 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Affordances: Enabling Robots to Understand Object Functionality
May 08, 2025Human-robot interaction for assistive technologies relies on the prediction of affordances, which are the potential actions a robot can perform on objects. Predicting object affordances from visual perception is formulated differently for tasks such as grasping detection, affordance classification, affordance segmentation, and hand-object interaction synthesis. In this work, we highlight the reproducibility issue in these redefinitions, making comparative benchmarks unfair and unreliable. To address this problem, we propose a unified formulation for visual affordance prediction, provide a comprehensive and systematic review of previous works highlighting strengths and limitations of methods and datasets, and analyse what challenges reproducibility. To favour transparency, we introduce the Affordance Sheet, a document to detail the proposed solution, the datasets, and the validation. As the physical properties of an object influence the interaction with the robot, we present a generic framework that links visual affordance prediction to the physical world. Using the weight of an object as an example for this framework, we discuss how estimating object mass can affect the affordance prediction. Our approach bridges the gap between affordance perception and robot actuation, and accounts for the complete information about objects of interest and how the robot interacts with them to accomplish its task.
Learning Privacy from Visual Entities
Mar 16, 2025Subjective interpretation and content diversity make predicting whether an image is private or public a challenging task. Graph neural networks combined with convolutional neural networks (CNNs), which consist of 14,000 to 500 millions parameters, generate features for visual entities (e.g., scene and object types) and identify the entities that contribute to the decision. In this paper, we show that using a simpler combination of transfer learning and a CNN to relate privacy with scene types optimises only 732 parameters while achieving comparable performance to that of graph-based methods. On the contrary, end-to-end training of graph-based methods can mask the contribution of individual components to the classification performance. Furthermore, we show that a high-dimensional feature vector, extracted with CNNs for each visual entity, is unnecessary and complexifies the model. The graph component has also negligible impact on performance, which is driven by fine-tuning the CNN to optimise image features for privacy nodes.
Stereo Hand-Object Reconstruction for Human-to-Robot Handover
Dec 10, 2024



Jointly estimating hand and object shape ensures the success of the robot grasp in human-to-robot handovers. However, relying on hand-crafted prior knowledge about the geometric structure of the object fails when generalising to unseen objects, and depth sensors fail to detect transparent objects such as drinking glasses. In this work, we propose a stereo-based method for hand-object reconstruction that combines single-view reconstructions probabilistically to form a coherent stereo reconstruction. We learn 3D shape priors from a large synthetic hand-object dataset to ensure that our method is generalisable, and use RGB inputs instead of depth as RGB can better capture transparent objects. We show that our method achieves a lower object Chamfer distance compared to existing RGB based hand-object reconstruction methods on single view and stereo settings. We process the reconstructed hand-object shape with a projection-based outlier removal step and use the output to guide a human-to-robot handover pipeline with wide-baseline stereo RGB cameras. Our hand-object reconstruction enables a robot to successfully receive a diverse range of household objects from the human.
Segmenting Object Affordances: Reproducibility and Sensitivity to Scale
Sep 03, 2024Visual affordance segmentation identifies image regions of an object an agent can interact with. Existing methods re-use and adapt learning-based architectures for semantic segmentation to the affordance segmentation task and evaluate on small-size datasets. However, experimental setups are often not reproducible, thus leading to unfair and inconsistent comparisons. In this work, we benchmark these methods under a reproducible setup on two single objects scenarios, tabletop without occlusions and hand-held containers, to facilitate future comparisons. We include a version of a recent architecture, Mask2Former, re-trained for affordance segmentation and show that this model is the best-performing on most testing sets of both scenarios. Our analysis shows that models are not robust to scale variations when object resolutions differ from those in the training set.
Explaining models relating objects and privacy
May 02, 2024
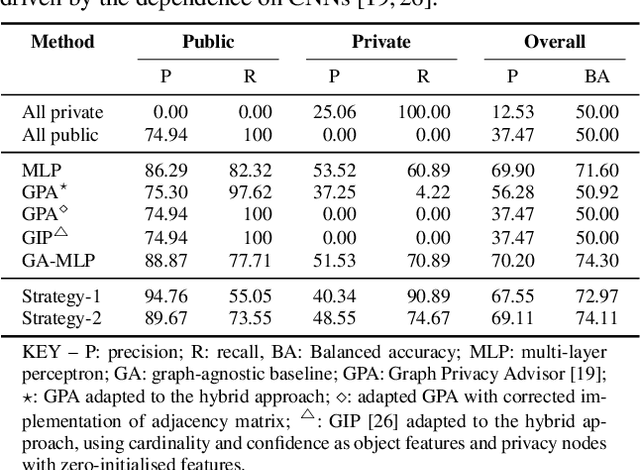
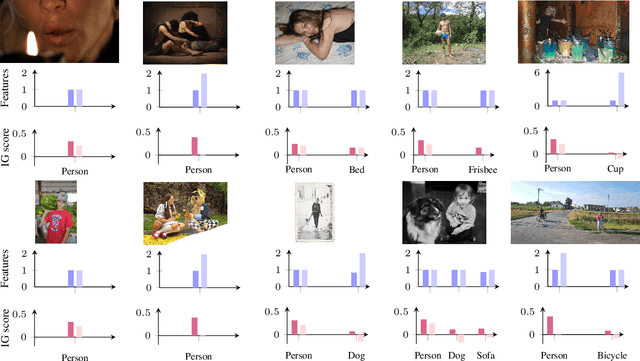

Accurately predicting whether an image is private before sharing it online is difficult due to the vast variety of content and the subjective nature of privacy itself. In this paper, we evaluate privacy models that use objects extracted from an image to determine why the image is predicted as private. To explain the decision of these models, we use feature-attribution to identify and quantify which objects (and which of their features) are more relevant to privacy classification with respect to a reference input (i.e., no objects localised in an image) predicted as public. We show that the presence of the person category and its cardinality is the main factor for the privacy decision. Therefore, these models mostly fail to identify private images depicting documents with sensitive data, vehicle ownership, and internet activity, or public images with people (e.g., an outdoor concert or people walking in a public space next to a famous landmark). As baselines for future benchmarks, we also devise two strategies that are based on the person presence and cardinality and achieve comparable classification performance of the privacy models.
Affordance segmentation of hand-occluded containers from exocentric images
Aug 22, 2023
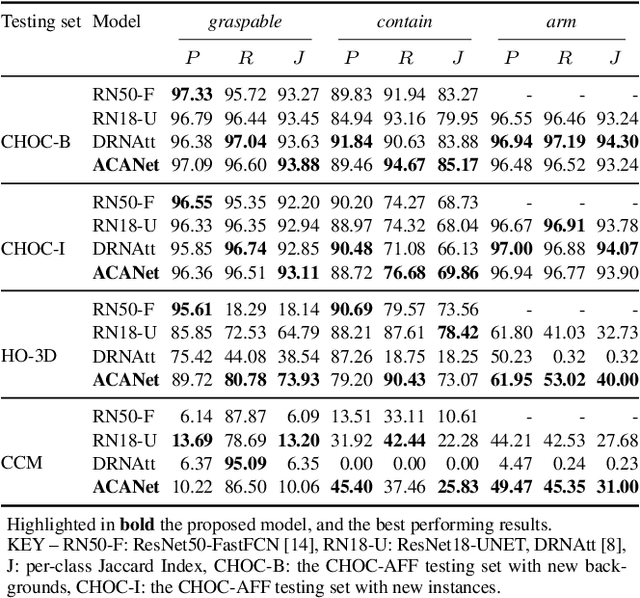
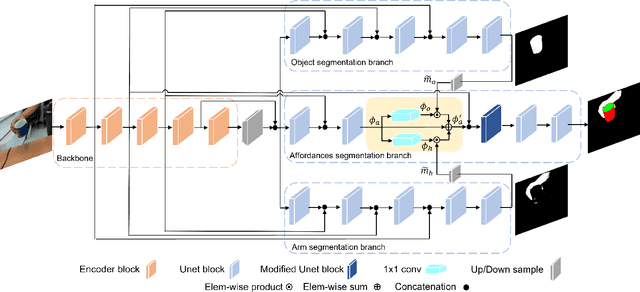
Visual affordance segmentation identifies the surfaces of an object an agent can interact with. Common challenges for the identification of affordances are the variety of the geometry and physical properties of these surfaces as well as occlusions. In this paper, we focus on occlusions of an object that is hand-held by a person manipulating it. To address this challenge, we propose an affordance segmentation model that uses auxiliary branches to process the object and hand regions separately. The proposed model learns affordance features under hand-occlusion by weighting the feature map through hand and object segmentation. To train the model, we annotated the visual affordances of an existing dataset with mixed-reality images of hand-held containers in third-person (exocentric) images. Experiments on both real and mixed-reality images show that our model achieves better affordance segmentation and generalisation than existing models.
A mixed-reality dataset for category-level 6D pose and size estimation of hand-occluded containers
Nov 18, 2022Estimating the 6D pose and size of household containers is challenging due to large intra-class variations in the object properties, such as shape, size, appearance, and transparency. The task is made more difficult when these objects are held and manipulated by a person due to varying degrees of hand occlusions caused by the type of grasps and by the viewpoint of the camera observing the person holding the object. In this paper, we present a mixed-reality dataset of hand-occluded containers for category-level 6D object pose and size estimation. The dataset consists of 138,240 images of rendered hands and forearms holding 48 synthetic objects, split into 3 grasp categories over 30 real backgrounds. We re-train and test an existing model for 6D object pose estimation on our mixed-reality dataset. We discuss the impact of the use of this dataset in improving the task of 6D pose and size estimation.
Cross-Camera View-Overlap Recognition
Aug 24, 2022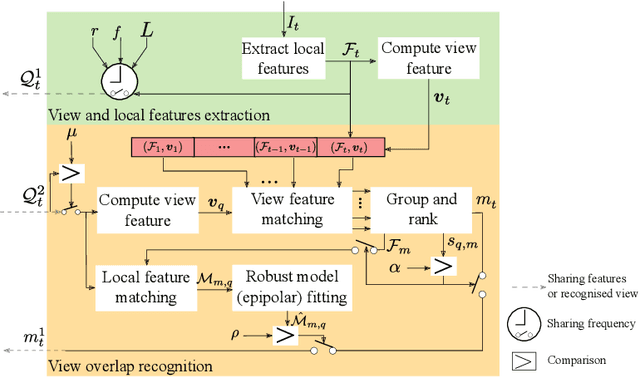
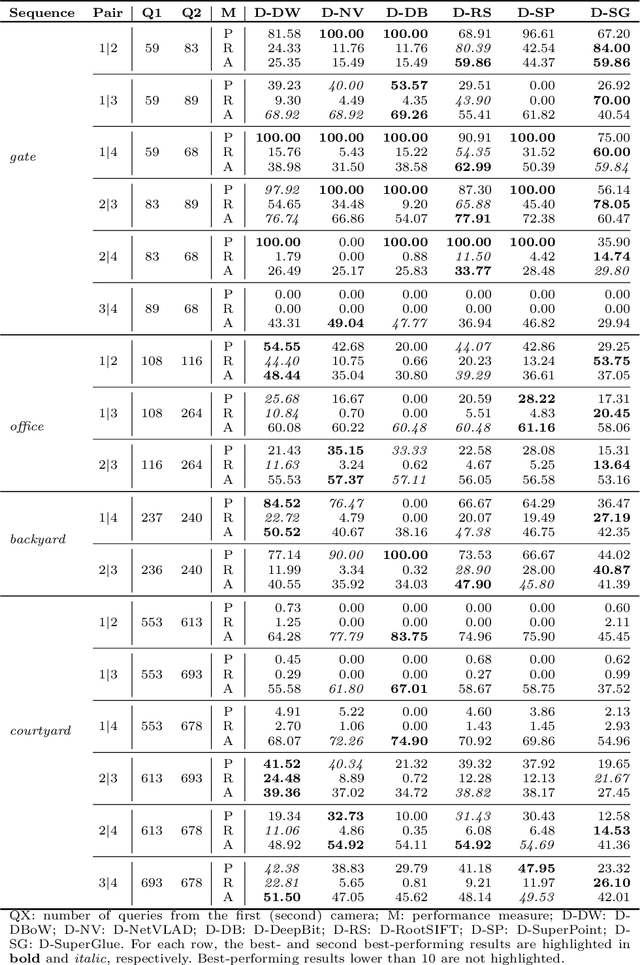
We propose a decentralised view-overlap recognition framework that operates across freely moving cameras without the need of a reference 3D map. Each camera independently extracts, aggregates into a hierarchical structure, and shares feature-point descriptors over time. A view overlap is recognised by view-matching and geometric validation to discard wrongly matched views. The proposed framework is generic and can be used with different descriptors. We conduct the experiments on publicly available sequences as well as new sequences we collected with hand-held cameras. We show that Oriented FAST and Rotated BRIEF (ORB) features with Bags of Binary Words within the proposed framework lead to higher precision and a higher or similar accuracy compared to NetVLAD, RootSIFT, and SuperGlue.
Multi-modal estimation of the properties of containers and their content: survey and evaluation
Jul 27, 2021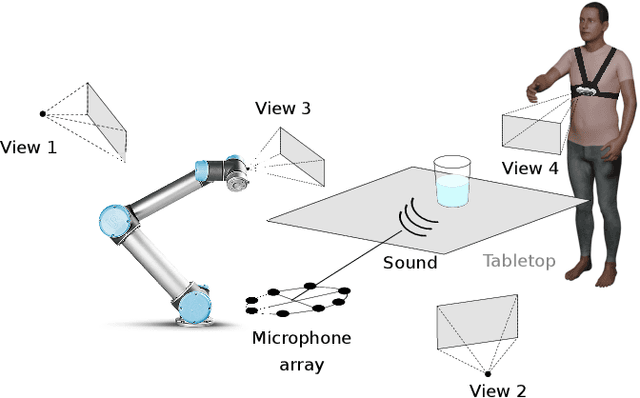


Acoustic and visual sensing can support the contactless estimation of the weight of a container and the amount of its content when the container is manipulated by a person. However, transparencies (both of the container and of the content) and the variability of materials, shapes and sizes make this problem challenging. In this paper, we present an open benchmarking framework and an in-depth comparative analysis of recent methods that estimate the capacity of a container, as well as the type, mass, and amount of its content. These methods use learned and handcrafted features, such as mel-frequency cepstrum coefficients, zero-crossing rate, spectrograms, with different types of classifiers to estimate the type and amount of the content with acoustic data, and geometric approaches with visual data to determine the capacity of the container. Results on a newly distributed dataset show that audio alone is a strong modality and methods achieves a weighted average F1-score up to 81% and 97% for content type and level classification, respectively. Estimating the container capacity with vision-only approaches and filling mass with multi-modal, multi-stage algorithms reaches up to 65% weighted average capacity and mass scores.
Towards safe human-to-robot handovers of unknown containers
Jul 03, 2021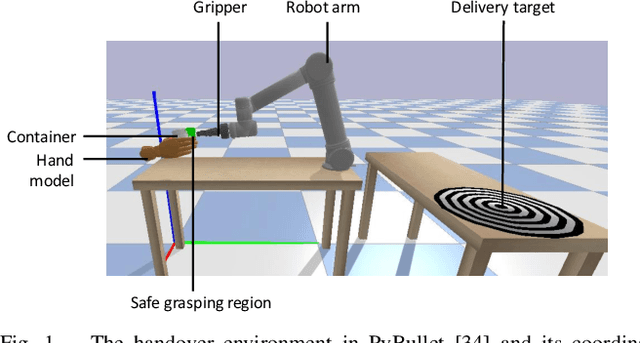


Safe human-to-robot handovers of unknown objects require accurate estimation of hand poses and object properties, such as shape, trajectory, and weight. Accurately estimating these properties requires the use of scanned 3D object models or expensive equipment, such as motion capture systems and markers, or both. However, testing handover algorithms with robots may be dangerous for the human and, when the object is an open container with liquids, for the robot. In this paper, we propose a real-to-simulation framework to develop safe human-to-robot handovers with estimations of the physical properties of unknown cups or drinking glasses and estimations of the human hands from videos of a human manipulating the container. We complete the handover in simulation, and we estimate a region that is not occluded by the hand of the human holding the container. We also quantify the safeness of the human and object in simulation. We validate the framework using public recordings of containers manipulated before a handover and show the safeness of the handover when using noisy estimates from a range of perceptual algorithms.