 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGive Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning
Jun 11, 2025Large Language Models (LLMs) are now integral across various domains and have demonstrated impressive performance. Progress, however, rests on the premise that benchmark scores are both accurate and reproducible. We demonstrate that the reproducibility of LLM performance is fragile: changing system configuration such as evaluation batch size, GPU count, and GPU version can introduce significant difference in the generated responses. This issue is especially pronounced in reasoning models, where minor rounding differences in early tokens can cascade into divergent chains of thought, ultimately affecting accuracy. For instance, under bfloat16 precision with greedy decoding, a reasoning model like DeepSeek-R1-Distill-Qwen-7B can exhibit up to 9% variation in accuracy and 9,000 tokens difference in response length due to differences in GPU count, type, and evaluation batch size. We trace the root cause of this variability to the non-associative nature of floating-point arithmetic under limited numerical precision. This work presents the first systematic investigation into how numerical precision affects reproducibility in LLM inference. Through carefully controlled experiments across various hardware, software, and precision settings, we quantify when and how model outputs diverge. Our analysis reveals that floating-point precision -- while critical for reproducibility -- is often neglected in evaluation practices. Inspired by this, we develop a lightweight inference pipeline, dubbed LayerCast, that stores weights in 16-bit precision but performs all computations in FP32, balancing memory efficiency with numerical stability. Code is available at https://github.com/nanomaoli/llm_reproducibility.
Prompt-Guided Mask Proposal for Two-Stage Open-Vocabulary Segmentation
Dec 13, 2024



We tackle the challenge of open-vocabulary segmentation, where we need to identify objects from a wide range of categories in different environments, using text prompts as our input. To overcome this challenge, existing methods often use multi-modal models like CLIP, which combine image and text features in a shared embedding space to bridge the gap between limited and extensive vocabulary recognition, resulting in a two-stage approach: In the first stage, a mask generator takes an input image to generate mask proposals, and the in the second stage the target mask is picked based on the query. However, the expected target mask may not exist in the generated mask proposals, which leads to an unexpected output mask. In our work, we propose a novel approach named Prompt-guided Mask Proposal (PMP) where the mask generator takes the input text prompts and generates masks guided by these prompts. Compared with mask proposals generated without input prompts, masks generated by PMP are better aligned with the input prompts. To realize PMP, we designed a cross-attention mechanism between text tokens and query tokens which is capable of generating prompt-guided mask proposals after each decoding. We combined our PMP with several existing works employing a query-based segmentation backbone and the experiments on five benchmark datasets demonstrate the effectiveness of this approach, showcasing significant improvements over the current two-stage models (1% ~ 3% absolute performance gain in terms of mIOU). The steady improvement in performance across these benchmarks indicates the effective generalization of our proposed lightweight prompt-aware method.
Efficient Self-Improvement in Multimodal Large Language Models: A Model-Level Judge-Free Approach
Nov 26, 2024



Self-improvement in multimodal large language models (MLLMs) is crucial for enhancing their reliability and robustness. However, current methods often rely heavily on MLLMs themselves as judges, leading to high computational costs and potential pitfalls like reward hacking and model collapse. This paper introduces a novel, model-level judge-free self-improvement framework. Our approach employs a controlled feedback mechanism while eliminating the need for MLLMs in the verification loop. We generate preference learning pairs using a controllable hallucination mechanism and optimize data quality by leveraging lightweight, contrastive language-image encoders to evaluate and reverse pairs when necessary. Evaluations across public benchmarks and our newly introduced IC dataset designed to challenge hallucination control demonstrate that our model outperforms conventional techniques. We achieve superior precision and recall with significantly lower computational demands. This method offers an efficient pathway to scalable self-improvement in MLLMs, balancing performance gains with reduced resource requirements.
Quadratic Is Not What You Need For Multimodal Large Language Models
Oct 08, 2024



In the past year, the capabilities of Multimodal Large Language Models (MLLMs) have significantly improved across various aspects. However, constrained by the quadratic growth of computation in LLMs as the number of tokens increases, efficiency has become a bottleneck for further scaling MLLMs. Although recent efforts have been made to prune visual tokens or use more lightweight LLMs to reduce computation, the problem of quadratic growth in computation with the increase of visual tokens still persists. To address this, we propose a novel approach: instead of reducing the input visual tokens for LLMs, we focus on pruning vision-related computations within the LLMs. After pruning, the computation growth in the LLM is no longer quadratic with the increase of visual tokens, but linear. Surprisingly, we found that after applying such extensive pruning, the capabilities of MLLMs are comparable with the original one and even superior on some benchmarks with only 25% of the computation. This finding opens up the possibility for MLLMs to incorporate much denser visual tokens. Additionally, based on this finding, we further analyzed some architectural design deficiencies in existing MLLMs and proposed promising improvements. To the best of our knowledge, this is the first study to investigate the computational redundancy in the LLM's vision component of MLLMs. Code and checkpoints will be released soon.
Multi-Person 3D Pose Estimation from Multi-View Uncalibrated Depth Cameras
Jan 28, 2024We tackle the task of multi-view, multi-person 3D human pose estimation from a limited number of uncalibrated depth cameras. Recently, many approaches have been proposed for 3D human pose estimation from multi-view RGB cameras. However, these works (1) assume the number of RGB camera views is large enough for 3D reconstruction, (2) the cameras are calibrated, and (3) rely on ground truth 3D poses for training their regression model. In this work, we propose to leverage sparse, uncalibrated depth cameras providing RGBD video streams for 3D human pose estimation. We present a simple pipeline for Multi-View Depth Human Pose Estimation (MVD-HPE) for jointly predicting the camera poses and 3D human poses without training a deep 3D human pose regression model. This framework utilizes 3D Re-ID appearance features from RGBD images to formulate more accurate correspondences (for deriving camera positions) compared to using RGB-only features. We further propose (1) depth-guided camera-pose estimation by leveraging 3D rigid transformations as guidance and (2) depth-constrained 3D human pose estimation by utilizing depth-projected 3D points as an alternative objective for optimization. In order to evaluate our proposed pipeline, we collect three video sets of RGBD videos recorded from multiple sparse-view depth cameras and ground truth 3D poses are manually annotated. Experiments show that our proposed method outperforms the current 3D human pose regression-free pipelines in terms of both camera pose estimation and 3D human pose estimation.
3D-CLFusion: Fast Text-to-3D Rendering with Contrastive Latent Diffusion
Mar 21, 2023



We tackle the task of text-to-3D creation with pre-trained latent-based NeRFs (NeRFs that generate 3D objects given input latent code). Recent works such as DreamFusion and Magic3D have shown great success in generating 3D content using NeRFs and text prompts, but the current approach of optimizing a NeRF for every text prompt is 1) extremely time-consuming and 2) often leads to low-resolution outputs. To address these challenges, we propose a novel method named 3D-CLFusion which leverages the pre-trained latent-based NeRFs and performs fast 3D content creation in less than a minute. In particular, we introduce a latent diffusion prior network for learning the w latent from the input CLIP text/image embeddings. This pipeline allows us to produce the w latent without further optimization during inference and the pre-trained NeRF is able to perform multi-view high-resolution 3D synthesis based on the latent. We note that the novelty of our model lies in that we introduce contrastive learning during training the diffusion prior which enables the generation of the valid view-invariant latent code. We demonstrate through experiments the effectiveness of our proposed view-invariant diffusion process for fast text-to-3D creation, e.g., 100 times faster than DreamFusion. We note that our model is able to serve as the role of a plug-and-play tool for text-to-3D with pre-trained NeRFs.
3D-Aware Encoding for Style-based Neural Radiance Fields
Nov 12, 2022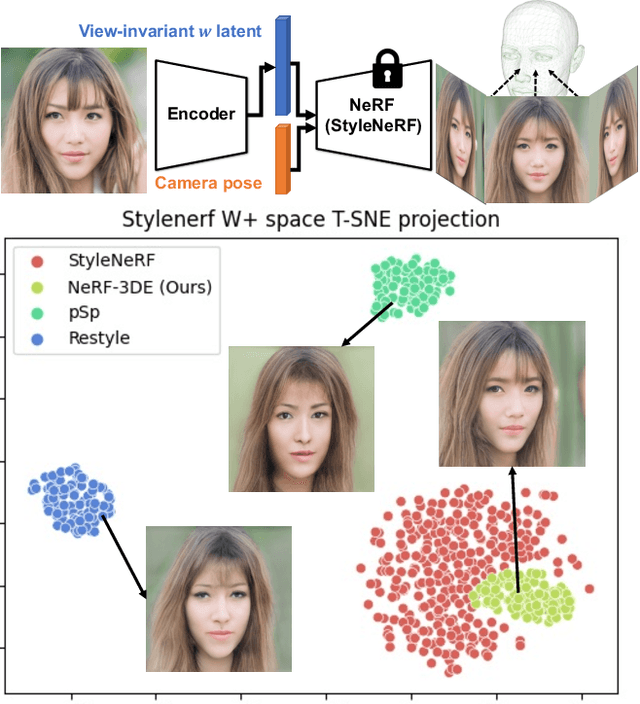
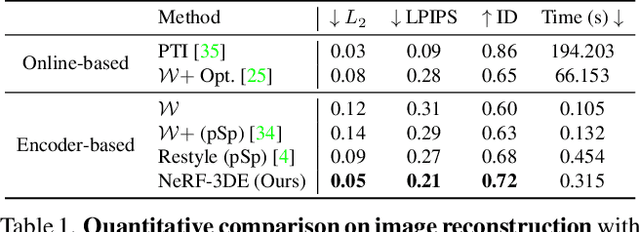
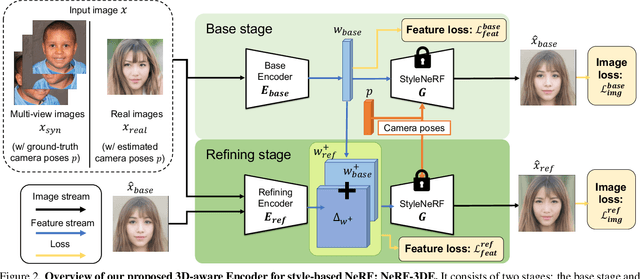
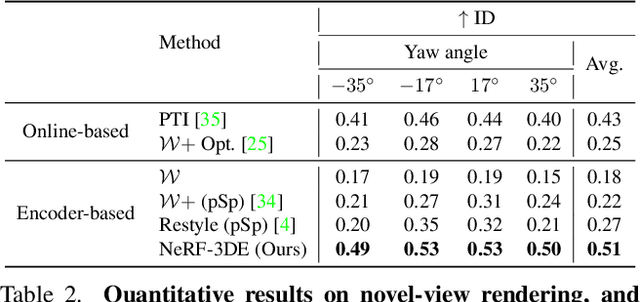
We tackle the task of NeRF inversion for style-based neural radiance fields, (e.g., StyleNeRF). In the task, we aim to learn an inversion function to project an input image to the latent space of a NeRF generator and then synthesize novel views of the original image based on the latent code. Compared with GAN inversion for 2D generative models, NeRF inversion not only needs to 1) preserve the identity of the input image, but also 2) ensure 3D consistency in generated novel views. This requires the latent code obtained from the single-view image to be invariant across multiple views. To address this new challenge, we propose a two-stage encoder for style-based NeRF inversion. In the first stage, we introduce a base encoder that converts the input image to a latent code. To ensure the latent code is view-invariant and is able to synthesize 3D consistent novel view images, we utilize identity contrastive learning to train the base encoder. Second, to better preserve the identity of the input image, we introduce a refining encoder to refine the latent code and add finer details to the output image. Importantly note that the novelty of this model lies in the design of its first-stage encoder which produces the closest latent code lying on the latent manifold and thus the refinement in the second stage would be close to the NeRF manifold. Through extensive experiments, we demonstrate that our proposed two-stage encoder qualitatively and quantitatively exhibits superiority over the existing encoders for inversion in both image reconstruction and novel-view rendering.
Domain Adaptive Hand Keypoint and Pixel Localization in the Wild
Mar 21, 2022
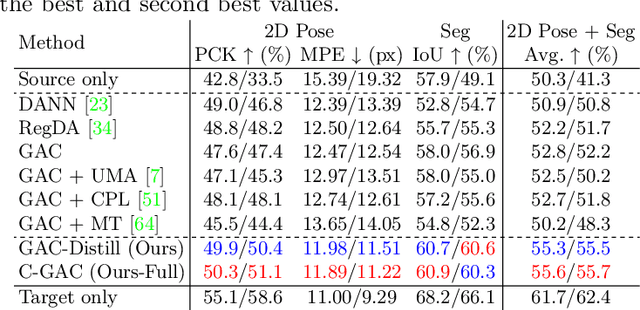
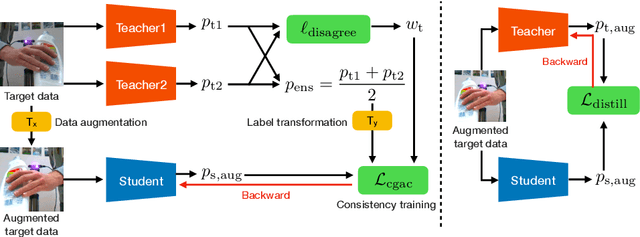
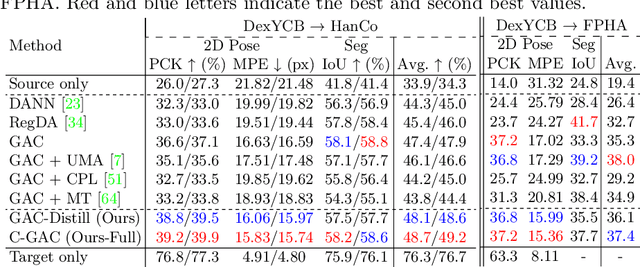
We aim to improve the performance of regressing hand keypoints and segmenting pixel-level hand masks under new imaging conditions (e.g., outdoors) when we only have labeled images taken under very different conditions (e.g., indoors). In the real world, it is important that the model trained for both tasks works under various imaging conditions. However, their variation covered by existing labeled hand datasets is limited. Thus, it is necessary to adapt the model trained on the labeled images (source) to unlabeled images (target) with unseen imaging conditions. While self-training domain adaptation methods (i.e., learning from the unlabeled target images in a self-supervised manner) have been developed for both tasks, their training may degrade performance when the predictions on the target images are noisy. To avoid this, it is crucial to assign a low importance (confidence) weight to the noisy predictions during self-training. In this paper, we propose to utilize the divergence of two predictions to estimate the confidence of the target image for both tasks. These predictions are given from two separate networks, and their divergence helps identify the noisy predictions. To integrate our proposed confidence estimation into self-training, we propose a teacher-student framework where the two networks (teachers) provide supervision to a network (student) for self-training, and the teachers are learned from the student by knowledge distillation. Our experiments show its superiority over state-of-the-art methods in adaptation settings with different lighting, grasping objects, backgrounds, and camera viewpoints. Our method improves by 4% the multi-task score on HO3D compared to the latest adversarial adaptation method. We also validate our method on Ego4D, egocentric videos with rapid changes in imaging conditions outdoors.
Cross-Domain Object Detection via Adaptive Self-Training
Nov 25, 2021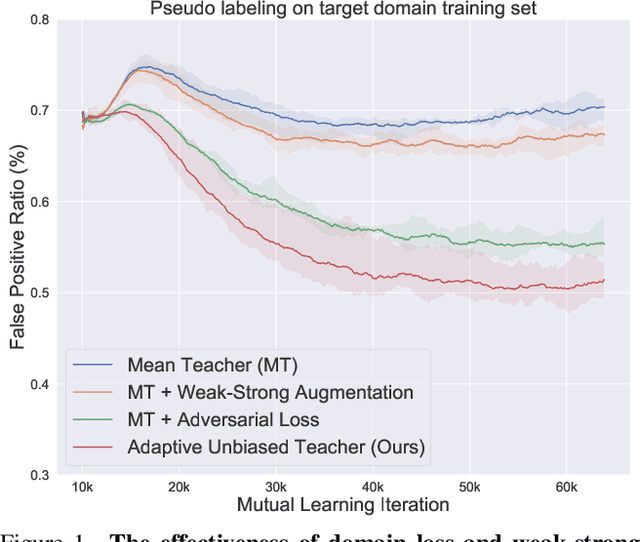
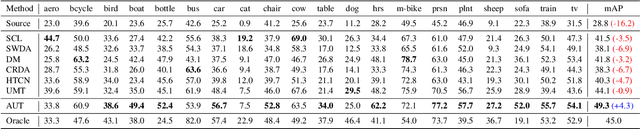
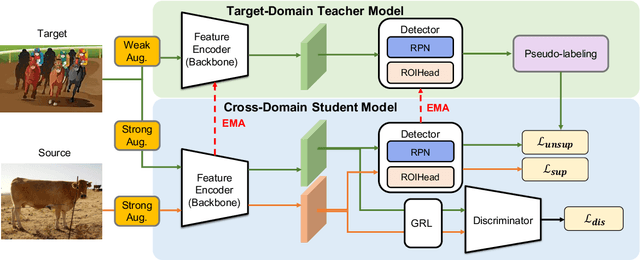
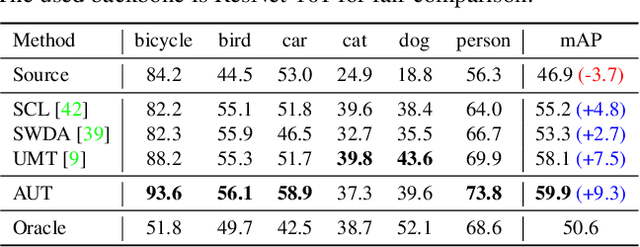
We tackle the problem of domain adaptation in object detection, where there is a significant domain shift between a source (a domain with supervision) and a target domain (a domain of interest without supervision). As a widely adopted domain adaptation method, the self-training teacher-student framework (a student model learns from pseudo labels generated from a teacher model) has yielded remarkable accuracy gain on the target domain. However, it still suffers from the large amount of low-quality pseudo labels (e.g., false positives) generated from the teacher due to its bias toward the source domain. To address this issue, we propose a self-training framework called Adaptive Unbiased Teacher (AUT) leveraging adversarial learning and weak-strong data augmentation during mutual learning to address domain shift. Specifically, we employ feature-level adversarial training in the student model, ensuring features extracted from the source and target domains share similar statistics. This enables the student model to capture domain-invariant features. Furthermore, we apply weak-strong augmentation and mutual learning between the teacher model on the target domain and the student model on both domains. This enables the teacher model to gradually benefit from the student model without suffering domain shift. We show that AUT demonstrates superiority over all existing approaches and even Oracle (fully supervised) models by a large margin. For example, we achieve 50.9% (49.3%) mAP on Foggy Cityscape (Clipart1K), which is 9.2% (5.2%) and 8.2% (11.0%) higher than previous state-of-the-art and Oracle, respectively
Wide-Baseline Multi-Camera Calibration using Person Re-Identification
Apr 17, 2021
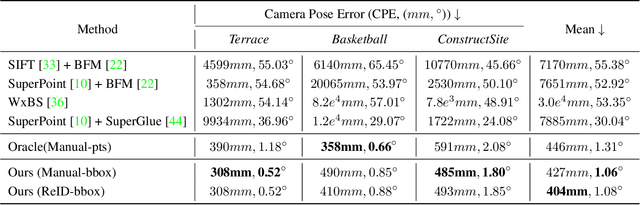
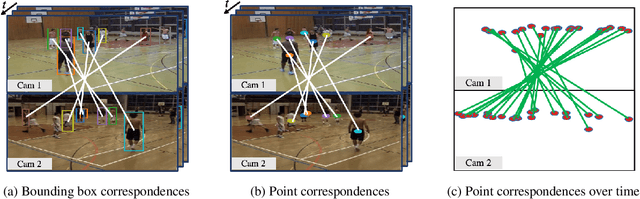
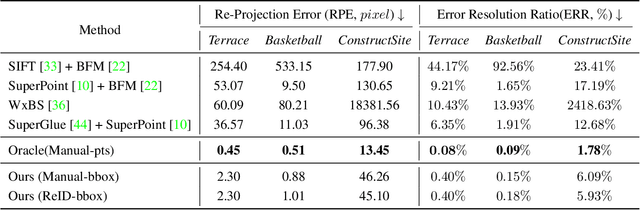
We address the problem of estimating the 3D pose of a network of cameras for large-environment wide-baseline scenarios, e.g., cameras for construction sites, sports stadiums, and public spaces. This task is challenging since detecting and matching the same 3D keypoint observed from two very different camera views is difficult, making standard structure-from-motion (SfM) pipelines inapplicable. In such circumstances, treating people in the scene as "keypoints" and associating them across different camera views can be an alternative method for obtaining correspondences. Based on this intuition, we propose a method that uses ideas from person re-identification (re-ID) for wide-baseline camera calibration. Our method first employs a re-ID method to associate human bounding boxes across cameras, then converts bounding box correspondences to point correspondences, and finally solves for camera pose using multi-view geometry and bundle adjustment. Since our method does not require specialized calibration targets except for visible people, it applies to situations where frequent calibration updates are required. We perform extensive experiments on datasets captured from scenes of different sizes, camera settings (indoor and outdoor), and human activities (walking, playing basketball, construction). Experiment results show that our method achieves similar performance to standard SfM methods relying on manually labeled point correspondences.