 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCube: A Roblox View of 3D Intelligence
Mar 19, 2025



Foundation models trained on vast amounts of data have demonstrated remarkable reasoning and generation capabilities in the domains of text, images, audio and video. Our goal at Roblox is to build such a foundation model for 3D intelligence, a model that can support developers in producing all aspects of a Roblox experience, from generating 3D objects and scenes to rigging characters for animation to producing programmatic scripts describing object behaviors. We discuss three key design requirements for such a 3D foundation model and then present our first step towards building such a model. We expect that 3D geometric shapes will be a core data type and describe our solution for 3D shape tokenizer. We show how our tokenization scheme can be used in applications for text-to-shape generation, shape-to-text generation and text-to-scene generation. We demonstrate how these applications can collaborate with existing large language models (LLMs) to perform scene analysis and reasoning. We conclude with a discussion outlining our path to building a fully unified foundation model for 3D intelligence.
Controlled and Conditional Text to Image Generation with Diffusion Prior
Feb 23, 2023Denoising Diffusion models have shown remarkable performance in generating diverse, high quality images from text. Numerous techniques have been proposed on top of or in alignment with models like Stable Diffusion and Imagen that generate images directly from text. A lesser explored approach is DALLE-2's two step process comprising a Diffusion Prior that generates a CLIP image embedding from text and a Diffusion Decoder that generates an image from a CLIP image embedding. We explore the capabilities of the Diffusion Prior and the advantages of an intermediate CLIP representation. We observe that Diffusion Prior can be used in a memory and compute efficient way to constrain the generation to a specific domain without altering the larger Diffusion Decoder. Moreover, we show that the Diffusion Prior can be trained with additional conditional information such as color histogram to further control the generation. We show quantitatively and qualitatively that the proposed approaches perform better than prompt engineering for domain specific generation and existing baselines for color conditioned generation. We believe that our observations and results will instigate further research into the diffusion prior and uncover more of its capabilities.
StyleBabel: Artistic Style Tagging and Captioning
Mar 11, 2022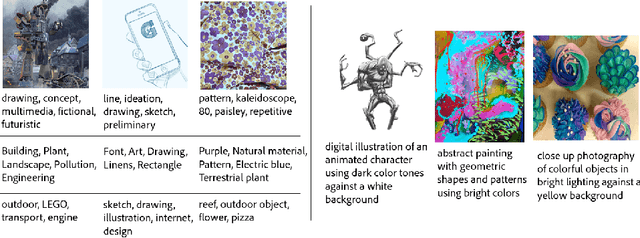
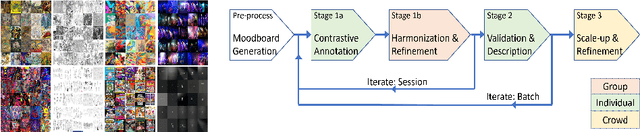

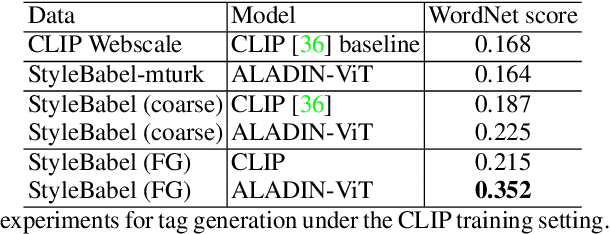
We present StyleBabel, a unique open access dataset of natural language captions and free-form tags describing the artistic style of over 135K digital artworks, collected via a novel participatory method from experts studying at specialist art and design schools. StyleBabel was collected via an iterative method, inspired by `Grounded Theory': a qualitative approach that enables annotation while co-evolving a shared language for fine-grained artistic style attribute description. We demonstrate several downstream tasks for StyleBabel, adapting the recent ALADIN architecture for fine-grained style similarity, to train cross-modal embeddings for: 1) free-form tag generation; 2) natural language description of artistic style; 3) fine-grained text search of style. To do so, we extend ALADIN with recent advances in Visual Transformer (ViT) and cross-modal representation learning, achieving a state of the art accuracy in fine-grained style retrieval.