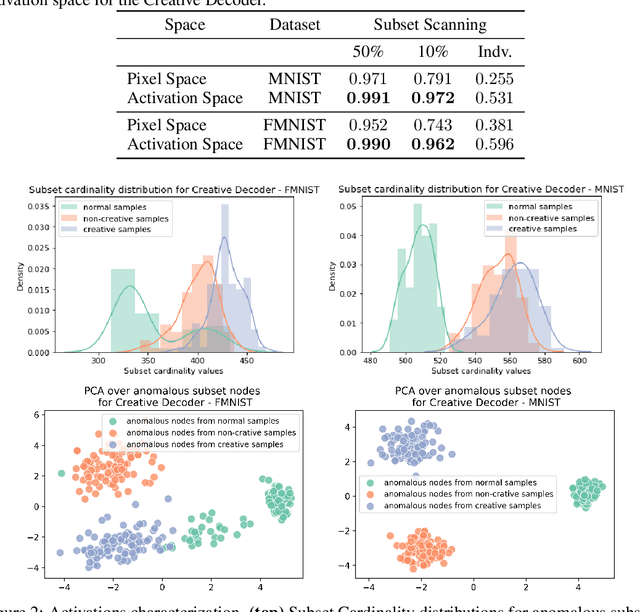
Deep generative models, such as Variational Autoencoders (VAEs), have been employed widely in computational creativity research. However, such models discourage out-of-distribution generation to avoid spurious sample generation, limiting their creativity. Thus, incorporating research on human creativity into generative deep learning techniques presents an opportunity to make their outputs more compelling and human-like. As we see the emergence of generative models directed to creativity research, a need for machine learning-based surrogate metrics to characterize creative output from these models is imperative. We propose group-based subset scanning to quantify, detect, and characterize creative processes by detecting a subset of anomalous node-activations in the hidden layers of generative models. Our experiments on original, typically decoded, and "creatively decoded" (Das et al 2020) image datasets reveal that the proposed subset scores distribution is more useful for detecting creative processes in the activation space rather than the pixel space. Further, we found that creative samples generate larger subsets of anomalies than normal or non-creative samples across datasets. The node activations highlighted during the creative decoding process are different from those responsible for normal sample generation.
Identifying Audio Adversarial Examples via Anomalous Pattern Detection
Feb 13, 2020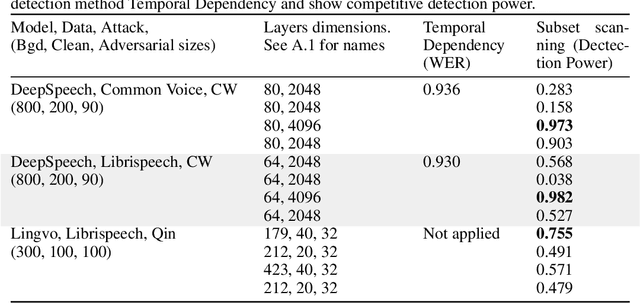
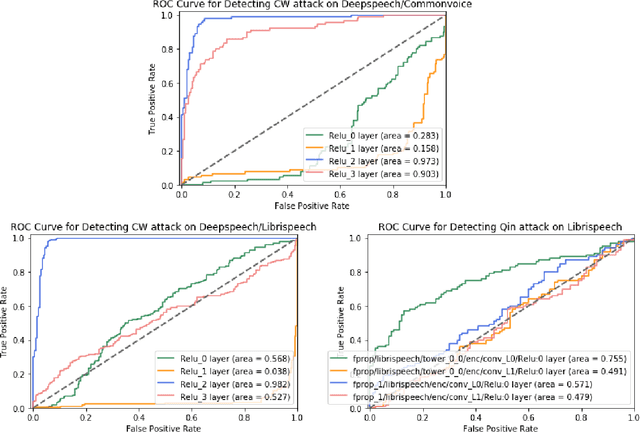
Audio processing models based on deep neural networks are susceptible to adversarial attacks even when the adversarial audio waveform is 99.9% similar to a benign sample. Given the wide application of DNN-based audio recognition systems, detecting the presence of adversarial examples is of high practical relevance. By applying anomalous pattern detection techniques in the activation space of these models, we show that 2 of the recent and current state-of-the-art adversarial attacks on audio processing systems systematically lead to higher-than-expected activation at some subset of nodes and we can detect these with up to an AUC of 0.98 with no degradation in performance on benign samples.
Characterizing the hyper-parameter space of LSTM language models for mixed context applications
Dec 08, 2017



Applying state of the art deep learning models to novel real world datasets gives a practical evaluation of the generalizability of these models. Of importance in this process is how sensitive the hyper parameters of such models are to novel datasets as this would affect the reproducibility of a model. We present work to characterize the hyper parameter space of an LSTM for language modeling on a code-mixed corpus. We observe that the evaluated model shows minimal sensitivity to our novel dataset bar a few hyper parameters.