 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHR: Momentum Human Rig
Nov 19, 2025We present MHR, a parametric human body model that combines the decoupled skeleton/shape paradigm of ATLAS with a flexible, modern rig and pose corrective system inspired by the Momentum library. Our model enables expressive, anatomically plausible human animation, supporting non-linear pose correctives, and is designed for robust integration in AR/VR and graphics pipelines.
S2GO: Streaming Sparse Gaussian Occupancy Prediction
Jun 05, 2025Despite the demonstrated efficiency and performance of sparse query-based representations for perception, state-of-the-art 3D occupancy prediction methods still rely on voxel-based or dense Gaussian-based 3D representations. However, dense representations are slow, and they lack flexibility in capturing the temporal dynamics of driving scenes. Distinct from prior work, we instead summarize the scene into a compact set of 3D queries which are propagated through time in an online, streaming fashion. These queries are then decoded into semantic Gaussians at each timestep. We couple our framework with a denoising rendering objective to guide the queries and their constituent Gaussians in effectively capturing scene geometry. Owing to its efficient, query-based representation, S2GO achieves state-of-the-art performance on the nuScenes and KITTI occupancy benchmarks, outperforming prior art (e.g., GaussianWorld) by 1.5 IoU with 5.9x faster inference.
Generalizable Neural Human Renderer
Apr 22, 2024While recent advancements in animatable human rendering have achieved remarkable results, they require test-time optimization for each subject which can be a significant limitation for real-world applications. To address this, we tackle the challenging task of learning a Generalizable Neural Human Renderer (GNH), a novel method for rendering animatable humans from monocular video without any test-time optimization. Our core method focuses on transferring appearance information from the input video to the output image plane by utilizing explicit body priors and multi-view geometry. To render the subject in the intended pose, we utilize a straightforward CNN-based image renderer, foregoing the more common ray-sampling or rasterizing-based rendering modules. Our GNH achieves remarkable generalizable, photorealistic rendering with unseen subjects with a three-stage process. We quantitatively and qualitatively demonstrate that GNH significantly surpasses current state-of-the-art methods, notably achieving a 31.3% improvement in LPIPS.
Multi-Person 3D Pose Estimation from Multi-View Uncalibrated Depth Cameras
Jan 28, 2024We tackle the task of multi-view, multi-person 3D human pose estimation from a limited number of uncalibrated depth cameras. Recently, many approaches have been proposed for 3D human pose estimation from multi-view RGB cameras. However, these works (1) assume the number of RGB camera views is large enough for 3D reconstruction, (2) the cameras are calibrated, and (3) rely on ground truth 3D poses for training their regression model. In this work, we propose to leverage sparse, uncalibrated depth cameras providing RGBD video streams for 3D human pose estimation. We present a simple pipeline for Multi-View Depth Human Pose Estimation (MVD-HPE) for jointly predicting the camera poses and 3D human poses without training a deep 3D human pose regression model. This framework utilizes 3D Re-ID appearance features from RGBD images to formulate more accurate correspondences (for deriving camera positions) compared to using RGB-only features. We further propose (1) depth-guided camera-pose estimation by leveraging 3D rigid transformations as guidance and (2) depth-constrained 3D human pose estimation by utilizing depth-projected 3D points as an alternative objective for optimization. In order to evaluate our proposed pipeline, we collect three video sets of RGBD videos recorded from multiple sparse-view depth cameras and ground truth 3D poses are manually annotated. Experiments show that our proposed method outperforms the current 3D human pose regression-free pipelines in terms of both camera pose estimation and 3D human pose estimation.
F-RDW: Redirected Walking with Forecasting Future Position
Apr 07, 2023In order to serve better VR experiences to users, existing predictive methods of Redirected Walking (RDW) exploit future information to reduce the number of reset occurrences. However, such methods often impose a precondition during deployment, either in the virtual environment's layout or the user's walking direction, which constrains its universal applications. To tackle this challenge, we propose a novel mechanism F-RDW that is twofold: (1) forecasts the future information of a user in the virtual space without any assumptions, and (2) fuse this information while maneuvering existing RDW methods. The backbone of the first step is an LSTM-based model that ingests the user's spatial and eye-tracking data to predict the user's future position in the virtual space, and the following step feeds those predicted values into existing RDW methods (such as MPCRed, S2C, TAPF, and ARC) while respecting their internal mechanism in applicable ways.The results of our simulation test and user study demonstrate the significance of future information when using RDW in small physical spaces or complex environments. We prove that the proposed mechanism significantly reduces the number of resets and increases the traveled distance between resets, hence augmenting the redirection performance of all RDW methods explored in this work.
Time Will Tell: New Outlooks and A Baseline for Temporal Multi-View 3D Object Detection
Oct 05, 2022
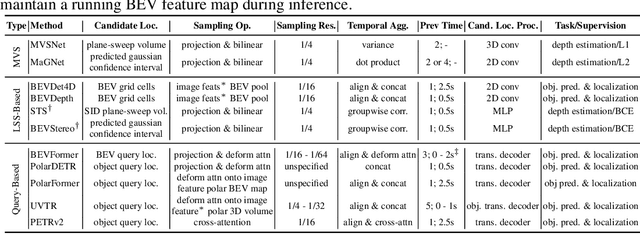
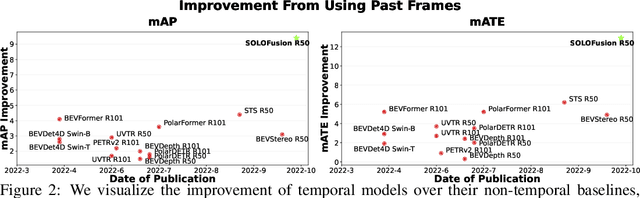
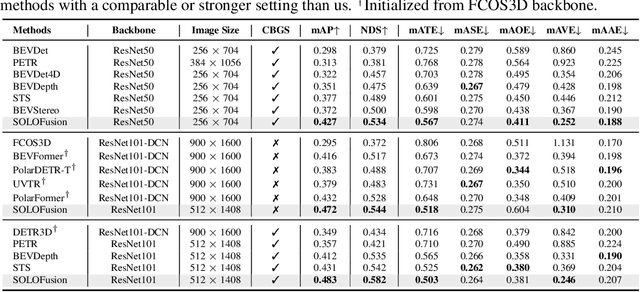
While recent camera-only 3D detection methods leverage multiple timesteps, the limited history they use significantly hampers the extent to which temporal fusion can improve object perception. Observing that existing works' fusion of multi-frame images are instances of temporal stereo matching, we find that performance is hindered by the interplay between 1) the low granularity of matching resolution and 2) the sub-optimal multi-view setup produced by limited history usage. Our theoretical and empirical analysis demonstrates that the optimal temporal difference between views varies significantly for different pixels and depths, making it necessary to fuse many timesteps over long-term history. Building on our investigation, we propose to generate a cost volume from a long history of image observations, compensating for the coarse but efficient matching resolution with a more optimal multi-view matching setup. Further, we augment the per-frame monocular depth predictions used for long-term, coarse matching with short-term, fine-grained matching and find that long and short term temporal fusion are highly complementary. While maintaining high efficiency, our framework sets new state-of-the-art on nuScenes, achieving first place on the test set and outperforming previous best art by 5.2% mAP and 3.7% NDS on the validation set. Code will be released $\href{https://github.com/Divadi/SOLOFusion}{here.}$
DetMatch: Two Teachers are Better Than One for Joint 2D and 3D Semi-Supervised Object Detection
Mar 17, 2022


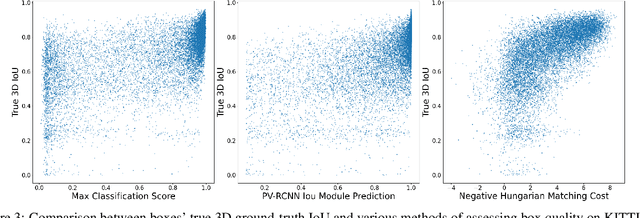
While numerous 3D detection works leverage the complementary relationship between RGB images and point clouds, developments in the broader framework of semi-supervised object recognition remain uninfluenced by multi-modal fusion. Current methods develop independent pipelines for 2D and 3D semi-supervised learning despite the availability of paired image and point cloud frames. Observing that the distinct characteristics of each sensor cause them to be biased towards detecting different objects, we propose DetMatch, a flexible framework for joint semi-supervised learning on 2D and 3D modalities. By identifying objects detected in both sensors, our pipeline generates a cleaner, more robust set of pseudo-labels that both demonstrates stronger performance and stymies single-modality error propagation. Further, we leverage the richer semantics of RGB images to rectify incorrect 3D class predictions and improve localization of 3D boxes. Evaluating on the challenging KITTI and Waymo datasets, we improve upon strong semi-supervised learning methods and observe higher quality pseudo-labels. Code will be released at https://github.com/Divadi/DetMatch
Flexible Networks for Learning Physical Dynamics of Deformable Objects
Dec 07, 2021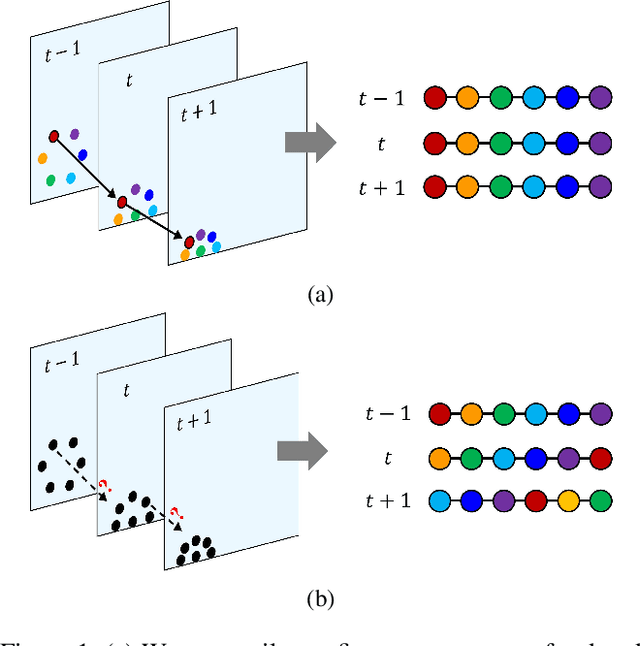
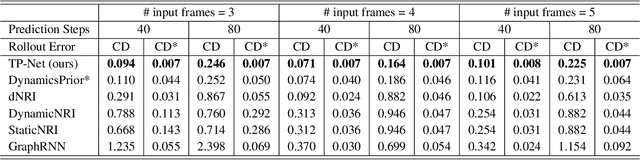
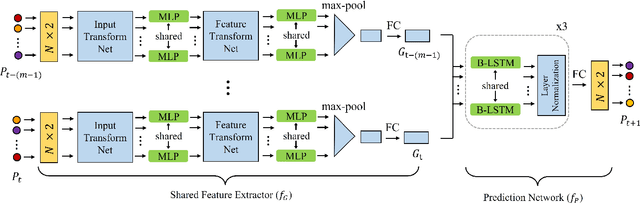

Learning the physical dynamics of deformable objects with particle-based representation has been the objective of many computational models in machine learning. While several state-of-the-art models have achieved this objective in simulated environments, most existing models impose a precondition, such that the input is a sequence of ordered point sets - i.e., the order of the points in each point set must be the same across the entire input sequence. This restrains the model to generalize to real-world data, which is considered to be a sequence of unordered point sets. In this paper, we propose a model named time-wise PointNet (TP-Net) that solves this problem by directly consuming a sequence of unordered point sets to infer the future state of a deformable object with particle-based representation. Our model consists of a shared feature extractor that extracts global features from each input point set in parallel and a prediction network that aggregates and reasons on these features for future prediction. The key concept of our approach is that we use global features rather than local features to achieve invariance to input permutations and ensure the stability and scalability of our model. Experiments demonstrate that our model achieves state-of-the-art performance in both synthetic dataset and in real-world dataset, with real-time prediction speed. We provide quantitative and qualitative analysis on why our approach is more effective and efficient than existing approaches.
Multi-Modality Task Cascade for 3D Object Detection
Jul 08, 2021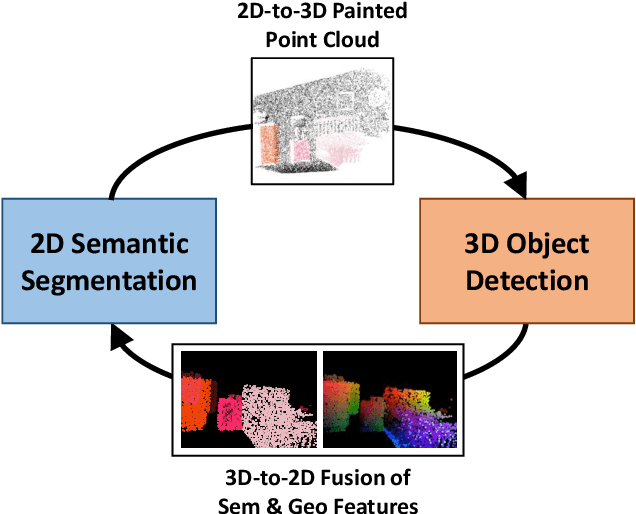
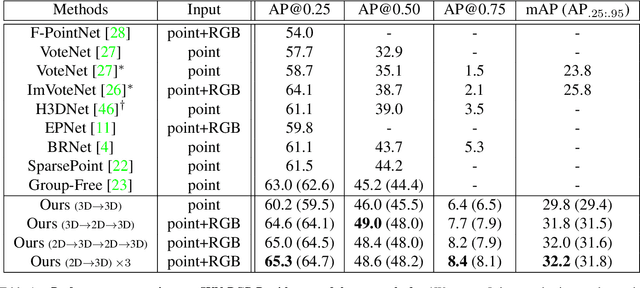
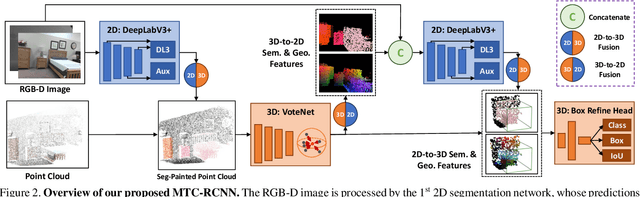

Point clouds and RGB images are naturally complementary modalities for 3D visual understanding - the former provides sparse but accurate locations of points on objects, while the latter contains dense color and texture information. Despite this potential for close sensor fusion, many methods train two models in isolation and use simple feature concatenation to represent 3D sensor data. This separated training scheme results in potentially sub-optimal performance and prevents 3D tasks from being used to benefit 2D tasks that are often useful on their own. To provide a more integrated approach, we propose a novel Multi-Modality Task Cascade network (MTC-RCNN) that leverages 3D box proposals to improve 2D segmentation predictions, which are then used to further refine the 3D boxes. We show that including a 2D network between two stages of 3D modules significantly improves both 2D and 3D task performance. Moreover, to prevent the 3D module from over-relying on the overfitted 2D predictions, we propose a dual-head 2D segmentation training and inference scheme, allowing the 2nd 3D module to learn to interpret imperfect 2D segmentation predictions. Evaluating our model on the challenging SUN RGB-D dataset, we improve upon state-of-the-art results of both single modality and fusion networks by a large margin ($\textbf{+3.8}$ mAP@0.5). Code will be released $\href{https://github.com/Divadi/MTC_RCNN}{\text{here.}}$