 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVSM: Decoder-only View Synthesis Model Done Right
May 28, 2026Recent Large View Synthesis Models (LVSMs) advocate an encoder-decoder architecture that separates reconstruction and rendering into distinct networks. We re-examine this design. Through controlled experiments, we show that a decoder-only architecture, which represents scenes implicitly as a KV-cache, outperforms encoder-decoder variants while using fewer parameters at identical rendering complexity. Further analysis shows that sharing weights between the color-input reconstruction network and the camera-only rendering network better aligns their features at the same viewpoint, facilitating image synthesis. Building on this finding, our model, dubbed DVSM, further incorporates foundation model priors and stage-wise patch sizing for an improved efficiency-quality tradeoff. Our results establish a new state of the art for novel-view synthesis across multiple benchmarks, in some cases even outperforming per-scene-optimized 3DGS under dense input views.
Agent Explorative Policy Optimization for Multimodal Agentic Reasoning
May 27, 2026Vision-language models with extended reasoning succeed on complex problems, but many real-world problems require external tools that internal reasoning alone often cannot resolve. Agentic reasoning therefore interleaves two behaviors with a structural asymmetry: thinking (the self-contained default) and tool use (a high-variance auxiliary acting). We refer to this asymmetry as the Thinking-Acting Gap. Under standard RL recipes like GRPO, the gap manifests as two diagnostic symptoms during training: tool use is attempted on only ~30% of rollouts, and when attempted, the tool-using rollouts within a group are all-wrong on ~40% of questions, suppressing the learning signal at the tool calls that needed it. We propose AXPO (Agent eXplorative Policy Optimization): for each all-wrong tool-using subgroup, AXPO fixes the thinking prefix and resamples the tool call and its continuation, paired with uncertainty-based prefix selection. Across nine multimodal benchmarks and three scales of Qwen3-VL-Thinking, SFT+AXPO outperforms SFT+GRPO at average (+1.8pp Pass@1 and +1.8pp Pass@4 at 8B on average) and 8B with SFT+AXPO surpasses the 32B Base on Pass@4 with 4 times fewer parameters.
Learning from Synthetic Data via Provenance-Based Input Gradient Guidance
Apr 03, 2026Learning methods using synthetic data have attracted attention as an effective approach for increasing the diversity of training data while reducing collection costs, thereby improving the robustness of model discrimination. However, many existing methods improve robustness only indirectly through the diversification of training samples and do not explicitly teach the model which regions in the input space truly contribute to discrimination; consequently, the model may learn spurious correlations caused by synthesis biases and artifacts. Motivated by this limitation, this paper proposes a learning framework that uses provenance information obtained during the training data synthesis process, indicating whether each region in the input space originates from the target object, as an auxiliary supervisory signal to promote the acquisition of representations focused on target regions. Specifically, input gradients are decomposed based on information about target and non-target regions during synthesis, and input gradient guidance is introduced to suppress gradients over non-target regions. This suppresses the model's reliance on non-target regions and directly promotes the learning of discriminative representations for target regions. Experiments demonstrate the effectiveness and generality of the proposed method across multiple tasks and modalities, including weakly supervised object localization, spatio-temporal action localization, and image classification.
Interpretable Debiasing of Vision-Language Models for Social Fairness
Feb 27, 2026The rapid advancement of Vision-Language models (VLMs) has raised growing concerns that their black-box reasoning processes could lead to unintended forms of social bias. Current debiasing approaches focus on mitigating surface-level bias signals through post-hoc learning or test-time algorithms, while leaving the internal dynamics of the model largely unexplored. In this work, we introduce an interpretable, model-agnostic bias mitigation framework, DeBiasLens, that localizes social attribute neurons in VLMs through sparse autoencoders (SAEs) applied to multimodal encoders. Building upon the disentanglement ability of SAEs, we train them on facial image or caption datasets without corresponding social attribute labels to uncover neurons highly responsive to specific demographics, including those that are underrepresented. By selectively deactivating the social neurons most strongly tied to bias for each group, we effectively mitigate socially biased behaviors of VLMs without degrading their semantic knowledge. Our research lays the groundwork for future auditing tools, prioritizing social fairness in emerging real-world AI systems.
VIOLA: Towards Video In-Context Learning with Minimal Annotations
Jan 22, 2026Generalizing Multimodal Large Language Models (MLLMs) to novel video domains is essential for real-world deployment but remains challenging due to the scarcity of labeled data. While In-Context Learning (ICL) offers a training-free adaptation path, standard methods rely on large annotated pools, which are often impractical in specialized environments like industrial or surgical settings since they require the experts' annotations. To bridge this gap, we introduce VIOLA (Video In-cOntext Learning with minimal Annotation), a label-efficient framework that synergizes minimal expert supervision with abundant unlabeled data. First, to maximize the efficiency of a strict annotation budget, we propose density-uncertainty-weighted sampling. Unlike standard diversity or uncertainty strategies that risk selecting visual outliers, our method leverages density estimation to identify samples that are simultaneously diverse, representative, and informative. Second, to utilize the remaining unlabeled data without noise propagation, we construct a hybrid pool and introduce confidence-aware retrieval and confidence-aware prompting. These mechanisms explicitly model label reliability, retrieving demonstrations based on a composite score of similarity and confidence while enabling the MLLM to adaptively distinguish between verified ground truths and noisy pseudo-labels. Extensive experiments across nine diverse benchmarks using four MLLMs demonstrate that our framework significantly outperforms various baselines in low-resource settings, achieving robust adaptation with minimal annotation costs.
Speech-Hands: A Self-Reflection Voice Agentic Approach to Speech Recognition and Audio Reasoning with Omni Perception
Jan 14, 2026We introduce a voice-agentic framework that learns one critical omni-understanding skill: knowing when to trust itself versus when to consult external audio perception. Our work is motivated by a crucial yet counterintuitive finding: naively fine-tuning an omni-model on both speech recognition and external sound understanding tasks often degrades performance, as the model can be easily misled by noisy hypotheses. To address this, our framework, Speech-Hands, recasts the problem as an explicit self-reflection decision. This learnable reflection primitive proves effective in preventing the model from being derailed by flawed external candidates. We show that this agentic action mechanism generalizes naturally from speech recognition to complex, multiple-choice audio reasoning. Across the OpenASR leaderboard, Speech-Hands consistently outperforms strong baselines by 12.1% WER on seven benchmarks. The model also achieves 77.37% accuracy and high F1 on audio QA decisions, showing robust generalization and reliability across diverse audio question answering datasets. By unifying perception and decision-making, our work offers a practical path toward more reliable and resilient audio intelligence.
Masking Teacher and Reinforcing Student for Distilling Vision-Language Models
Dec 23, 2025Large-scale vision-language models (VLMs) have recently achieved remarkable multimodal understanding, but their massive size makes them impractical for deployment on mobile or edge devices. This raises the need for compact yet capable VLMs that can efficiently learn from powerful large teachers. However, distilling knowledge from a large teacher to a small student remains challenging due to their large size gap: the student often fails to reproduce the teacher's complex, high-dimensional representations, leading to unstable learning and degraded performance. To address this, we propose Masters (Masking Teacher and Reinforcing Student), a mask-progressive reinforcement learning (RL) distillation framework. Masters first masks non-dominant weights of the teacher to reduce unnecessary complexity, then progressively restores the teacher by gradually increasing its capacity during training. This strategy allows the student to learn richer representations from the teacher in a smooth and stable manner. To further refine knowledge transfer, Masters integrates an offline RL stage with two complementary rewards: an accuracy reward that measures the correctness of the generated responses, and a distillation reward that quantifies the ease of transferring responses from teacher to student. Unlike online think-answer RL paradigms that are computationally expensive and generate lengthy responses, our offline RL leverages pre-generated responses from masked teachers. These provide rich yet efficient guidance, enabling students to achieve strong performance without requiring the think-answer process.
4D-RGPT: Toward Region-level 4D Understanding via Perceptual Distillation
Dec 22, 2025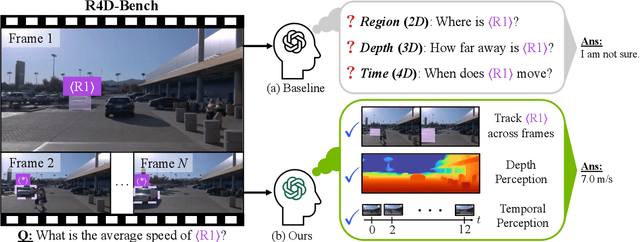

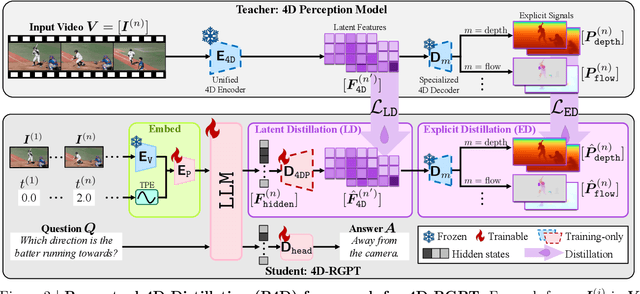
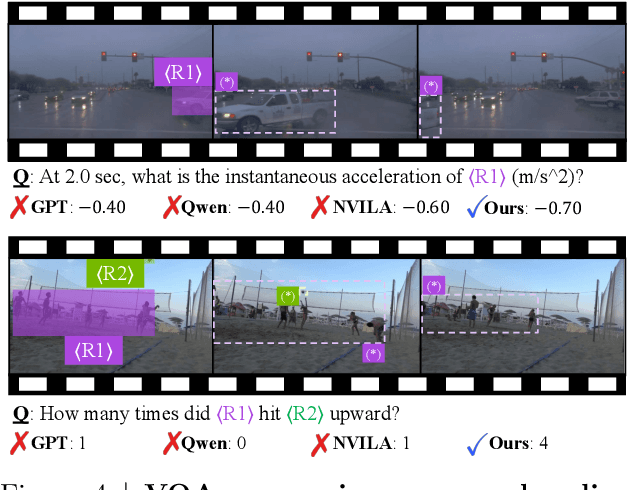
Despite advances in Multimodal LLMs (MLLMs), their ability to reason over 3D structures and temporal dynamics remains limited, constrained by weak 4D perception and temporal understanding. Existing 3D and 4D Video Question Answering (VQA) benchmarks also emphasize static scenes and lack region-level prompting. We tackle these issues by introducing: (a) 4D-RGPT, a specialized MLLM designed to capture 4D representations from video inputs with enhanced temporal perception; (b) Perceptual 4D Distillation (P4D), a training framework that transfers 4D representations from a frozen expert model into 4D-RGPT for comprehensive 4D perception; and (c) R4D-Bench, a benchmark for depth-aware dynamic scenes with region-level prompting, built via a hybrid automated and human-verified pipeline. Our 4D-RGPT achieves notable improvements on both existing 4D VQA benchmarks and the proposed R4D-Bench benchmark.
Zoom-Zero: Reinforced Coarse-to-Fine Video Understanding via Temporal Zoom-in
Dec 16, 2025Grounded video question answering (GVQA) aims to localize relevant temporal segments in videos and generate accurate answers to a given question; however, large video-language models (LVLMs) exhibit limited temporal awareness. Although existing approaches based on Group Relative Policy Optimization (GRPO) attempt to improve temporal grounding, they still struggle to faithfully ground their answers in the relevant video evidence, leading to temporal mislocalization and hallucinations. In this work, we present Zoom-Zero, a coarse-to-fine framework that first localizes query-relevant segments and then temporally zooms into the most salient frames for finer-grained visual verification. Our method addresses the limits of GRPO for the GVQA task with two key innovations: (i) a zoom-in accuracy reward that validates the fidelity of temporal grounding prediction and facilitates fine-grained visual verification on grounded frames; (ii) token-selective credit assignment, which attributes rewards to the tokens responsible for temporal localization or answer generation, mitigating GRPO's issue in handling multi-faceted reward signals. Our proposed method advances grounded video question answering, improving temporal grounding by 5.2\% on NExT-GQA and 4.6\% on ReXTime, while also enhancing average answer accuracy by 2.4\%. Additionally, the coarse-to-fine zoom-in during inference further benefits long-form video understanding by preserving critical visual details without compromising global context, yielding an average improvement of 6.4\% on long-video benchmarks.
Unified Reinforcement and Imitation Learning for Vision-Language Models
Oct 22, 2025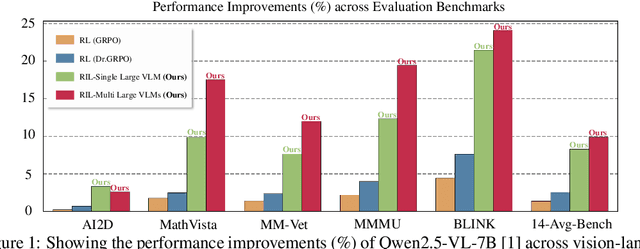



Vision-Language Models (VLMs) have achieved remarkable progress, yet their large scale often renders them impractical for resource-constrained environments. This paper introduces Unified Reinforcement and Imitation Learning (RIL), a novel and efficient training algorithm designed to create powerful, lightweight VLMs. RIL distinctively combines the strengths of reinforcement learning with adversarial imitation learning. This enables smaller student VLMs not only to mimic the sophisticated text generation of large teacher models but also to systematically improve their generative capabilities through reinforcement signals. Key to our imitation framework is an LLM-based discriminator that adeptly distinguishes between student and teacher outputs, complemented by guidance from multiple large teacher VLMs to ensure diverse learning. This unified learning strategy, leveraging both reinforcement and imitation, empowers student models to achieve significant performance gains, making them competitive with leading closed-source VLMs. Extensive experiments on diverse vision-language benchmarks demonstrate that RIL significantly narrows the performance gap with state-of-the-art open- and closed-source VLMs and, in several instances, surpasses them.