 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Efficient Deep Learning for Traffic Classification on Microcontrollers
Jun 12, 2025In this paper, we present a practical deep learning (DL) approach for energy-efficient traffic classification (TC) on resource-limited microcontrollers, which are widely used in IoT-based smart systems and communication networks. Our objective is to balance accuracy, computational efficiency, and real-world deployability. To that end, we develop a lightweight 1D-CNN, optimized via hardware-aware neural architecture search (HW-NAS), which achieves 96.59% accuracy on the ISCX VPN-NonVPN dataset with only 88.26K parameters, a 20.12K maximum tensor size, and 10.08M floating-point operations (FLOPs). Moreover, it generalizes across various TC tasks, with accuracies ranging from 94% to 99%. To enable deployment, the model is quantized to INT8, suffering only a marginal 1-2% accuracy drop relative to its Float32 counterpart. We evaluate real-world inference performance on two microcontrollers: the high-performance STM32F746G-DISCO and the cost-sensitive Nucleo-F401RE. The deployed model achieves inference latencies of 31.43ms and 115.40ms, with energy consumption of 7.86 mJ and 29.10 mJ per inference, respectively. These results demonstrate the feasibility of on-device encrypted traffic analysis, paving the way for scalable, low-power IoT security solutions.
Efficient Traffic Classification using HW-NAS: Advanced Analysis and Optimization for Cybersecurity on Resource-Constrained Devices
Jun 12, 2025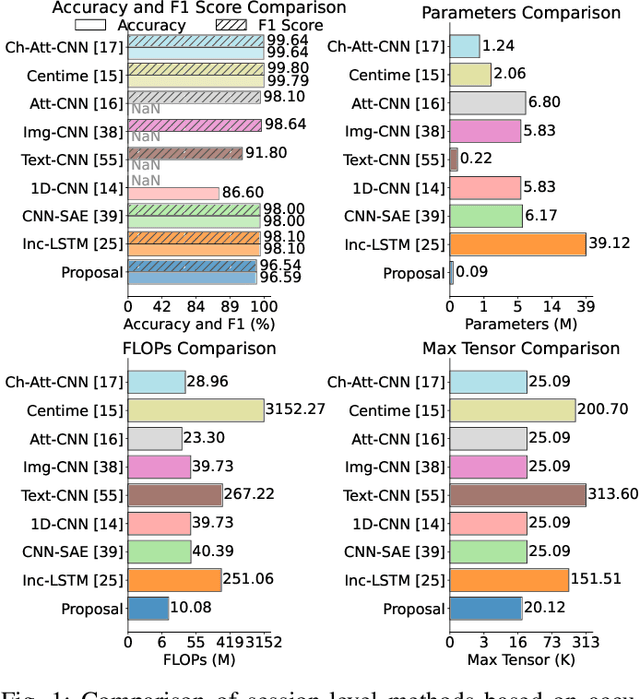
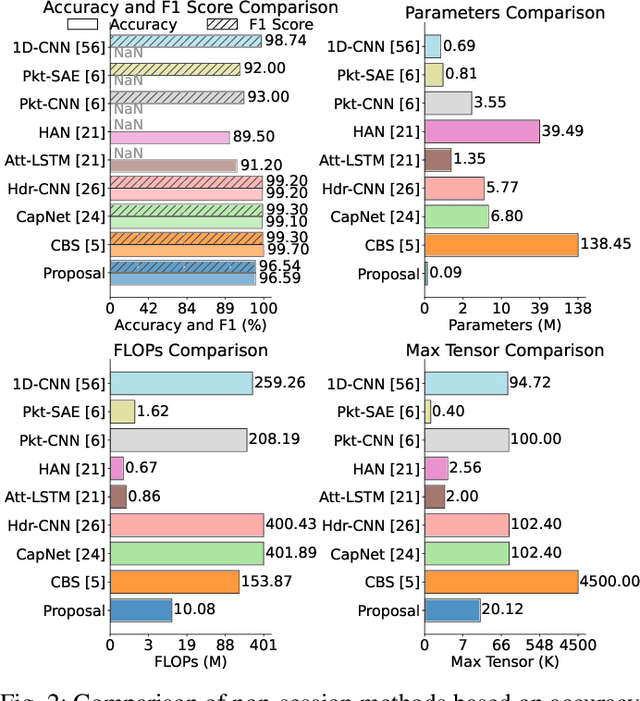
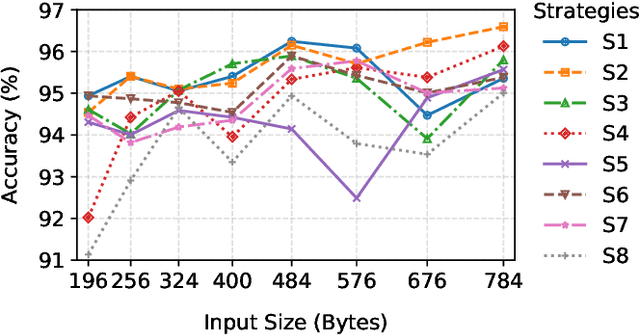
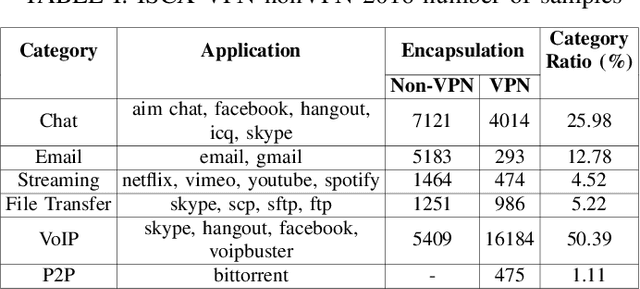
This paper presents a hardware-efficient deep neural network (DNN), optimized through hardware-aware neural architecture search (HW-NAS); the DNN supports the classification of session-level encrypted traffic on resource-constrained Internet of Things (IoT) and edge devices. Thanks to HW-NAS, a 1D convolutional neural network (CNN) is tailored on the ISCX VPN-nonVPN dataset to meet strict memory and computational limits while achieving robust performance. The optimized model attains an accuracy of 96.59% with just 88.26K parameters, 10.08M FLOPs, and a maximum tensor size of 20.12K. Compared to state-of-the-art models, it achieves reductions of up to 444-fold, 312-fold, and 15.6-fold in these metrics, respectively, significantly minimizing memory footprint and runtime requirements. The model also demonstrates versatility in classification tasks, achieving accuracies of up to 99.64% in VPN differentiation, VPN-type classification, broader traffic categories, and application identification. In addition, an in-depth approach to header-level preprocessing strategies confirms that the optimized model can provide notable performances across a wide range of configurations, even in scenarios with stricter privacy considerations. Likewise, a reduction in the length of sessions of up to 75% yields significant improvements in efficiency, while maintaining high accuracy with only a negligible drop of 1-2%. However, the importance of careful preprocessing and session length selection in the classification of raw traffic data is still present, as improper settings or aggressive reductions can bring about a 7% reduction in overall accuracy. Those results highlight the method's effectiveness in enforcing cybersecurity for IoT networks, by providing scalable, efficient solutions for the real-time analysis of encrypted traffic within strict hardware limitations.
Searching Neural Architectures for Sensor Nodes on IoT Gateways
May 29, 2025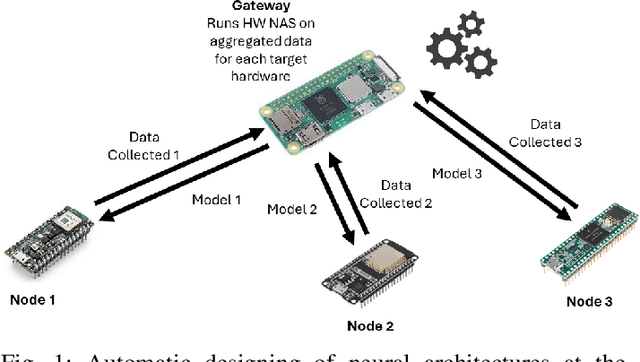
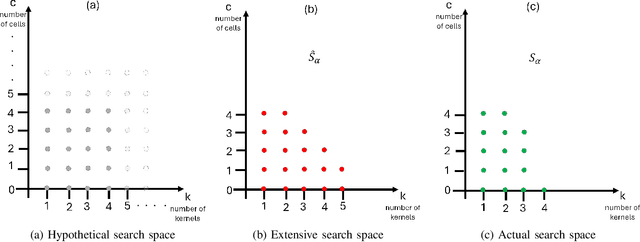
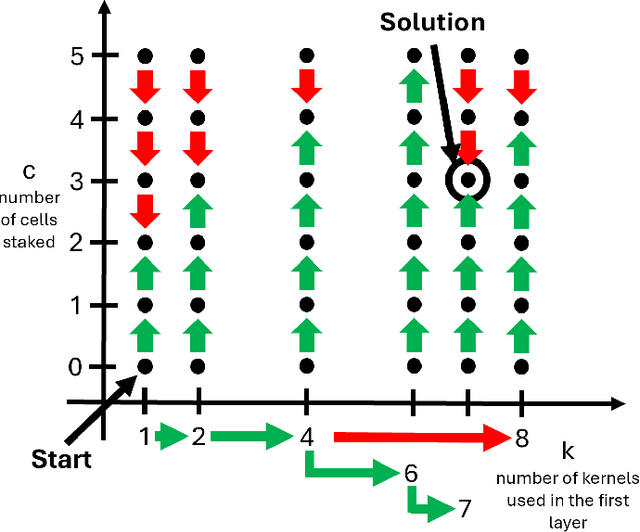
This paper presents an automatic method for the design of Neural Networks (NNs) at the edge, enabling Machine Learning (ML) access even in privacy-sensitive Internet of Things (IoT) applications. The proposed method runs on IoT gateways and designs NNs for connected sensor nodes without sharing the collected data outside the local network, keeping the data in the site of collection. This approach has the potential to enable ML for Healthcare Internet of Things (HIoT) and Industrial Internet of Things (IIoT), designing hardware-friendly and custom NNs at the edge for personalized healthcare and advanced industrial services such as quality control, predictive maintenance, or fault diagnosis. By preventing data from being disclosed to cloud services, this method safeguards sensitive information, including industrial secrets and personal data. The outcomes of a thorough experimental session confirm that -- on the Visual Wake Words dataset -- the proposed approach can achieve state-of-the-art results by exploiting a search procedure that runs in less than 10 hours on the Raspberry Pi Zero 2.
Segmenting Object Affordances: Reproducibility and Sensitivity to Scale
Sep 03, 2024Visual affordance segmentation identifies image regions of an object an agent can interact with. Existing methods re-use and adapt learning-based architectures for semantic segmentation to the affordance segmentation task and evaluate on small-size datasets. However, experimental setups are often not reproducible, thus leading to unfair and inconsistent comparisons. In this work, we benchmark these methods under a reproducible setup on two single objects scenarios, tabletop without occlusions and hand-held containers, to facilitate future comparisons. We include a version of a recent architecture, Mask2Former, re-trained for affordance segmentation and show that this model is the best-performing on most testing sets of both scenarios. Our analysis shows that models are not robust to scale variations when object resolutions differ from those in the training set.
Affordance segmentation of hand-occluded containers from exocentric images
Aug 22, 2023
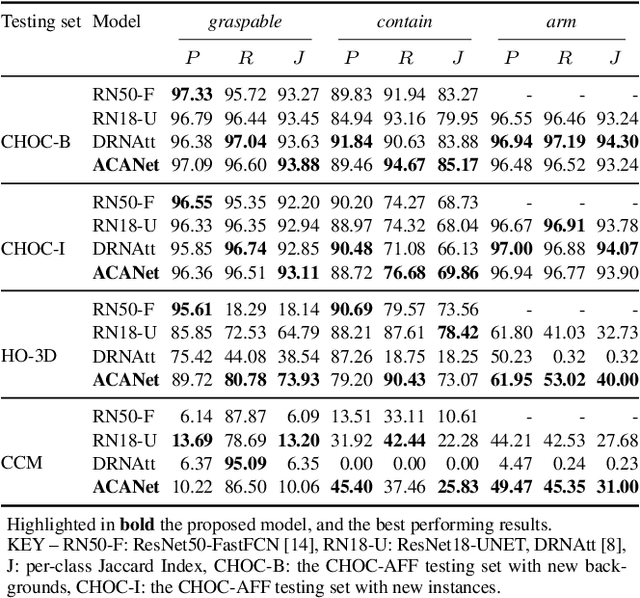
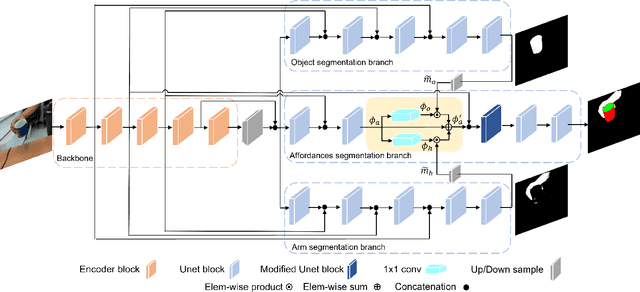
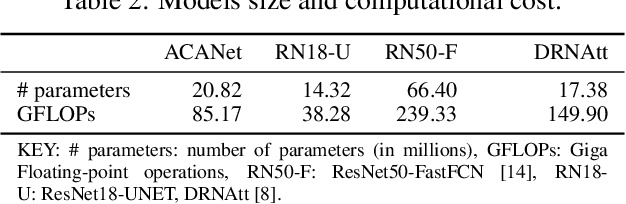
Visual affordance segmentation identifies the surfaces of an object an agent can interact with. Common challenges for the identification of affordances are the variety of the geometry and physical properties of these surfaces as well as occlusions. In this paper, we focus on occlusions of an object that is hand-held by a person manipulating it. To address this challenge, we propose an affordance segmentation model that uses auxiliary branches to process the object and hand regions separately. The proposed model learns affordance features under hand-occlusion by weighting the feature map through hand and object segmentation. To train the model, we annotated the visual affordances of an existing dataset with mixed-reality images of hand-held containers in third-person (exocentric) images. Experiments on both real and mixed-reality images show that our model achieves better affordance segmentation and generalisation than existing models.
Container Localisation and Mass Estimation with an RGB-D Camera
Mar 02, 2022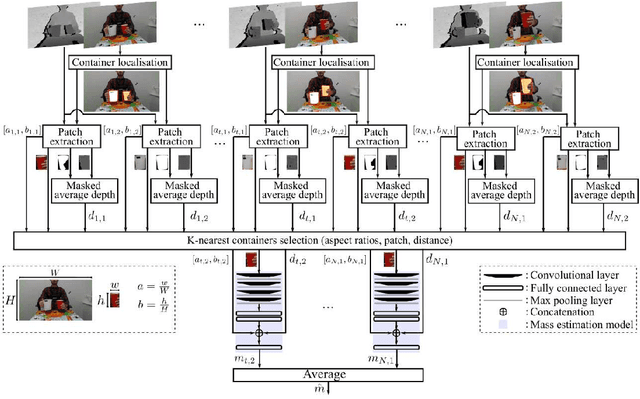


In the research area of human-robot interactions, the automatic estimation of the mass of a container manipulated by a person leveraging only visual information is a challenging task. The main challenges consist of occlusions, different filling materials and lighting conditions. The mass of an object constitutes key information for the robot to correctly regulate the force required to grasp the container. We propose a single RGB-D camera-based method to locate a manipulated container and estimate its empty mass i.e., independently of the presence of the content. The method first automatically selects a number of candidate containers based on the distance with the fixed frontal view, then averages the mass predictions of a lightweight model to provide the final estimation. Results on the CORSMAL Containers Manipulation dataset show that the proposed method estimates empty container mass obtaining a score of 71.08% under different lighting or filling conditions.