 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2GS: Event Enhanced Gaussian Splatting
Jun 21, 2024



Event cameras, known for their high dynamic range, absence of motion blur, and low energy usage, have recently found a wide range of applications thanks to these attributes. In the past few years, the field of event-based 3D reconstruction saw remarkable progress, with the Neural Radiance Field (NeRF) based approach demonstrating photorealistic view synthesis results. However, the volume rendering paradigm of NeRF necessitates extensive training and rendering times. In this paper, we introduce Event Enhanced Gaussian Splatting (E2GS), a novel method that incorporates event data into Gaussian Splatting, which has recently made significant advances in the field of novel view synthesis. Our E2GS effectively utilizes both blurry images and event data, significantly improving image deblurring and producing high-quality novel view synthesis. Our comprehensive experiments on both synthetic and real-world datasets demonstrate our E2GS can generate visually appealing renderings while offering faster training and rendering speed (140 FPS). Our code is available at https://github.com/deguchihiroyuki/E2GS.
Generalizable Neural Human Renderer
Apr 22, 2024While recent advancements in animatable human rendering have achieved remarkable results, they require test-time optimization for each subject which can be a significant limitation for real-world applications. To address this, we tackle the challenging task of learning a Generalizable Neural Human Renderer (GNH), a novel method for rendering animatable humans from monocular video without any test-time optimization. Our core method focuses on transferring appearance information from the input video to the output image plane by utilizing explicit body priors and multi-view geometry. To render the subject in the intended pose, we utilize a straightforward CNN-based image renderer, foregoing the more common ray-sampling or rasterizing-based rendering modules. Our GNH achieves remarkable generalizable, photorealistic rendering with unseen subjects with a three-stage process. We quantitatively and qualitatively demonstrate that GNH significantly surpasses current state-of-the-art methods, notably achieving a 31.3% improvement in LPIPS.
Surgical tool classification and localization: results and methods from the MICCAI 2022 SurgToolLoc challenge
May 11, 2023



The ability to automatically detect and track surgical instruments in endoscopic videos can enable transformational interventions. Assessing surgical performance and efficiency, identifying skilled tool use and choreography, and planning operational and logistical aspects of OR resources are just a few of the applications that could benefit. Unfortunately, obtaining the annotations needed to train machine learning models to identify and localize surgical tools is a difficult task. Annotating bounding boxes frame-by-frame is tedious and time-consuming, yet large amounts of data with a wide variety of surgical tools and surgeries must be captured for robust training. Moreover, ongoing annotator training is needed to stay up to date with surgical instrument innovation. In robotic-assisted surgery, however, potentially informative data like timestamps of instrument installation and removal can be programmatically harvested. The ability to rely on tool installation data alone would significantly reduce the workload to train robust tool-tracking models. With this motivation in mind we invited the surgical data science community to participate in the challenge, SurgToolLoc 2022. The goal was to leverage tool presence data as weak labels for machine learning models trained to detect tools and localize them in video frames with bounding boxes. We present the results of this challenge along with many of the team's efforts. We conclude by discussing these results in the broader context of machine learning and surgical data science. The training data used for this challenge consisting of 24,695 video clips with tool presence labels is also being released publicly and can be accessed at https://console.cloud.google.com/storage/browser/isi-surgtoolloc-2022.
Toward Unsupervised 3D Point Cloud Anomaly Detection using Variational Autoencoder
Apr 07, 2023



In this paper, we present an end-to-end unsupervised anomaly detection framework for 3D point clouds. To the best of our knowledge, this is the first work to tackle the anomaly detection task on a general object represented by a 3D point cloud. We propose a deep variational autoencoder-based unsupervised anomaly detection network adapted to the 3D point cloud and an anomaly score specifically for 3D point clouds. To verify the effectiveness of the model, we conducted extensive experiments on the ShapeNet dataset. Through quantitative and qualitative evaluation, we demonstrate that the proposed method outperforms the baseline method. Our code is available at https://github.com/llien30/point_cloud_anomaly_detection.
Event-based Camera Tracker by $ abla$t NeRF
Apr 07, 2023When a camera travels across a 3D world, only a fraction of pixel value changes; an event-based camera observes the change as sparse events. How can we utilize sparse events for efficient recovery of the camera pose? We show that we can recover the camera pose by minimizing the error between sparse events and the temporal gradient of the scene represented as a neural radiance field (NeRF). To enable the computation of the temporal gradient of the scene, we augment NeRF's camera pose as a time function. When the input pose to the NeRF coincides with the actual pose, the output of the temporal gradient of NeRF equals the observed intensity changes on the event's points. Using this principle, we propose an event-based camera pose tracking framework called TeGRA which realizes the pose update by using the sparse event's observation. To the best of our knowledge, this is the first camera pose estimation algorithm using the scene's implicit representation and the sparse intensity change from events.
Neural Implicit Event Generator for Motion Tracking
Nov 06, 2021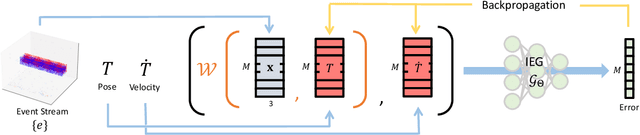



We present a novel framework of motion tracking from event data using implicit expression. Our framework use pre-trained event generation MLP named implicit event generator (IEG) and does motion tracking by updating its state (position and velocity) based on the difference between the observed event and generated event from the current state estimate. The difference is computed implicitly by the IEG. Unlike the conventional explicit approach, which requires dense computation to evaluate the difference, our implicit approach realizes efficient state update directly from sparse event data. Our sparse algorithm is especially suitable for mobile robotics applications where computational resources and battery life are limited. To verify the effectiveness of our method on real-world data, we applied it to the AR marker tracking application. We have confirmed that our framework works well in real-world environments in the presence of noise and background clutter.