 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich private attributes do VLMs agree on and predict well?
Feb 08, 2026Visual Language Models (VLMs) are often used for zero-shot detection of visual attributes in the image. We present a zero-shot evaluation of open-source VLMs for privacy-related attribute recognition. We identify the attributes for which VLMs exhibit strong inter-annotator agreement, and discuss the disagreement cases of human and VLM annotations. Our results show that when evaluated against human annotations, VLMs tend to predict the presence of privacy attributes more often than human annotators. In addition to this, we find that in cases of high inter-annotator agreement between VLMs, they can complement human annotation by identifying attributes overlooked by human annotators. This highlights the potential of VLMs to support privacy annotations in large-scale image datasets.
PrivLEX: Detecting legal concepts in images through Vision-Language Models
Jan 14, 2026We present PrivLEX, a novel image privacy classifier that grounds its decisions in legally defined personal data concepts. PrivLEX is the first interpretable privacy classifier aligned with legal concepts that leverages the recognition capabilities of Vision-Language Models (VLMs). PrivLEX relies on zero-shot VLM concept detection to provide interpretable classification through a label-free Concept Bottleneck Model, without requiring explicit concept labels during training. We demonstrate PrivLEX's ability to identify personal data concepts that are present in images. We further analyse the sensitivity of such concepts as perceived by human annotators of image privacy datasets.
Cross-modal Counterfactual Explanations: Uncovering Decision Factors and Dataset Biases in Subjective Classification
Dec 21, 2025Concept-driven counterfactuals explain decisions of classifiers by altering the model predictions through semantic changes. In this paper, we present a novel approach that leverages cross-modal decompositionality and image-specific concepts to create counterfactual scenarios expressed in natural language. We apply the proposed interpretability framework, termed Decompose and Explain (DeX), to the challenging domain of image privacy decisions, which are contextual and subjective. This application enables the quantification of the differential contributions of key scene elements to the model prediction. We identify relevant decision factors via a multi-criterion selection mechanism that considers both image similarity for minimal perturbations and decision confidence to prioritize impactful changes. This approach evaluates and compares diverse explanations, and assesses the interdependency and mutual influence among explanatory properties. By leveraging image-specific concepts, DeX generates image-grounded, sparse explanations, yielding significant improvements over the state of the art. Importantly, DeX operates as a training-free framework, offering high flexibility. Results show that DeX not only uncovers the principal contributing factors influencing subjective decisions, but also identifies underlying dataset biases allowing for targeted mitigation strategies to improve fairness.
The impact of abstract and object tags on image privacy classification
Oct 09, 2025Object tags denote concrete entities and are central to many computer vision tasks, whereas abstract tags capture higher-level information, which is relevant for tasks that require a contextual, potentially subjective scene understanding. Object and abstract tags extracted from images also facilitate interpretability. In this paper, we explore which type of tags is more suitable for the context-dependent and inherently subjective task of image privacy. While object tags are generally used for privacy classification, we show that abstract tags are more effective when the tag budget is limited. Conversely, when a larger number of tags per image is available, object-related information is as useful. We believe that these findings will guide future research in developing more accurate image privacy classifiers, informed by the role of tag types and quantity.
Specializing General-purpose LLM Embeddings for Implicit Hate Speech Detection across Datasets
Aug 28, 2025Implicit hate speech (IHS) is indirect language that conveys prejudice or hatred through subtle cues, sarcasm or coded terminology. IHS is challenging to detect as it does not include explicit derogatory or inflammatory words. To address this challenge, task-specific pipelines can be complemented with external knowledge or additional information such as context, emotions and sentiment data. In this paper, we show that, by solely fine-tuning recent general-purpose embedding models based on large language models (LLMs), such as Stella, Jasper, NV-Embed and E5, we achieve state-of-the-art performance. Experiments on multiple IHS datasets show up to 1.10 percentage points improvements for in-dataset, and up to 20.35 percentage points improvements in cross-dataset evaluation, in terms of F1-macro score.
3D Face Reconstruction Error Decomposed: A Modular Benchmark for Fair and Fast Method Evaluation
May 23, 2025Computing the standard benchmark metric for 3D face reconstruction, namely geometric error, requires a number of steps, such as mesh cropping, rigid alignment, or point correspondence. Current benchmark tools are monolithic (they implement a specific combination of these steps), even though there is no consensus on the best way to measure error. We present a toolkit for a Modularized 3D Face reconstruction Benchmark (M3DFB), where the fundamental components of error computation are segregated and interchangeable, allowing one to quantify the effect of each. Furthermore, we propose a new component, namely correction, and present a computationally efficient approach that penalizes for mesh topology inconsistency. Using this toolkit, we test 16 error estimators with 10 reconstruction methods on two real and two synthetic datasets. Critically, the widely used ICP-based estimator provides the worst benchmarking performance, as it significantly alters the true ranking of the top-5 reconstruction methods. Notably, the correlation of ICP with the true error can be as low as 0.41. Moreover, non-rigid alignment leads to significant improvement (correlation larger than 0.90), highlighting the importance of annotating 3D landmarks on datasets. Finally, the proposed correction scheme, together with non-rigid warping, leads to an accuracy on a par with the best non-rigid ICP-based estimators, but runs an order of magnitude faster. Our open-source codebase is designed for researchers to easily compare alternatives for each component, thus helping accelerating progress in benchmarking for 3D face reconstruction and, furthermore, supporting the improvement of learned reconstruction methods, which depend on accurate error estimation for effective training.
Visual Affordances: Enabling Robots to Understand Object Functionality
May 08, 2025Human-robot interaction for assistive technologies relies on the prediction of affordances, which are the potential actions a robot can perform on objects. Predicting object affordances from visual perception is formulated differently for tasks such as grasping detection, affordance classification, affordance segmentation, and hand-object interaction synthesis. In this work, we highlight the reproducibility issue in these redefinitions, making comparative benchmarks unfair and unreliable. To address this problem, we propose a unified formulation for visual affordance prediction, provide a comprehensive and systematic review of previous works highlighting strengths and limitations of methods and datasets, and analyse what challenges reproducibility. To favour transparency, we introduce the Affordance Sheet, a document to detail the proposed solution, the datasets, and the validation. As the physical properties of an object influence the interaction with the robot, we present a generic framework that links visual affordance prediction to the physical world. Using the weight of an object as an example for this framework, we discuss how estimating object mass can affect the affordance prediction. Our approach bridges the gap between affordance perception and robot actuation, and accounts for the complete information about objects of interest and how the robot interacts with them to accomplish its task.
Learning Privacy from Visual Entities
Mar 16, 2025Subjective interpretation and content diversity make predicting whether an image is private or public a challenging task. Graph neural networks combined with convolutional neural networks (CNNs), which consist of 14,000 to 500 millions parameters, generate features for visual entities (e.g., scene and object types) and identify the entities that contribute to the decision. In this paper, we show that using a simpler combination of transfer learning and a CNN to relate privacy with scene types optimises only 732 parameters while achieving comparable performance to that of graph-based methods. On the contrary, end-to-end training of graph-based methods can mask the contribution of individual components to the classification performance. Furthermore, we show that a high-dimensional feature vector, extracted with CNNs for each visual entity, is unnecessary and complexifies the model. The graph component has also negligible impact on performance, which is driven by fine-tuning the CNN to optimise image features for privacy nodes.
Stereo Hand-Object Reconstruction for Human-to-Robot Handover
Dec 10, 2024



Jointly estimating hand and object shape ensures the success of the robot grasp in human-to-robot handovers. However, relying on hand-crafted prior knowledge about the geometric structure of the object fails when generalising to unseen objects, and depth sensors fail to detect transparent objects such as drinking glasses. In this work, we propose a stereo-based method for hand-object reconstruction that combines single-view reconstructions probabilistically to form a coherent stereo reconstruction. We learn 3D shape priors from a large synthetic hand-object dataset to ensure that our method is generalisable, and use RGB inputs instead of depth as RGB can better capture transparent objects. We show that our method achieves a lower object Chamfer distance compared to existing RGB based hand-object reconstruction methods on single view and stereo settings. We process the reconstructed hand-object shape with a projection-based outlier removal step and use the output to guide a human-to-robot handover pipeline with wide-baseline stereo RGB cameras. Our hand-object reconstruction enables a robot to successfully receive a diverse range of household objects from the human.
Identifying Privacy Personas
Oct 17, 2024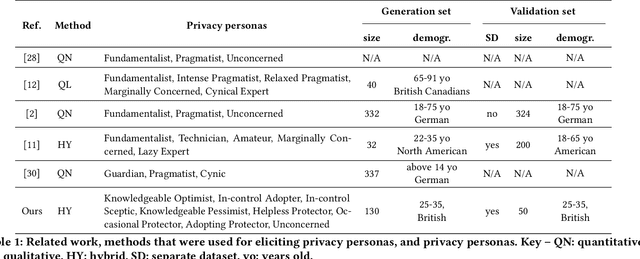



Privacy personas capture the differences in user segments with respect to one's knowledge, behavioural patterns, level of self-efficacy, and perception of the importance of privacy protection. Modelling these differences is essential for appropriately choosing personalised communication about privacy (e.g. to increase literacy) and for defining suitable choices for privacy enhancing technologies (PETs). While various privacy personas have been derived in the literature, they group together people who differ from each other in terms of important attributes such as perceived or desired level of control, and motivation to use PET. To address this lack of granularity and comprehensiveness in describing personas, we propose eight personas that we derive by combining qualitative and quantitative analysis of the responses to an interactive educational questionnaire. We design an analysis pipeline that uses divisive hierarchical clustering and Boschloo's statistical test of homogeneity of proportions to ensure that the elicited clusters differ from each other based on a statistical measure. Additionally, we propose a new measure for calculating distances between questionnaire responses, that accounts for the type of the question (closed- vs open-ended) used to derive traits. We show that the proposed privacy personas statistically differ from each other. We statistically validate the proposed personas and also compare them with personas in the literature, showing that they provide a more granular and comprehensive understanding of user segments, which will allow to better assist users with their privacy needs.