 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Representation of the Activation Space in Deep Neural Networks
Dec 13, 2023
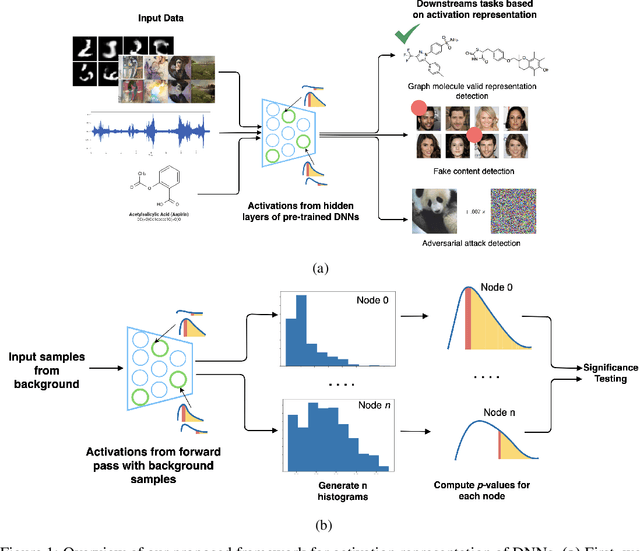

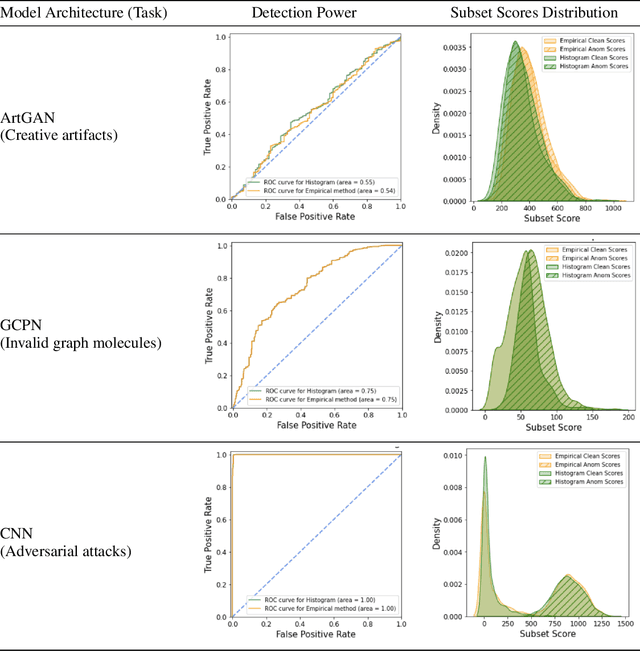
The representations of the activation space of deep neural networks (DNNs) are widely utilized for tasks like natural language processing, anomaly detection and speech recognition. Due to the diverse nature of these tasks and the large size of DNNs, an efficient and task-independent representation of activations becomes crucial. Empirical p-values have been used to quantify the relative strength of an observed node activation compared to activations created by already-known inputs. Nonetheless, keeping raw data for these calculations increases memory resource consumption and raises privacy concerns. To this end, we propose a model-agnostic framework for creating representations of activations in DNNs using node-specific histograms to compute p-values of observed activations without retaining already-known inputs. Our proposed approach demonstrates promising potential when validated with multiple network architectures across various downstream tasks and compared with the kernel density estimates and brute-force empirical baselines. In addition, the framework reduces memory usage by 30% with up to 4 times faster p-value computing time while maintaining state of-the-art detection power in downstream tasks such as the detection of adversarial attacks and synthesized content. Moreover, as we do not persist raw data at inference time, we could potentially reduce susceptibility to attacks and privacy issues.
Auditing Predictive Models for Intersectional Biases
Jun 22, 2023
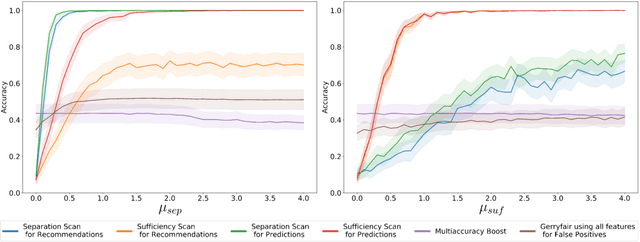

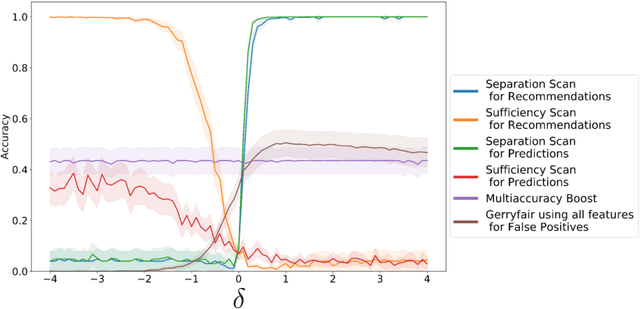
Predictive models that satisfy group fairness criteria in aggregate for members of a protected class, but do not guarantee subgroup fairness, could produce biased predictions for individuals at the intersection of two or more protected classes. To address this risk, we propose Conditional Bias Scan (CBS), a flexible auditing framework for detecting intersectional biases in classification models. CBS identifies the subgroup for which there is the most significant bias against the protected class, as compared to the equivalent subgroup in the non-protected class, and can incorporate multiple commonly used fairness definitions for both probabilistic and binarized predictions. We show that this methodology can detect previously unidentified intersectional and contextual biases in the COMPAS pre-trial risk assessment tool and has higher bias detection power compared to similar methods that audit for subgroup fairness.
Insufficiently Justified Disparate Impact: A New Criterion for Subgroup Fairness
Jun 19, 2023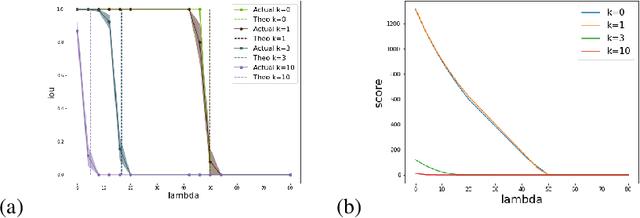

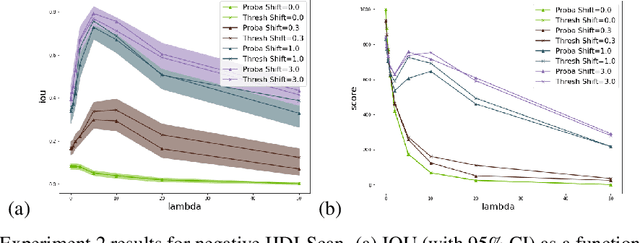

In this paper, we develop a new criterion, "insufficiently justified disparate impact" (IJDI), for assessing whether recommendations (binarized predictions) made by an algorithmic decision support tool are fair. Our novel, utility-based IJDI criterion evaluates false positive and false negative error rate imbalances, identifying statistically significant disparities between groups which are present even when adjusting for group-level differences in base rates. We describe a novel IJDI-Scan approach which can efficiently identify the intersectional subpopulations, defined across multiple observed attributes of the data, with the most significant IJDI. To evaluate IJDI-Scan's performance, we conduct experiments on both simulated and real-world data, including recidivism risk assessment and credit scoring. Further, we implement and evaluate approaches to mitigating IJDI for the detected subpopulations in these domains.
Provable Detection of Propagating Sampling Bias in Prediction Models
Feb 13, 2023With an increased focus on incorporating fairness in machine learning models, it becomes imperative not only to assess and mitigate bias at each stage of the machine learning pipeline but also to understand the downstream impacts of bias across stages. Here we consider a general, but realistic, scenario in which a predictive model is learned from (potentially biased) training data, and model predictions are assessed post-hoc for fairness by some auditing method. We provide a theoretical analysis of how a specific form of data bias, differential sampling bias, propagates from the data stage to the prediction stage. Unlike prior work, we evaluate the downstream impacts of data biases quantitatively rather than qualitatively and prove theoretical guarantees for detection. Under reasonable assumptions, we quantify how the amount of bias in the model predictions varies as a function of the amount of differential sampling bias in the data, and at what point this bias becomes provably detectable by the auditor. Through experiments on two criminal justice datasets -- the well-known COMPAS dataset and historical data from NYPD's stop and frisk policy -- we demonstrate that the theoretical results hold in practice even when our assumptions are relaxed.
Pattern Detection in the Activation Space for Identifying Synthesized Content
May 27, 2021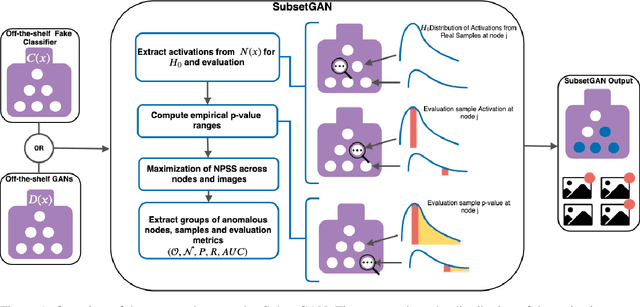
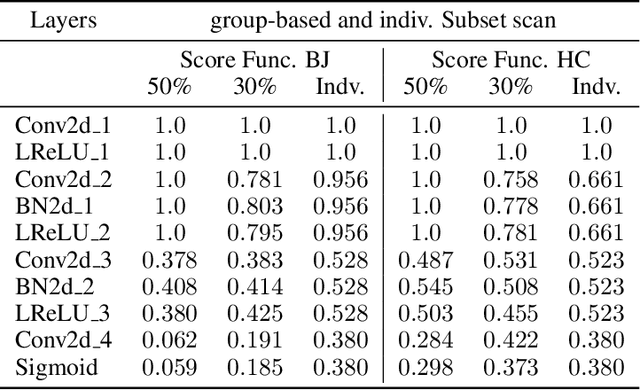
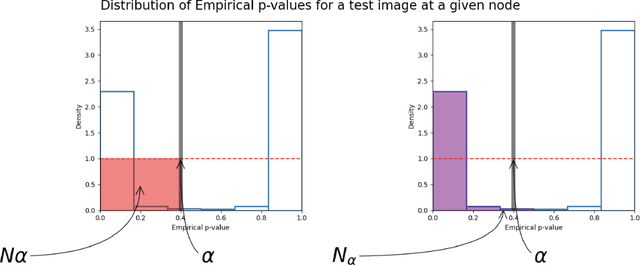

Generative Adversarial Networks (GANs) have recently achieved unprecedented success in photo-realistic image synthesis from low-dimensional random noise. The ability to synthesize high-quality content at a large scale brings potential risks as the generated samples may lead to misinformation that can create severe social, political, health, and business hazards. We propose SubsetGAN to identify generated content by detecting a subset of anomalous node-activations in the inner layers of pre-trained neural networks. These nodes, as a group, maximize a non-parametric measure of divergence away from the expected distribution of activations created from real data. This enable us to identify synthesised images without prior knowledge of their distribution. SubsetGAN efficiently scores subsets of nodes and returns the group of nodes within the pre-trained classifier that contributed to the maximum score. The classifier can be a general fake classifier trained over samples from multiple sources or the discriminator network from different GANs. Our approach shows consistently higher detection power than existing detection methods across several state-of-the-art GANs (PGGAN, StarGAN, and CycleGAN) and over different proportions of generated content.
Achieving Reliable Causal Inference with Data-Mined Variables: A Random Forest Approach to the Measurement Error Problem
Dec 19, 2020Combining machine learning with econometric analysis is becoming increasingly prevalent in both research and practice. A common empirical strategy involves the application of predictive modeling techniques to 'mine' variables of interest from available data, followed by the inclusion of those variables into an econometric framework, with the objective of estimating causal effects. Recent work highlights that, because the predictions from machine learning models are inevitably imperfect, econometric analyses based on the predicted variables are likely to suffer from bias due to measurement error. We propose a novel approach to mitigate these biases, leveraging the ensemble learning technique known as the random forest. We propose employing random forest not just for prediction, but also for generating instrumental variables to address the measurement error embedded in the prediction. The random forest algorithm performs best when comprised of a set of trees that are individually accurate in their predictions, yet which also make 'different' mistakes, i.e., have weakly correlated prediction errors. A key observation is that these properties are closely related to the relevance and exclusion requirements of valid instrumental variables. We design a data-driven procedure to select tuples of individual trees from a random forest, in which one tree serves as the endogenous covariate and the other trees serve as its instruments. Simulation experiments demonstrate the efficacy of the proposed approach in mitigating estimation biases and its superior performance over three alternative methods for bias correction.
Efficient Discovery of Heterogeneous Treatment Effects in Randomized Experiments via Anomalous Pattern Detection
Jun 07, 2018
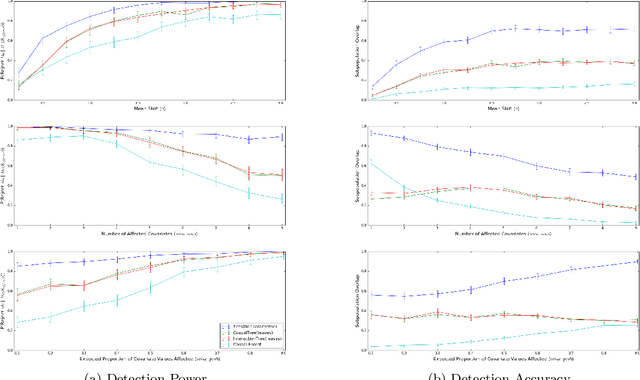

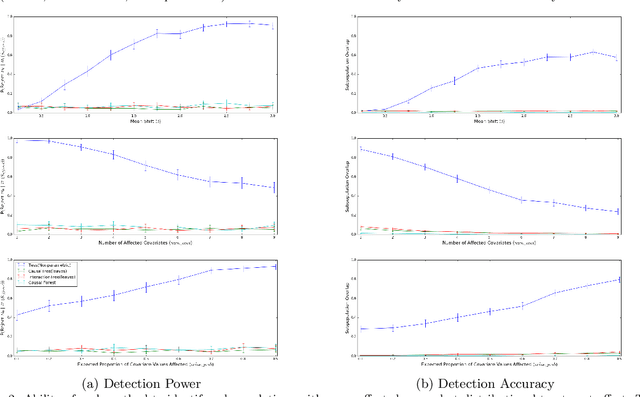
In the recent literature on estimating heterogeneous treatment effects, each proposed method makes its own set of restrictive assumptions about the intervention's effects and which subpopulations to explicitly estimate. Moreover, the majority of the literature provides no mechanism to identify which subpopulations are the most affected--beyond manual inspection--and provides little guarantee on the correctness of the identified subpopulations. Therefore, we propose Treatment Effect Subset Scan (TESS), a new method for discovering which subpopulation in a randomized experiment is most significantly affected by a treatment. We frame this challenge as a pattern detection problem where we efficiently maximize a nonparametric scan statistic over subpopulations. Furthermore, we identify the subpopulation which experiences the largest distributional change as a result of the intervention, while making minimal assumptions about the intervention's effects or the underlying data generating process. In addition to the algorithm, we demonstrate that the asymptotic Type I and II error can be controlled, and provide sufficient conditions for detection consistency--i.e., exact identification of the affected subpopulation. Finally, we validate the efficacy of the method by discovering heterogeneous treatment effects in simulations and in real-world data from a well-known program evaluation study.
Gaussian Process Subset Scanning for Anomalous Pattern Detection in Non-iid Data
Apr 04, 2018

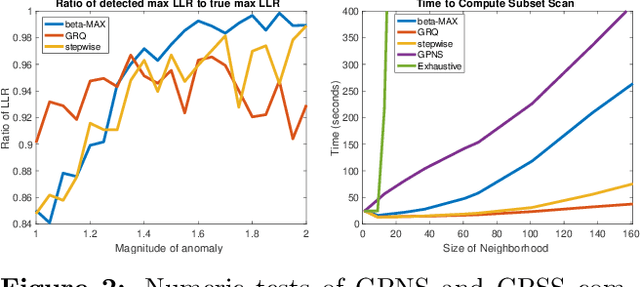
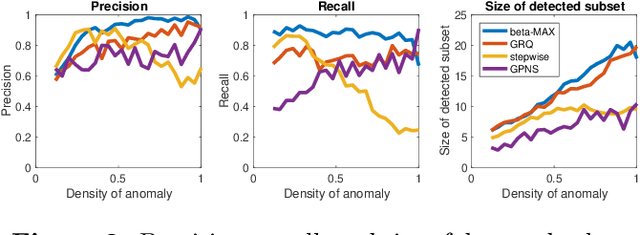
Identifying anomalous patterns in real-world data is essential for understanding where, when, and how systems deviate from their expected dynamics. Yet methods that separately consider the anomalousness of each individual data point have low detection power for subtle, emerging irregularities. Additionally, recent detection techniques based on subset scanning make strong independence assumptions and suffer degraded performance in correlated data. We introduce methods for identifying anomalous patterns in non-iid data by combining Gaussian processes with novel log-likelihood ratio statistic and subset scanning techniques. Our approaches are powerful, interpretable, and can integrate information across multiple data streams. We illustrate their performance on numeric simulations and three open source spatiotemporal datasets of opioid overdose deaths, 311 calls, and storm reports.