 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContainer Localisation and Mass Estimation with an RGB-D Camera
Mar 02, 2022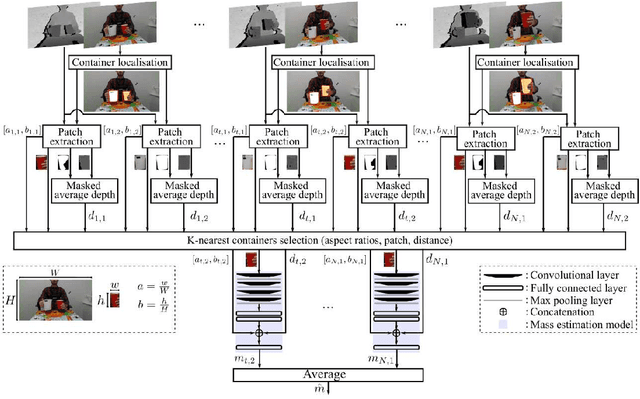
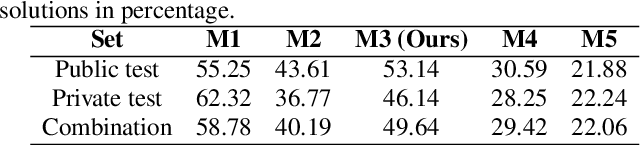


In the research area of human-robot interactions, the automatic estimation of the mass of a container manipulated by a person leveraging only visual information is a challenging task. The main challenges consist of occlusions, different filling materials and lighting conditions. The mass of an object constitutes key information for the robot to correctly regulate the force required to grasp the container. We propose a single RGB-D camera-based method to locate a manipulated container and estimate its empty mass i.e., independently of the presence of the content. The method first automatically selects a number of candidate containers based on the distance with the fixed frontal view, then averages the mass predictions of a lightweight model to provide the final estimation. Results on the CORSMAL Containers Manipulation dataset show that the proposed method estimates empty container mass obtaining a score of 71.08% under different lighting or filling conditions.
Continual Learning of Predictive Models in Video Sequences via Variational Autoencoders
Jun 02, 2020



This paper proposes a method for performing continual learning of predictive models that facilitate the inference of future frames in video sequences. For a first given experience, an initial Variational Autoencoder, together with a set of fully connected neural networks are utilized to respectively learn the appearance of video frames and their dynamics at the latent space level. By employing an adapted Markov Jump Particle Filter, the proposed method recognizes new situations and integrates them as predictive models avoiding catastrophic forgetting of previously learned tasks. For evaluating the proposed method, this article uses video sequences from a vehicle that performs different tasks in a controlled environment.
Anomaly Detection in Video Data Based on Probabilistic Latent Space Models
Mar 17, 2020



This paper proposes a method for detecting anomalies in video data. A Variational Autoencoder (VAE) is used for reducing the dimensionality of video frames, generating latent space information that is comparable to low-dimensional sensory data (e.g., positioning, steering angle), making feasible the development of a consistent multi-modal architecture for autonomous vehicles. An Adapted Markov Jump Particle Filter defined by discrete and continuous inference levels is employed to predict the following frames and detecting anomalies in new video sequences. Our method is evaluated on different video scenarios where a semi-autonomous vehicle performs a set of tasks in a closed environment.