 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Non-Verbatim Memorization in Large Language Models: The Role of Entity Surface Forms
Apr 23, 2026Understanding what kinds of factual knowledge large language models (LLMs) memorize is essential for evaluating their reliability and limitations. Entity-based QA is a common framework for analyzing non-verbatim memorization, but typical evaluations query each entity using a single canonical surface form, making it difficult to disentangle fact memorization from access through a particular name. We introduce RedirectQA, an entity-based QA dataset that uses Wikipedia redirect information to associate Wikidata factual triples with categorized surface forms for each entity, including alternative names, abbreviations, spelling variants, and common erroneous forms. Across 13 LLMs, we examine surface-conditioned factual memorization and find that prediction outcomes often change when only the entity surface form changes. This inconsistency is category-dependent: models are more robust to minor orthographic variations than to larger lexical variations such as aliases and abbreviations. Frequency analyses further suggest that both entity- and surface-level frequencies are associated with accuracy, and that entity frequency often contributes beyond surface frequency. Overall, factual memorization appears neither purely surface-specific nor fully surface-invariant, highlighting the importance of surface-form diversity in evaluating non-verbatim memorization.
Learning from Synthetic Data via Provenance-Based Input Gradient Guidance
Apr 03, 2026Learning methods using synthetic data have attracted attention as an effective approach for increasing the diversity of training data while reducing collection costs, thereby improving the robustness of model discrimination. However, many existing methods improve robustness only indirectly through the diversification of training samples and do not explicitly teach the model which regions in the input space truly contribute to discrimination; consequently, the model may learn spurious correlations caused by synthesis biases and artifacts. Motivated by this limitation, this paper proposes a learning framework that uses provenance information obtained during the training data synthesis process, indicating whether each region in the input space originates from the target object, as an auxiliary supervisory signal to promote the acquisition of representations focused on target regions. Specifically, input gradients are decomposed based on information about target and non-target regions during synthesis, and input gradient guidance is introduced to suppress gradients over non-target regions. This suppresses the model's reliance on non-target regions and directly promotes the learning of discriminative representations for target regions. Experiments demonstrate the effectiveness and generality of the proposed method across multiple tasks and modalities, including weakly supervised object localization, spatio-temporal action localization, and image classification.
TimeMachine-bench: A Benchmark for Evaluating Model Capabilities in Repository-Level Migration Tasks
Jan 30, 2026With the advancement of automated software engineering, research focus is increasingly shifting toward practical tasks reflecting the day-to-day work of software engineers. Among these tasks, software migration, a critical process of adapting code to evolving environments, has been largely overlooked. In this study, we introduce TimeMachine-bench, a benchmark designed to evaluate software migration in real-world Python projects. Our benchmark consists of GitHub repositories whose tests begin to fail in response to dependency updates. The construction process is fully automated, enabling live updates of the benchmark. Furthermore, we curated a human-verified subset to ensure problem solvability. We evaluated agent-based baselines built on top of 11 models, including both strong open-weight and state-of-the-art LLMs on this verified subset. Our results indicated that, while LLMs show some promise for migration tasks, they continue to face substantial reliability challenges, including spurious solutions that exploit low test coverage and unnecessary edits stemming from suboptimal tool-use strategies. Our dataset and implementation are available at https://github.com/tohoku-nlp/timemachine-bench.
VIOLA: Towards Video In-Context Learning with Minimal Annotations
Jan 22, 2026Generalizing Multimodal Large Language Models (MLLMs) to novel video domains is essential for real-world deployment but remains challenging due to the scarcity of labeled data. While In-Context Learning (ICL) offers a training-free adaptation path, standard methods rely on large annotated pools, which are often impractical in specialized environments like industrial or surgical settings since they require the experts' annotations. To bridge this gap, we introduce VIOLA (Video In-cOntext Learning with minimal Annotation), a label-efficient framework that synergizes minimal expert supervision with abundant unlabeled data. First, to maximize the efficiency of a strict annotation budget, we propose density-uncertainty-weighted sampling. Unlike standard diversity or uncertainty strategies that risk selecting visual outliers, our method leverages density estimation to identify samples that are simultaneously diverse, representative, and informative. Second, to utilize the remaining unlabeled data without noise propagation, we construct a hybrid pool and introduce confidence-aware retrieval and confidence-aware prompting. These mechanisms explicitly model label reliability, retrieving demonstrations based on a composite score of similarity and confidence while enabling the MLLM to adaptively distinguish between verified ground truths and noisy pseudo-labels. Extensive experiments across nine diverse benchmarks using four MLLMs demonstrate that our framework significantly outperforms various baselines in low-resource settings, achieving robust adaptation with minimal annotation costs.
Human Preference-Aligned Concept Customization Benchmark via Decomposed Evaluation
Sep 03, 2025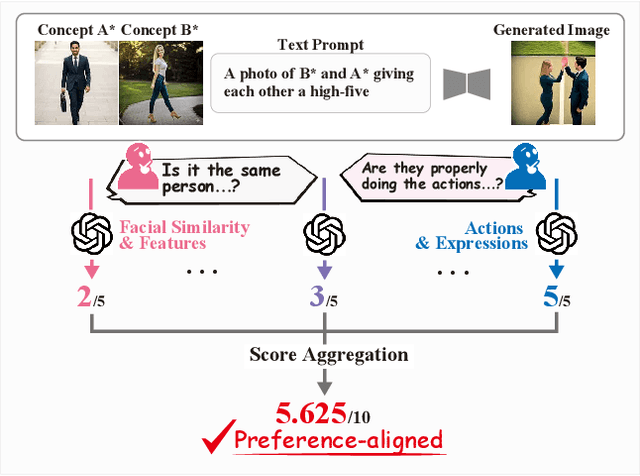

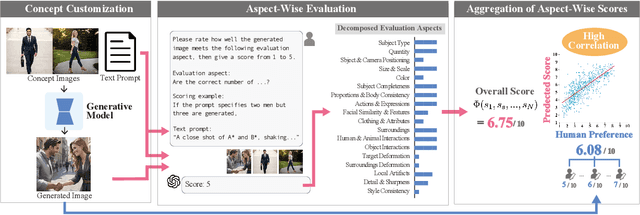

Evaluating concept customization is challenging, as it requires a comprehensive assessment of fidelity to generative prompts and concept images. Moreover, evaluating multiple concepts is considerably more difficult than evaluating a single concept, as it demands detailed assessment not only for each individual concept but also for the interactions among concepts. While humans can intuitively assess generated images, existing metrics often provide either overly narrow or overly generalized evaluations, resulting in misalignment with human preference. To address this, we propose Decomposed GPT Score (D-GPTScore), a novel human-aligned evaluation method that decomposes evaluation criteria into finer aspects and incorporates aspect-wise assessments using Multimodal Large Language Model (MLLM). Additionally, we release Human Preference-Aligned Concept Customization Benchmark (CC-AlignBench), a benchmark dataset containing both single- and multi-concept tasks, enabling stage-wise evaluation across a wide difficulty range -- from individual actions to multi-person interactions. Our method significantly outperforms existing approaches on this benchmark, exhibiting higher correlation with human preferences. This work establishes a new standard for evaluating concept customization and highlights key challenges for future research. The benchmark and associated materials are available at https://github.com/ReinaIshikawa/D-GPTScore.
EgoSurgery-HTS: A Dataset for Egocentric Hand-Tool Segmentation in Open Surgery Videos
Mar 24, 2025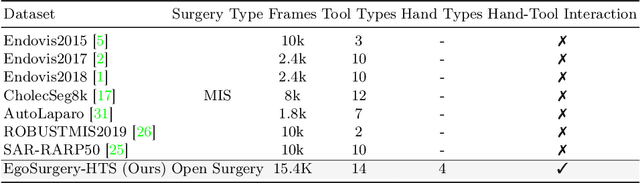

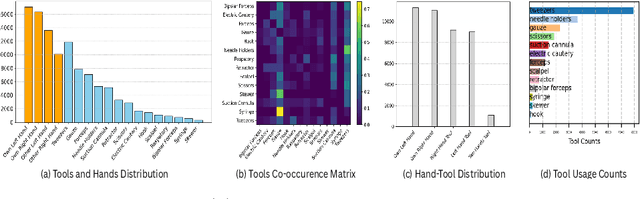
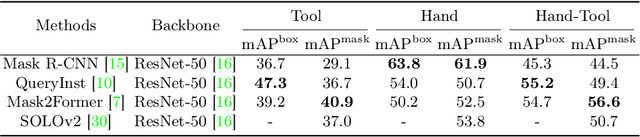
Egocentric open-surgery videos capture rich, fine-grained details essential for accurately modeling surgical procedures and human behavior in the operating room. A detailed, pixel-level understanding of hands and surgical tools is crucial for interpreting a surgeon's actions and intentions. We introduce EgoSurgery-HTS, a new dataset with pixel-wise annotations and a benchmark suite for segmenting surgical tools, hands, and interacting tools in egocentric open-surgery videos. Specifically, we provide a labeled dataset for (1) tool instance segmentation of 14 distinct surgical tools, (2) hand instance segmentation, and (3) hand-tool segmentation to label hands and the tools they manipulate. Using EgoSurgery-HTS, we conduct extensive evaluations of state-of-the-art segmentation methods and demonstrate significant improvements in the accuracy of hand and hand-tool segmentation in egocentric open-surgery videos compared to existing datasets. The dataset will be released at https://github.com/Fujiry0/EgoSurgery.
RealTraj: Towards Real-World Pedestrian Trajectory Forecasting
Nov 26, 2024



This paper jointly addresses three key limitations in conventional pedestrian trajectory forecasting: pedestrian perception errors, real-world data collection costs, and person ID annotation costs. We propose a novel framework, RealTraj, that enhances the real-world applicability of trajectory forecasting. Our approach includes two training phases--self-supervised pretraining on synthetic data and weakly-supervised fine-tuning with limited real-world data--to minimize data collection efforts. To improve robustness to real-world errors, we focus on both model design and training objectives. Specifically, we present Det2TrajFormer, a trajectory forecasting model that remains invariant in tracking noise by using past detections as inputs. Additionally, we pretrain the model using multiple pretext tasks, which enhance robustness and improve forecasting performance based solely on detection data. Unlike previous trajectory forecasting methods, our approach fine-tunes the model using only ground-truth detections, significantly reducing the need for costly person ID annotations. In the experiments, we comprehensively verify the effectiveness of the proposed method against the limitations, and the method outperforms state-of-the-art trajectory forecasting methods on multiple datasets.
CrowdMAC: Masked Crowd Density Completion for Robust Crowd Density Forecasting
Jul 20, 2024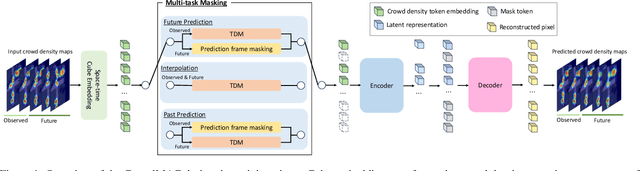
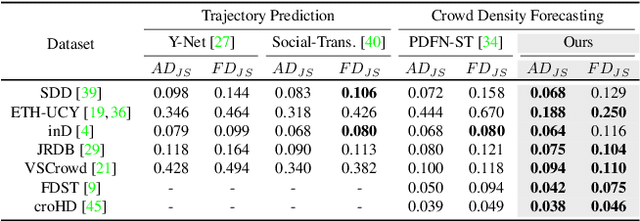

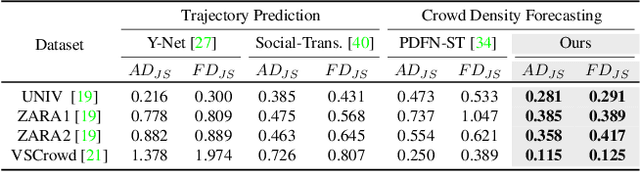
A crowd density forecasting task aims to predict how the crowd density map will change in the future from observed past crowd density maps. However, the past crowd density maps are often incomplete due to the miss-detection of pedestrians, and it is crucial to develop a robust crowd density forecasting model against the miss-detection. This paper presents a MAsked crowd density Completion framework for crowd density forecasting (CrowdMAC), which is simultaneously trained to forecast future crowd density maps from partially masked past crowd density maps (i.e., forecasting maps from past maps with miss-detection) while reconstructing the masked observation maps (i.e., imputing past maps with miss-detection). Additionally, we propose Temporal-Density-aware Masking (TDM), which non-uniformly masks tokens in the observed crowd density map, considering the sparsity of the crowd density maps and the informativeness of the subsequent frames for the forecasting task. Moreover, we introduce multi-task masking to enhance training efficiency. In the experiments, CrowdMAC achieves state-of-the-art performance on seven large-scale datasets, including SDD, ETH-UCY, inD, JRDB, VSCrowd, FDST, and croHD. We also demonstrate the robustness of the proposed method against both synthetic and realistic miss-detections.
EgoSurgery-Tool: A Dataset of Surgical Tool and Hand Detection from Egocentric Open Surgery Videos
Jun 06, 2024Surgical tool detection is a fundamental task for understanding egocentric open surgery videos. However, detecting surgical tools presents significant challenges due to their highly imbalanced class distribution, similar shapes and similar textures, and heavy occlusion. The lack of a comprehensive large-scale dataset compounds these challenges. In this paper, we introduce EgoSurgery-Tool, an extension of the existing EgoSurgery-Phase dataset, which contains real open surgery videos captured using an egocentric camera attached to the surgeon's head, along with phase annotations. EgoSurgery-Tool has been densely annotated with surgical tools and comprises over 49K surgical tool bounding boxes across 15 categories, constituting a large-scale surgical tool detection dataset. EgoSurgery-Tool also provides annotations for hand detection with over 46K hand-bounding boxes, capturing hand-object interactions that are crucial for understanding activities in egocentric open surgery. EgoSurgery-Tool is superior to existing datasets due to its larger scale, greater variety of surgical tools, more annotations, and denser scenes. We conduct a comprehensive analysis of EgoSurgery-Tool using nine popular object detectors to assess their effectiveness in both surgical tool and hand detection. The dataset will be released at https://github.com/Fujiry0/EgoSurgery.
Multimodal Cross-Domain Few-Shot Learning for Egocentric Action Recognition
May 31, 2024We address a novel cross-domain few-shot learning task (CD-FSL) with multimodal input and unlabeled target data for egocentric action recognition. This paper simultaneously tackles two critical challenges associated with egocentric action recognition in CD-FSL settings: (1) the extreme domain gap in egocentric videos (\eg, daily life vs. industrial domain) and (2) the computational cost for real-world applications. We propose MM-CDFSL, a domain-adaptive and computationally efficient approach designed to enhance adaptability to the target domain and improve inference speed. To address the first challenge, we propose the incorporation of multimodal distillation into the student RGB model using teacher models. Each teacher model is trained independently on source and target data for its respective modality. Leveraging only unlabeled target data during multimodal distillation enhances the student model's adaptability to the target domain. We further introduce ensemble masked inference, a technique that reduces the number of input tokens through masking. In this approach, ensemble prediction mitigates the performance degradation caused by masking, effectively addressing the second issue. Our approach outperformed the state-of-the-art CD-FSL approaches with a substantial margin on multiple egocentric datasets, improving by an average of 6.12/6.10 points for 1-shot/5-shot settings while achieving $2.2$ times faster inference speed. Project page: https://masashi-hatano.github.io/MM-CDFSL/