 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining models relating objects and privacy
Paper and Code

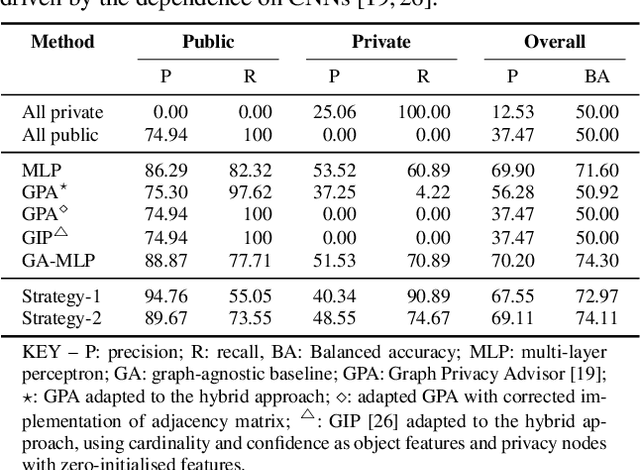
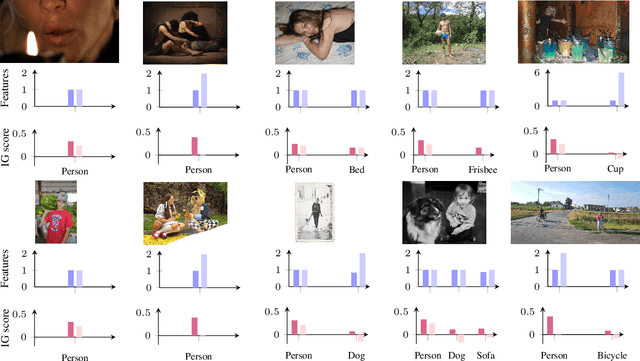

Accurately predicting whether an image is private before sharing it online is difficult due to the vast variety of content and the subjective nature of privacy itself. In this paper, we evaluate privacy models that use objects extracted from an image to determine why the image is predicted as private. To explain the decision of these models, we use feature-attribution to identify and quantify which objects (and which of their features) are more relevant to privacy classification with respect to a reference input (i.e., no objects localised in an image) predicted as public. We show that the presence of the person category and its cardinality is the main factor for the privacy decision. Therefore, these models mostly fail to identify private images depicting documents with sensitive data, vehicle ownership, and internet activity, or public images with people (e.g., an outdoor concert or people walking in a public space next to a famous landmark). As baselines for future benchmarks, we also devise two strategies that are based on the person presence and cardinality and achieve comparable classification performance of the privacy models.