 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Reinforcement Learning for Runtime Optimization of AI Applications in Smart Eyewears
Aug 24, 2025



Extended reality technologies are transforming fields such as healthcare, entertainment, and education, with Smart Eye-Wears (SEWs) and Artificial Intelligence (AI) playing a crucial role. However, SEWs face inherent limitations in computational power, memory, and battery life, while offloading computations to external servers is constrained by network conditions and server workload variability. To address these challenges, we propose a Federated Reinforcement Learning (FRL) framework, enabling multiple agents to train collaboratively while preserving data privacy. We implemented synchronous and asynchronous federation strategies, where models are aggregated either at fixed intervals or dynamically based on agent progress. Experimental results show that federated agents exhibit significantly lower performance variability, ensuring greater stability and reliability. These findings underscore the potential of FRL for applications requiring robust real-time AI processing, such as real-time object detection in SEWs.
From Pixels to Graphs: using Scene and Knowledge Graphs for HD-EPIC VQA Challenge
Jun 10, 2025



This report presents SceneNet and KnowledgeNet, our approaches developed for the HD-EPIC VQA Challenge 2025. SceneNet leverages scene graphs generated with a multi-modal large language model (MLLM) to capture fine-grained object interactions, spatial relationships, and temporally grounded events. In parallel, KnowledgeNet incorporates ConceptNet's external commonsense knowledge to introduce high-level semantic connections between entities, enabling reasoning beyond directly observable visual evidence. Each method demonstrates distinct strengths across the seven categories of the HD-EPIC benchmark, and their combination within our framework results in an overall accuracy of 44.21% on the challenge, highlighting its effectiveness for complex egocentric VQA tasks.
Robotic surface exploration with vision and tactile sensing for cracks detection and characterisation
Jul 13, 2023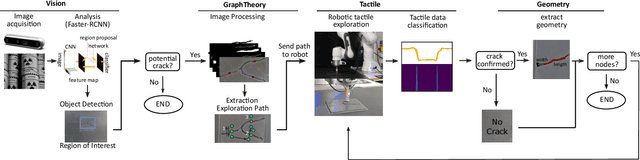

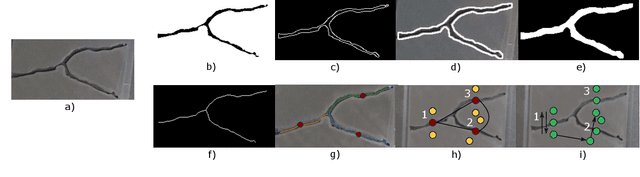
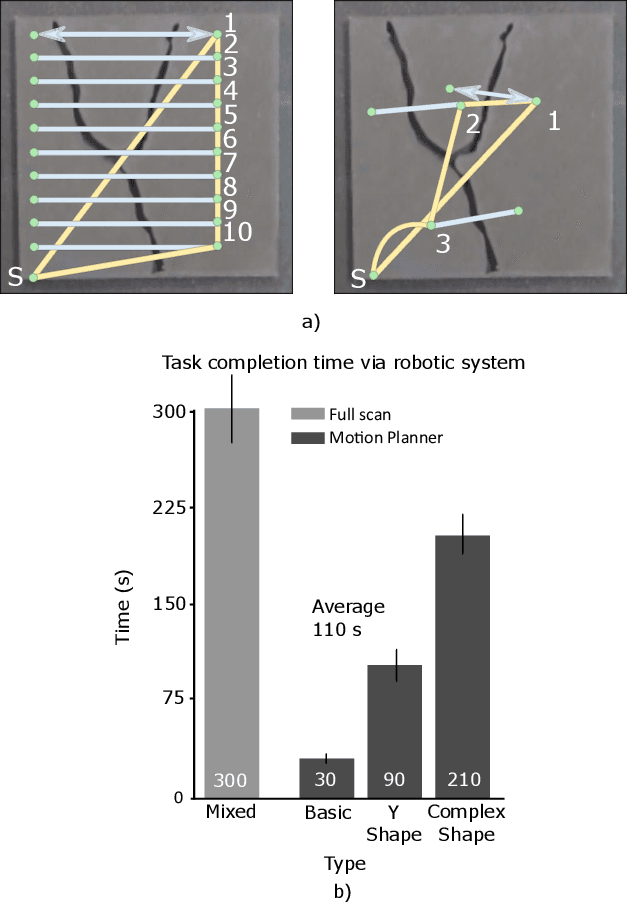
This paper presents a novel algorithm for crack localisation and detection based on visual and tactile analysis via fibre-optics. A finger-shaped sensor based on fibre-optics is employed for the data acquisition to collect data for the analysis and the experiments. To detect the possible locations of cracks a camera is used to scan an environment while running an object detection algorithm. Once the crack is detected, a fully-connected graph is created from a skeletonised version of the crack. A minimum spanning tree is then employed for calculating the shortest path to explore the crack which is then used to develop the motion planner for the robotic manipulator. The motion planner divides the crack into multiple nodes which are then explored individually. Then, the manipulator starts the exploration and performs the tactile data classification to confirm if there is indeed a crack in that location or just a false positive from the vision algorithm. If a crack is detected, also the length, width, orientation and number of branches are calculated. This is repeated until all the nodes of the crack are explored. In order to validate the complete algorithm, various experiments are performed: comparison of exploration of cracks through full scan and motion planning algorithm, implementation of frequency-based features for crack classification and geometry analysis using a combination of vision and tactile data. From the results of the experiments, it is shown that the proposed algorithm is able to detect cracks and improve the results obtained from vision to correctly classify cracks and their geometry with minimal cost thanks to the motion planning algorithm.
Information Theory Inspired Pattern Analysis for Time-series Data
Feb 22, 2023



Current methods for pattern analysis in time series mainly rely on statistical features or probabilistic learning and inference methods to identify patterns and trends in the data. Such methods do not generalize well when applied to multivariate, multi-source, state-varying, and noisy time-series data. To address these issues, we propose a highly generalizable method that uses information theory-based features to identify and learn from patterns in multivariate time-series data. To demonstrate the proposed approach, we analyze pattern changes in human activity data. For applications with stochastic state transitions, features are developed based on Shannon's entropy of Markov chains, entropy rates of Markov chains, entropy production of Markov chains, and von Neumann entropy of Markov chains. For applications where state modeling is not applicable, we utilize five entropy variants, including approximate entropy, increment entropy, dispersion entropy, phase entropy, and slope entropy. The results show the proposed information theory-based features improve the recall rate, F1 score, and accuracy on average by up to 23.01\% compared with the baseline models and a simpler model structure, with an average reduction of 18.75 times in the number of model parameters.
Loss Adapted Plasticity in Deep Neural Networks to Learn from Data with Unreliable Sources
Dec 06, 2022



When data is streaming from multiple sources, conventional training methods update model weights often assuming the same level of reliability for each source; that is: a model does not consider data quality of each source during training. In many applications, sources can have varied levels of noise or corruption that has negative effects on the learning of a robust deep learning model. A key issue is that the quality of data or labels for individual sources is often not available during training and could vary over time. Our solution to this problem is to consider the mistakes made while training on data originating from sources and utilise this to create a perceived data quality for each source. This paper demonstrates a straight-forward and novel technique that can be applied to any gradient descent optimiser: Update model weights as a function of the perceived reliability of data sources within a wider data set. The algorithm controls the plasticity of a given model to weight updates based on the history of losses from individual data sources. We show that applying this technique can significantly improve model performance when trained on a mixture of reliable and unreliable data sources, and maintain performance when models are trained on data sources that are all considered reliable. All code to reproduce this work's experiments and implement the algorithm in the reader's own models is made available.
Designing A Clinically Applicable Deep Recurrent Model to Identify Neuropsychiatric Symptoms in People Living with Dementia Using In-Home Monitoring Data
Oct 19, 2021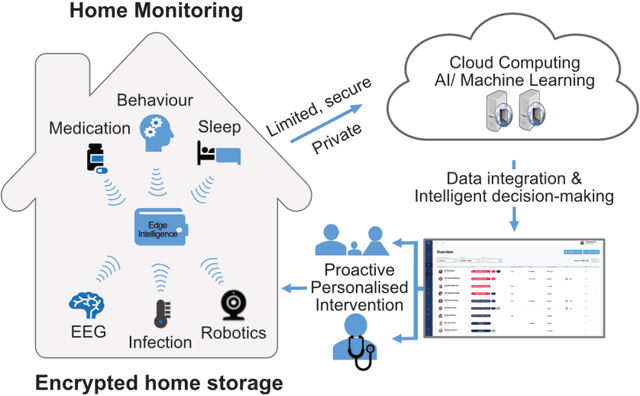
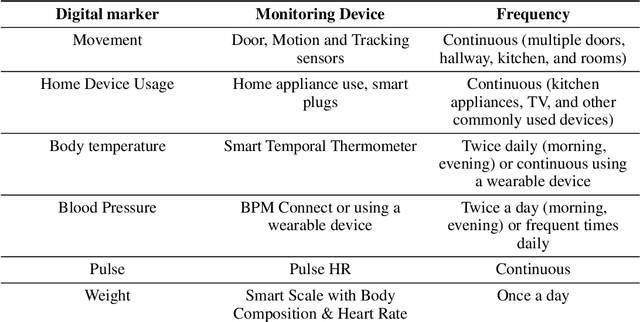

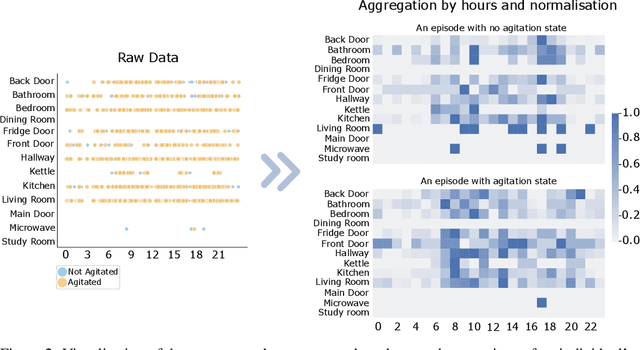
Agitation is one of the neuropsychiatric symptoms with high prevalence in dementia which can negatively impact the Activities of Daily Living (ADL) and the independence of individuals. Detecting agitation episodes can assist in providing People Living with Dementia (PLWD) with early and timely interventions. Analysing agitation episodes will also help identify modifiable factors such as ambient temperature and sleep as possible components causing agitation in an individual. This preliminary study presents a supervised learning model to analyse the risk of agitation in PLWD using in-home monitoring data. The in-home monitoring data includes motion sensors, physiological measurements, and the use of kitchen appliances from 46 homes of PLWD between April 2019-June 2021. We apply a recurrent deep learning model to identify agitation episodes validated and recorded by a clinical monitoring team. We present the experiments to assess the efficacy of the proposed model. The proposed model achieves an average of 79.78% recall, 27.66% precision and 37.64% F1 scores when employing the optimal parameters, suggesting a good ability to recognise agitation events. We also discuss using machine learning models for analysing the behavioural patterns using continuous monitoring data and explore clinical applicability and the choices between sensitivity and specificity in-home monitoring applications.
Multi-modal estimation of the properties of containers and their content: survey and evaluation
Jul 27, 2021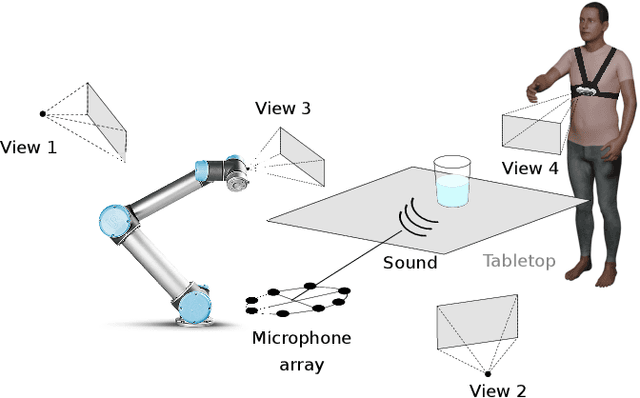


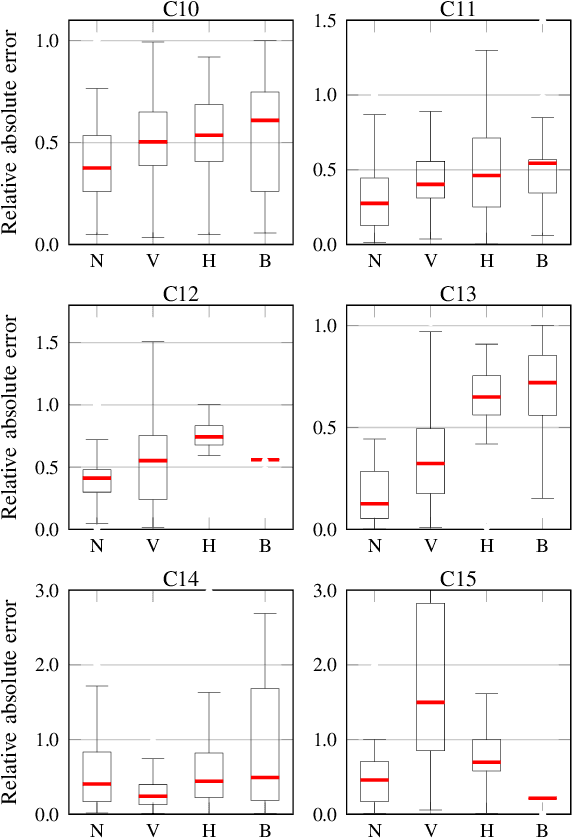
Acoustic and visual sensing can support the contactless estimation of the weight of a container and the amount of its content when the container is manipulated by a person. However, transparencies (both of the container and of the content) and the variability of materials, shapes and sizes make this problem challenging. In this paper, we present an open benchmarking framework and an in-depth comparative analysis of recent methods that estimate the capacity of a container, as well as the type, mass, and amount of its content. These methods use learned and handcrafted features, such as mel-frequency cepstrum coefficients, zero-crossing rate, spectrograms, with different types of classifiers to estimate the type and amount of the content with acoustic data, and geometric approaches with visual data to determine the capacity of the container. Results on a newly distributed dataset show that audio alone is a strong modality and methods achieves a weighted average F1-score up to 81% and 97% for content type and level classification, respectively. Estimating the container capacity with vision-only approaches and filling mass with multi-modal, multi-stage algorithms reaches up to 65% weighted average capacity and mass scores.
Top-1 CORSMAL Challenge 2020 Submission: Filling Mass Estimation Using Multi-modal Observations of Human-robot Handovers
Dec 02, 2020
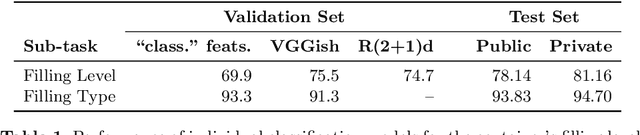
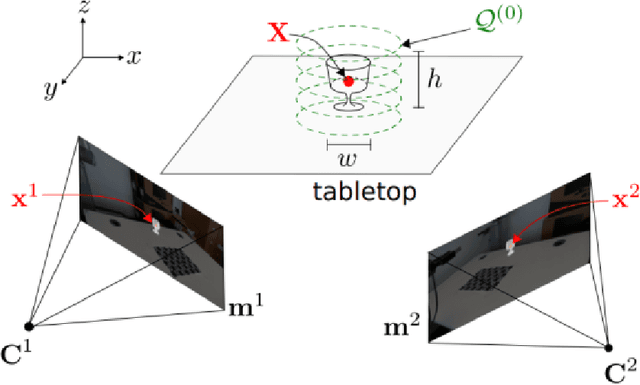
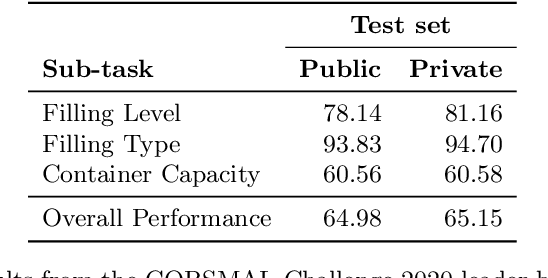
Human-robot object handover is a key skill for the future of human-robot collaboration. CORSMAL 2020 Challenge focuses on the perception part of this problem: the robot needs to estimate the filling mass of a container held by a human. Although there are powerful methods in image processing and audio processing individually, answering such a problem requires processing data from multiple sensors together. The appearance of the container, the sound of the filling, and the depth data provide essential information. We propose a multi-modal method to predict three key indicators of the filling mass: filling type, filling level, and container capacity. These indicators are then combined to estimate the filling mass of a container. Our method obtained Top-1 overall performance among all submissions to CORSMAL 2020 Challenge on both public and private subsets while showing no evidence of overfitting. Our source code is publicly available: https://github.com/v-iashin/CORSMAL