 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-agnostic and Multi-level Evaluation of Generative Models
Jan 20, 2023



While the capabilities of generative models heavily improved in different domains (images, text, graphs, molecules, etc.), their evaluation metrics largely remain based on simplified quantities or manual inspection with limited practicality. To this end, we propose a framework for Multi-level Performance Evaluation of Generative mOdels (MPEGO), which could be employed across different domains. MPEGO aims to quantify generation performance hierarchically, starting from a sub-feature-based low-level evaluation to a global features-based high-level evaluation. MPEGO offers great customizability as the employed features are entirely user-driven and can thus be highly domain/problem-specific while being arbitrarily complex (e.g., outcomes of experimental procedures). We validate MPEGO using multiple generative models across several datasets from the material discovery domain. An ablation study is conducted to study the plausibility of intermediate steps in MPEGO. Results demonstrate that MPEGO provides a flexible, user-driven, and multi-level evaluation framework, with practical insights on the generation quality. The framework, source code, and experiments will be available at https://github.com/GT4SD/mpego.
BON: An extended public domain dataset for human activity recognition
Sep 12, 2022



Body-worn first-person vision (FPV) camera enables to extract a rich source of information on the environment from the subject's viewpoint. However, the research progress in wearable camera-based egocentric office activity understanding is slow compared to other activity environments (e.g., kitchen and outdoor ambulatory), mainly due to the lack of adequate datasets to train more sophisticated (e.g., deep learning) models for human activity recognition in office environments. This paper provides details of a large and publicly available office activity dataset (BON) collected in different office settings across three geographical locations: Barcelona (Spain), Oxford (UK) and Nairobi (Kenya), using a chest-mounted GoPro Hero camera. The BON dataset contains eighteen common office activities that can be categorised into person-to-person interactions (e.g., Chat with colleagues), person-to-object (e.g., Writing on a whiteboard), and proprioceptive (e.g., Walking). Annotation is provided for each segment of video with 5-seconds duration. Generally, BON contains 25 subjects and 2639 total segments. In order to facilitate further research in the sub-domain, we have also provided results that could be used as baselines for future studies.
Pattern Detection in the Activation Space for Identifying Synthesized Content
May 27, 2021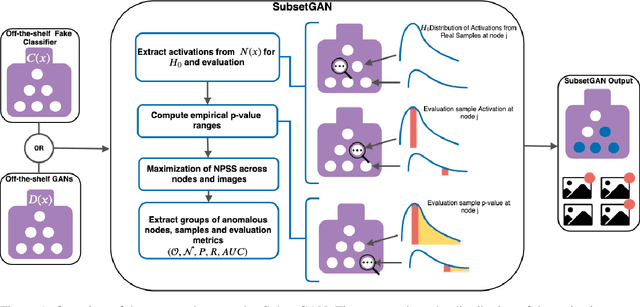
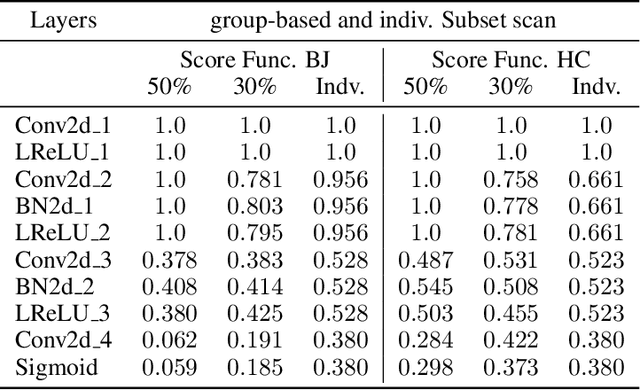
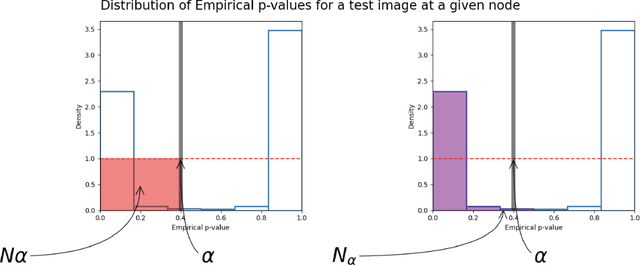

Generative Adversarial Networks (GANs) have recently achieved unprecedented success in photo-realistic image synthesis from low-dimensional random noise. The ability to synthesize high-quality content at a large scale brings potential risks as the generated samples may lead to misinformation that can create severe social, political, health, and business hazards. We propose SubsetGAN to identify generated content by detecting a subset of anomalous node-activations in the inner layers of pre-trained neural networks. These nodes, as a group, maximize a non-parametric measure of divergence away from the expected distribution of activations created from real data. This enable us to identify synthesised images without prior knowledge of their distribution. SubsetGAN efficiently scores subsets of nodes and returns the group of nodes within the pre-trained classifier that contributed to the maximum score. The classifier can be a general fake classifier trained over samples from multiple sources or the discriminator network from different GANs. Our approach shows consistently higher detection power than existing detection methods across several state-of-the-art GANs (PGGAN, StarGAN, and CycleGAN) and over different proportions of generated content.
DeepMI: Deep Multi-lead ECG Fusion for Identifying Myocardial Infarction and its Occurrence-time
Mar 31, 2021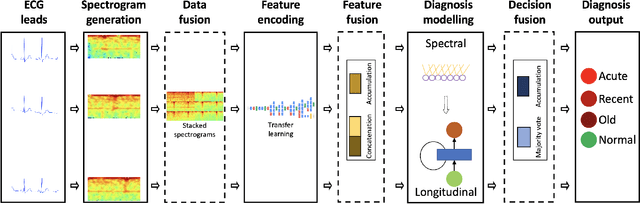
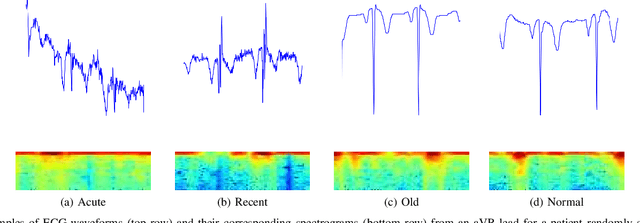
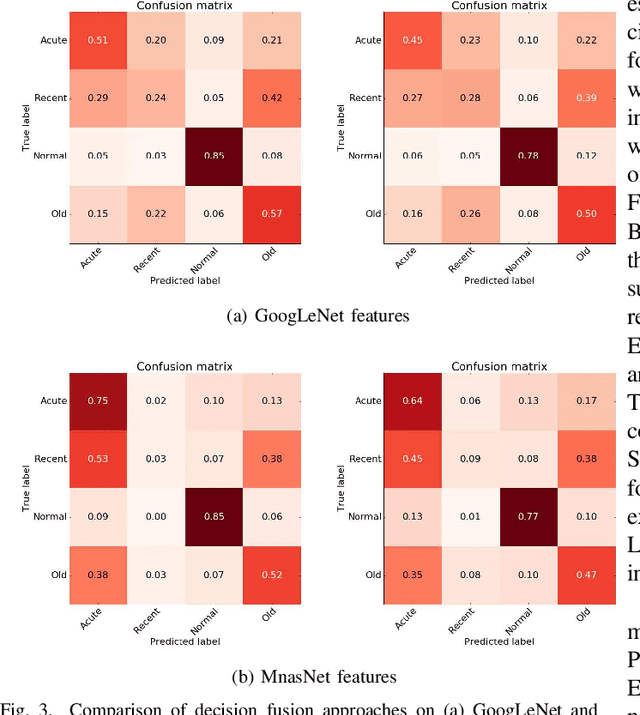

Myocardial Infarction (MI) has the highest mortality of all cardiovascular diseases (CVDs). Detection of MI and information regarding its occurrence-time in particular, would enable timely interventions that may improve patient outcomes, thereby reducing the global rise in CVD deaths. Electrocardiogram (ECG) recordings are currently used to screen MI patients. However, manual inspection of ECGs is time-consuming and prone to subjective bias. Machine learning methods have been adopted for automated ECG diagnosis, but most approaches require extraction of ECG beats or consider leads independently of one another. We propose an end-to-end deep learning approach, DeepMI, to classify MI from normal cases as well as identifying the time-occurrence of MI (defined as acute, recent and old), using a collection of fusion strategies on 12 ECG leads at data-, feature-, and decision-level. In order to minimise computational overhead, we employ transfer learning using existing computer vision networks. Moreover, we use recurrent neural networks to encode the longitudinal information inherent in ECGs. We validated DeepMI on a dataset collected from 17,381 patients, in which over 323,000 samples were extracted per ECG lead. We were able to classify normal cases as well as acute, recent and old onset cases of MI, with AUROCs of 96.7%, 82.9%, 68.6% and 73.8%, respectively. We have demonstrated a multi-lead fusion approach to detect the presence and occurrence-time of MI. Our end-to-end framework provides flexibility for different levels of multi-lead ECG fusion and performs feature extraction via transfer learning.
Prediction of neonatal mortality in Sub-Saharan African countries using data-level linkage of multiple surveys
Nov 25, 2020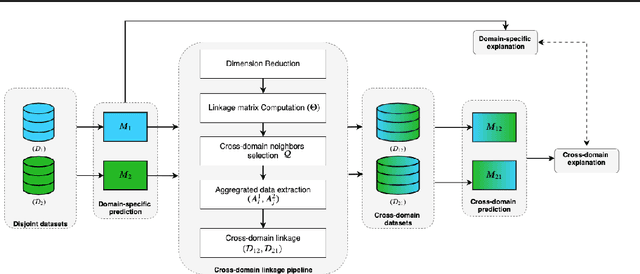


Existing datasets available to address crucial problems, such as child mortality and family planning discontinuation in developing countries, are not ample for data-driven approaches. This is partly due to disjoint data collection efforts employed across locations, times, and variations of modalities. On the other hand, state-of-the-art methods for small data problem are confined to image modalities. In this work, we proposed a data-level linkage of disjoint surveys across Sub-Saharan African countries to improve prediction performance of neonatal death and provide cross-domain explainability.
Preservation of Anomalous Subgroups On Machine Learning Transformed Data
Nov 09, 2019



In this paper, we investigate the effect of machine learning based anonymization on anomalous subgroup preservation. In particular, we train a binary classifier to discover the most anomalous subgroup in a dataset by maximizing the bias between the group's predicted odds ratio from the model and observed odds ratio from the data. We then perform anonymization using a variational autoencoder (VAE) to synthesize an entirely new dataset that would ideally be drawn from the distribution of the original data. We repeat the anomalous subgroup discovery task on the new data and compare it to what was identified pre-anonymization. We evaluated our approach using publicly available datasets from the financial industry. Our evaluation confirmed that the approach was able to produce synthetic datasets that preserved a high level of subgroup differentiation as identified initially in the original dataset. Such a distinction was maintained while having distinctly different records between the synthetic and original dataset. Finally, we packed the above end to end process into what we call Utility Guaranteed Deep Privacy (UGDP) system. UGDP can be easily extended to onboard alternative generative approaches such as GANs to synthesize tabular data.
Analyzing Bias in Sensitive Personal Information Used to Train Financial Models
Nov 09, 2019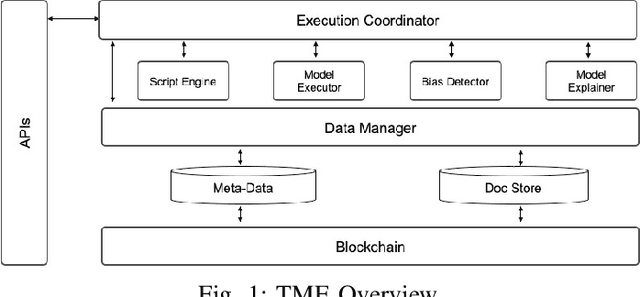
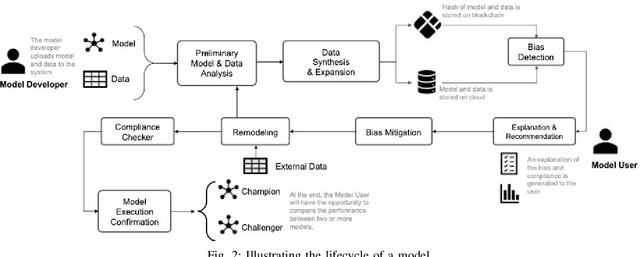

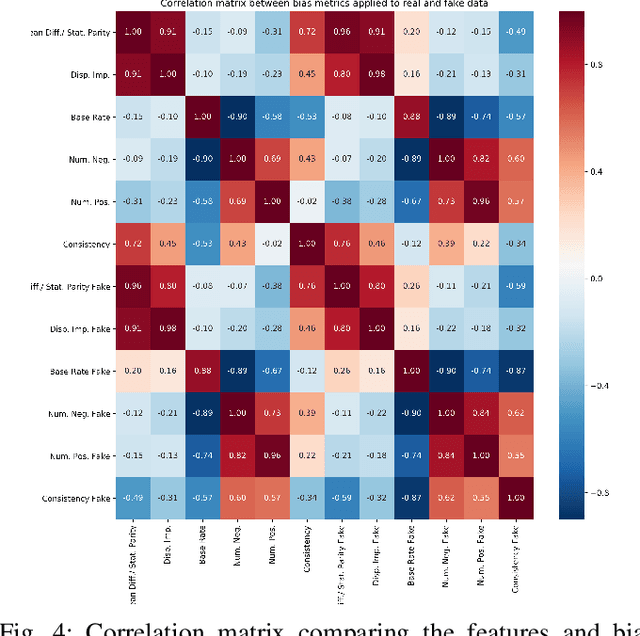
Bias in data can have unintended consequences that propagate to the design, development, and deployment of machine learning models. In the financial services sector, this can result in discrimination from certain financial instruments and services. At the same time, data privacy is of paramount importance, and recent data breaches have seen reputational damage for large institutions. Presented in this paper is a trusted model-lifecycle management platform that attempts to ensure consumer data protection, anonymization, and fairness. Specifically, we examine how datasets can be reproduced using deep learning techniques to effectively retain important statistical features in datasets whilst simultaneously protecting data privacy and enabling safe and secure sharing of sensitive personal information beyond the current state-of-practice.
Subset Scanning Over Neural Network Activations
Oct 19, 2018
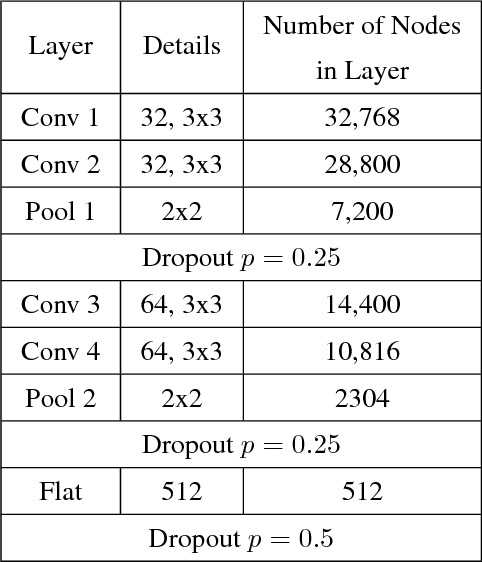
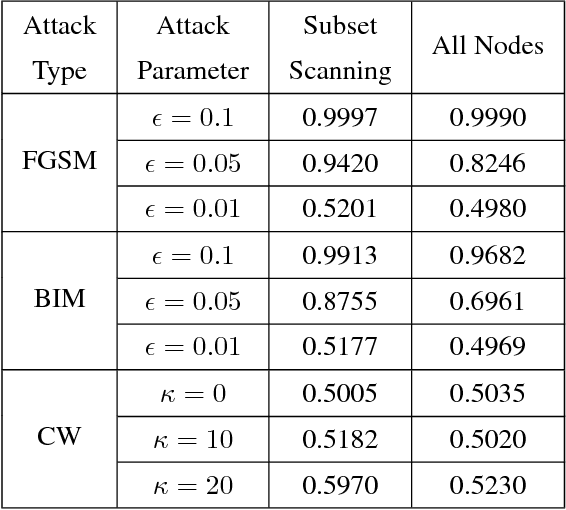
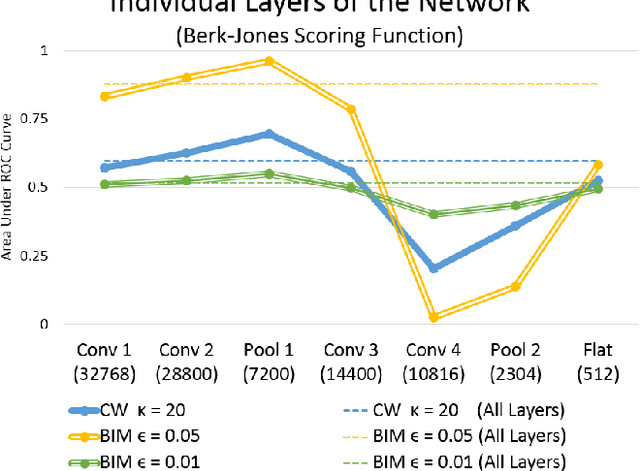
This work views neural networks as data generating systems and applies anomalous pattern detection techniques on that data in order to detect when a network is processing an anomalous input. Detecting anomalies is a critical component for multiple machine learning problems including detecting adversarial noise. More broadly, this work is a step towards giving neural networks the ability to recognize an out-of-distribution sample. This is the first work to introduce "Subset Scanning" methods from the anomalous pattern detection domain to the task of detecting anomalous input of neural networks. Subset scanning treats the detection problem as a search for the most anomalous subset of node activations (i.e., highest scoring subset according to non-parametric scan statistics). Mathematical properties of these scoring functions allow the search to be completed in log-linear rather than exponential time while still guaranteeing the most anomalous subset of nodes in the network is identified for a given input. Quantitative results for detecting and characterizing adversarial noise are provided for CIFAR-10 images on a simple convolutional neural network. We observe an "interference" pattern where anomalous activations in shallow layers suppress the activation structure of the original image in deeper layers.