 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniFusion: Vision-Language Model as Unified Encoder in Image Generation
Oct 14, 2025
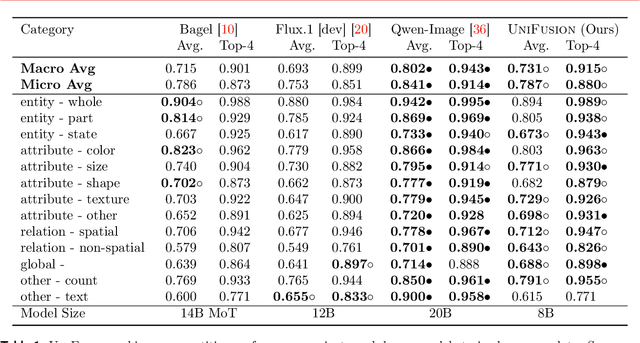

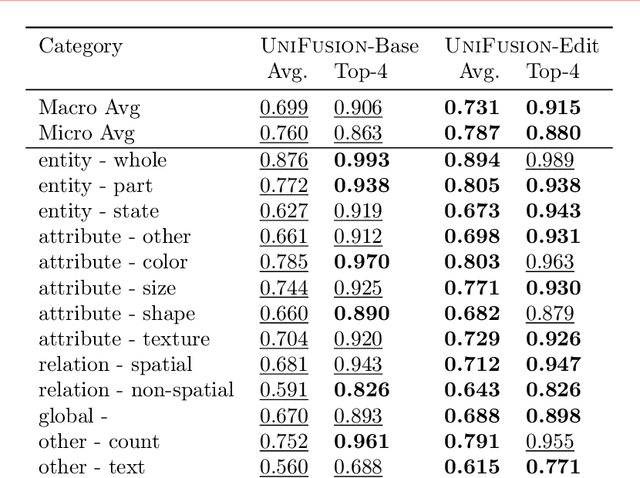
Although recent advances in visual generation have been remarkable, most existing architectures still depend on distinct encoders for images and text. This separation constrains diffusion models' ability to perform cross-modal reasoning and knowledge transfer. Prior attempts to bridge this gap often use the last layer information from VLM, employ multiple visual encoders, or train large unified models jointly for text and image generation, which demands substantial computational resources and large-scale data, limiting its accessibility.We present UniFusion, a diffusion-based generative model conditioned on a frozen large vision-language model (VLM) that serves as a unified multimodal encoder. At the core of UniFusion is the Layerwise Attention Pooling (LAP) mechanism that extracts both high level semantics and low level details from text and visual tokens of a frozen VLM to condition a diffusion generative model. We demonstrate that LAP outperforms other shallow fusion architectures on text-image alignment for generation and faithful transfer of visual information from VLM to the diffusion model which is key for editing. We propose VLM-Enabled Rewriting Injection with Flexibile Inference (VERIFI), which conditions a diffusion transformer (DiT) only on the text tokens generated by the VLM during in-model prompt rewriting. VERIFI combines the alignment of the conditioning distribution with the VLM's reasoning capabilities for increased capabilities and flexibility at inference. In addition, finetuning on editing task not only improves text-image alignment for generation, indicative of cross-modality knowledge transfer, but also exhibits tremendous generalization capabilities. Our model when trained on single image editing, zero-shot generalizes to multiple image references further motivating the unified encoder design of UniFusion.
Prompt-Guided Mask Proposal for Two-Stage Open-Vocabulary Segmentation
Dec 13, 2024



We tackle the challenge of open-vocabulary segmentation, where we need to identify objects from a wide range of categories in different environments, using text prompts as our input. To overcome this challenge, existing methods often use multi-modal models like CLIP, which combine image and text features in a shared embedding space to bridge the gap between limited and extensive vocabulary recognition, resulting in a two-stage approach: In the first stage, a mask generator takes an input image to generate mask proposals, and the in the second stage the target mask is picked based on the query. However, the expected target mask may not exist in the generated mask proposals, which leads to an unexpected output mask. In our work, we propose a novel approach named Prompt-guided Mask Proposal (PMP) where the mask generator takes the input text prompts and generates masks guided by these prompts. Compared with mask proposals generated without input prompts, masks generated by PMP are better aligned with the input prompts. To realize PMP, we designed a cross-attention mechanism between text tokens and query tokens which is capable of generating prompt-guided mask proposals after each decoding. We combined our PMP with several existing works employing a query-based segmentation backbone and the experiments on five benchmark datasets demonstrate the effectiveness of this approach, showcasing significant improvements over the current two-stage models (1% ~ 3% absolute performance gain in terms of mIOU). The steady improvement in performance across these benchmarks indicates the effective generalization of our proposed lightweight prompt-aware method.
Efficient Self-Improvement in Multimodal Large Language Models: A Model-Level Judge-Free Approach
Nov 26, 2024



Self-improvement in multimodal large language models (MLLMs) is crucial for enhancing their reliability and robustness. However, current methods often rely heavily on MLLMs themselves as judges, leading to high computational costs and potential pitfalls like reward hacking and model collapse. This paper introduces a novel, model-level judge-free self-improvement framework. Our approach employs a controlled feedback mechanism while eliminating the need for MLLMs in the verification loop. We generate preference learning pairs using a controllable hallucination mechanism and optimize data quality by leveraging lightweight, contrastive language-image encoders to evaluate and reverse pairs when necessary. Evaluations across public benchmarks and our newly introduced IC dataset designed to challenge hallucination control demonstrate that our model outperforms conventional techniques. We achieve superior precision and recall with significantly lower computational demands. This method offers an efficient pathway to scalable self-improvement in MLLMs, balancing performance gains with reduced resource requirements.
Quadratic Is Not What You Need For Multimodal Large Language Models
Oct 08, 2024



In the past year, the capabilities of Multimodal Large Language Models (MLLMs) have significantly improved across various aspects. However, constrained by the quadratic growth of computation in LLMs as the number of tokens increases, efficiency has become a bottleneck for further scaling MLLMs. Although recent efforts have been made to prune visual tokens or use more lightweight LLMs to reduce computation, the problem of quadratic growth in computation with the increase of visual tokens still persists. To address this, we propose a novel approach: instead of reducing the input visual tokens for LLMs, we focus on pruning vision-related computations within the LLMs. After pruning, the computation growth in the LLM is no longer quadratic with the increase of visual tokens, but linear. Surprisingly, we found that after applying such extensive pruning, the capabilities of MLLMs are comparable with the original one and even superior on some benchmarks with only 25% of the computation. This finding opens up the possibility for MLLMs to incorporate much denser visual tokens. Additionally, based on this finding, we further analyzed some architectural design deficiencies in existing MLLMs and proposed promising improvements. To the best of our knowledge, this is the first study to investigate the computational redundancy in the LLM's vision component of MLLMs. Code and checkpoints will be released soon.
Towards Enhanced Controllability of Diffusion Models
Mar 15, 2023Denoising Diffusion models have shown remarkable capabilities in generating realistic, high-quality and diverse images. However, the extent of controllability during generation is underexplored. Inspired by techniques based on GAN latent space for image manipulation, we train a diffusion model conditioned on two latent codes, a spatial content mask and a flattened style embedding. We rely on the inductive bias of the progressive denoising process of diffusion models to encode pose/layout information in the spatial structure mask and semantic/style information in the style code. We propose two generic sampling techniques for improving controllability. We extend composable diffusion models to allow for some dependence between conditional inputs, to improve the quality of generations while also providing control over the amount of guidance from each latent code and their joint distribution. We also propose timestep dependent weight scheduling for content and style latents to further improve the translations. We observe better controllability compared to existing methods and show that without explicit training objectives, diffusion models can be used for effective image manipulation and image translation.
Controlled and Conditional Text to Image Generation with Diffusion Prior
Feb 23, 2023Denoising Diffusion models have shown remarkable performance in generating diverse, high quality images from text. Numerous techniques have been proposed on top of or in alignment with models like Stable Diffusion and Imagen that generate images directly from text. A lesser explored approach is DALLE-2's two step process comprising a Diffusion Prior that generates a CLIP image embedding from text and a Diffusion Decoder that generates an image from a CLIP image embedding. We explore the capabilities of the Diffusion Prior and the advantages of an intermediate CLIP representation. We observe that Diffusion Prior can be used in a memory and compute efficient way to constrain the generation to a specific domain without altering the larger Diffusion Decoder. Moreover, we show that the Diffusion Prior can be trained with additional conditional information such as color histogram to further control the generation. We show quantitatively and qualitatively that the proposed approaches perform better than prompt engineering for domain specific generation and existing baselines for color conditioned generation. We believe that our observations and results will instigate further research into the diffusion prior and uncover more of its capabilities.
PRedItOR: Text Guided Image Editing with Diffusion Prior
Feb 15, 2023



Diffusion models have shown remarkable capabilities in generating high quality and creative images conditioned on text. An interesting application of such models is structure preserving text guided image editing. Existing approaches rely on text conditioned diffusion models such as Stable Diffusion or Imagen and require compute intensive optimization of text embeddings or fine-tuning the model weights for text guided image editing. We explore text guided image editing with a Hybrid Diffusion Model (HDM) architecture similar to DALLE-2. Our architecture consists of a diffusion prior model that generates CLIP image embedding conditioned on a text prompt and a custom Latent Diffusion Model trained to generate images conditioned on CLIP image embedding. We discover that the diffusion prior model can be used to perform text guided conceptual edits on the CLIP image embedding space without any finetuning or optimization. We combine this with structure preserving edits on the image decoder using existing approaches such as reverse DDIM to perform text guided image editing. Our approach, PRedItOR does not require additional inputs, fine-tuning, optimization or objectives and shows on par or better results than baselines qualitatively and quantitatively. We provide further analysis and understanding of the diffusion prior model and believe this opens up new possibilities in diffusion models research.
Uncovering the Disentanglement Capability in Text-to-Image Diffusion Models
Dec 16, 2022Generative models have been widely studied in computer vision. Recently, diffusion models have drawn substantial attention due to the high quality of their generated images. A key desired property of image generative models is the ability to disentangle different attributes, which should enable modification towards a style without changing the semantic content, and the modification parameters should generalize to different images. Previous studies have found that generative adversarial networks (GANs) are inherently endowed with such disentanglement capability, so they can perform disentangled image editing without re-training or fine-tuning the network. In this work, we explore whether diffusion models are also inherently equipped with such a capability. Our finding is that for stable diffusion models, by partially changing the input text embedding from a neutral description (e.g., "a photo of person") to one with style (e.g., "a photo of person with smile") while fixing all the Gaussian random noises introduced during the denoising process, the generated images can be modified towards the target style without changing the semantic content. Based on this finding, we further propose a simple, light-weight image editing algorithm where the mixing weights of the two text embeddings are optimized for style matching and content preservation. This entire process only involves optimizing over around 50 parameters and does not fine-tune the diffusion model itself. Experiments show that the proposed method can modify a wide range of attributes, with the performance outperforming diffusion-model-based image-editing algorithms that require fine-tuning. The optimized weights generalize well to different images. Our code is publicly available at https://github.com/UCSB-NLP-Chang/DiffusionDisentanglement.
Fine-grained Image Captioning with CLIP Reward
May 26, 2022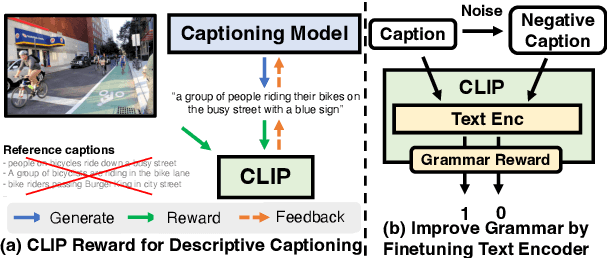

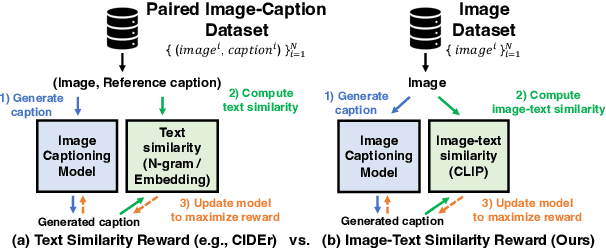
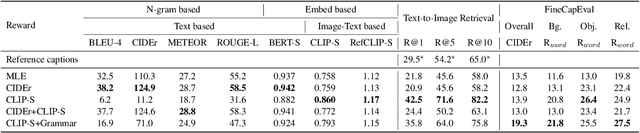
Modern image captioning models are usually trained with text similarity objectives. However, since reference captions in public datasets often describe the most salient common objects, models trained with text similarity objectives tend to ignore specific and detailed aspects of an image that distinguish it from others. Toward more descriptive and distinctive caption generation, we propose using CLIP, a multimodal encoder trained on huge image-text pairs from web, to calculate multimodal similarity and use it as a reward function. We also propose a simple finetuning strategy of the CLIP text encoder to improve grammar that does not require extra text annotation. This completely eliminates the need for reference captions during the reward computation. To comprehensively evaluate descriptive captions, we introduce FineCapEval, a new dataset for caption evaluation with fine-grained criteria: overall, background, object, relations. In our experiments on text-to-image retrieval and FineCapEval, the proposed CLIP-guided model generates more distinctive captions than the CIDEr-optimized model. We also show that our unsupervised grammar finetuning of the CLIP text encoder alleviates the degeneration problem of the naive CLIP reward. Lastly, we show human analysis where the annotators strongly prefer the CLIP reward to the CIDEr and MLE objectives according to various criteria. Code and Data: https://github.com/j-min/CLIP-Caption-Reward
StyleBabel: Artistic Style Tagging and Captioning
Mar 11, 2022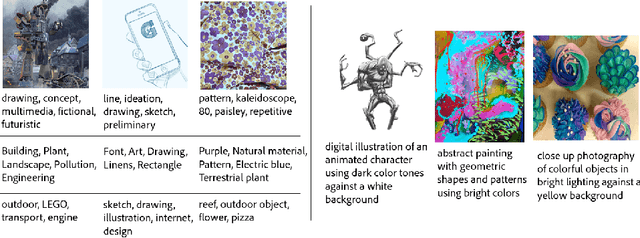
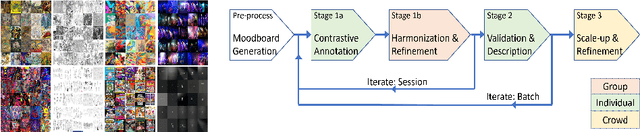

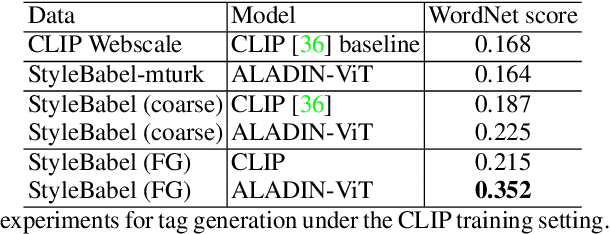
We present StyleBabel, a unique open access dataset of natural language captions and free-form tags describing the artistic style of over 135K digital artworks, collected via a novel participatory method from experts studying at specialist art and design schools. StyleBabel was collected via an iterative method, inspired by `Grounded Theory': a qualitative approach that enables annotation while co-evolving a shared language for fine-grained artistic style attribute description. We demonstrate several downstream tasks for StyleBabel, adapting the recent ALADIN architecture for fine-grained style similarity, to train cross-modal embeddings for: 1) free-form tag generation; 2) natural language description of artistic style; 3) fine-grained text search of style. To do so, we extend ALADIN with recent advances in Visual Transformer (ViT) and cross-modal representation learning, achieving a state of the art accuracy in fine-grained style retrieval.