 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCubePart: An Open-Vocabulary Part-Controllable 3D Generator
May 27, 2026Interactive 3D assets used in games and simulation are typically decomposed into specific semantic parts to support animation, physics, and scripted behaviors, yet most generative 3D models produce either monolithic meshes or arbitrary part decompositions that cannot be aligned with application-specific requirements. We present CubePart, a generative framework for open-vocabulary, part-controllable 3D mesh generation that exposes part structure as an explicit inference-time control signal. Given a global text prompt and a user-defined parts schema expressed as an open-ended list of part names, our method generates a set of meshes - one per schema element - that assemble into a coherent object while respecting the specified semantic structure. To enable this capability, we introduce a scalable data pipeline to construct a large open-vocabulary, part-labeled 3D dataset, along with a two-stage generative architecture that separates global shape synthesis from part-level decoding. We demonstrate that the resulting assets can be directly integrated into game engines and driven by animation and behavior scripts without manual post-processing. Project Page: https://cubepart.github.io/
Efficient Autoregressive Shape Generation via Octree-Based Adaptive Tokenization
Apr 03, 2025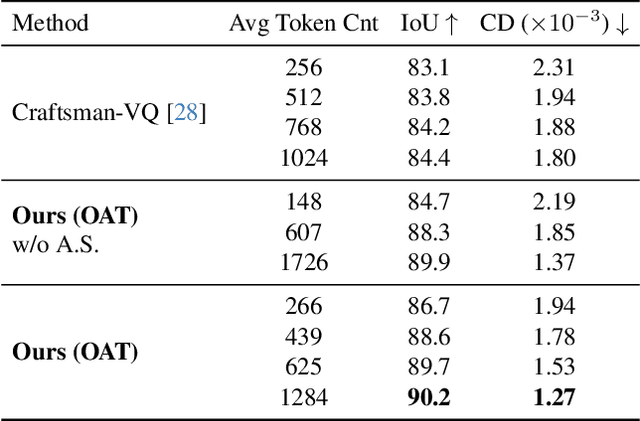

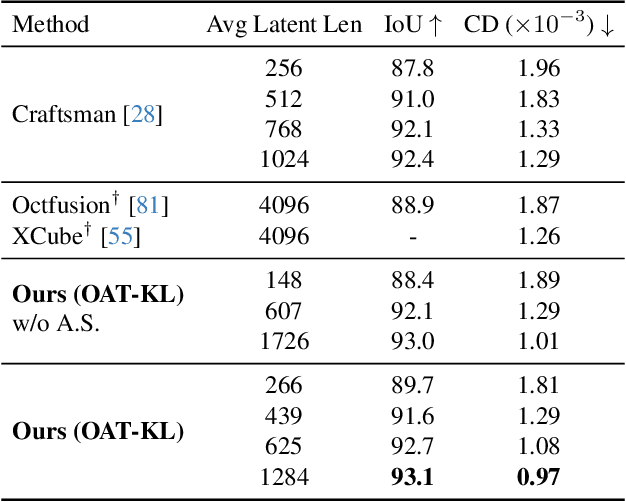
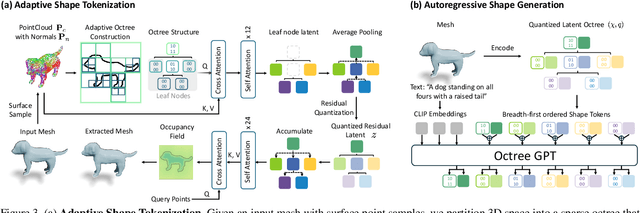
Many 3D generative models rely on variational autoencoders (VAEs) to learn compact shape representations. However, existing methods encode all shapes into a fixed-size token, disregarding the inherent variations in scale and complexity across 3D data. This leads to inefficient latent representations that can compromise downstream generation. We address this challenge by introducing Octree-based Adaptive Tokenization, a novel framework that adjusts the dimension of latent representations according to shape complexity. Our approach constructs an adaptive octree structure guided by a quadric-error-based subdivision criterion and allocates a shape latent vector to each octree cell using a query-based transformer. Building upon this tokenization, we develop an octree-based autoregressive generative model that effectively leverages these variable-sized representations in shape generation. Extensive experiments demonstrate that our approach reduces token counts by 50% compared to fixed-size methods while maintaining comparable visual quality. When using a similar token length, our method produces significantly higher-quality shapes. When incorporated with our downstream generative model, our method creates more detailed and diverse 3D content than existing approaches.
Cube: A Roblox View of 3D Intelligence
Mar 19, 2025



Foundation models trained on vast amounts of data have demonstrated remarkable reasoning and generation capabilities in the domains of text, images, audio and video. Our goal at Roblox is to build such a foundation model for 3D intelligence, a model that can support developers in producing all aspects of a Roblox experience, from generating 3D objects and scenes to rigging characters for animation to producing programmatic scripts describing object behaviors. We discuss three key design requirements for such a 3D foundation model and then present our first step towards building such a model. We expect that 3D geometric shapes will be a core data type and describe our solution for 3D shape tokenizer. We show how our tokenization scheme can be used in applications for text-to-shape generation, shape-to-text generation and text-to-scene generation. We demonstrate how these applications can collaborate with existing large language models (LLMs) to perform scene analysis and reasoning. We conclude with a discussion outlining our path to building a fully unified foundation model for 3D intelligence.
Supervised Deep Sparse Coding Networks
May 23, 2017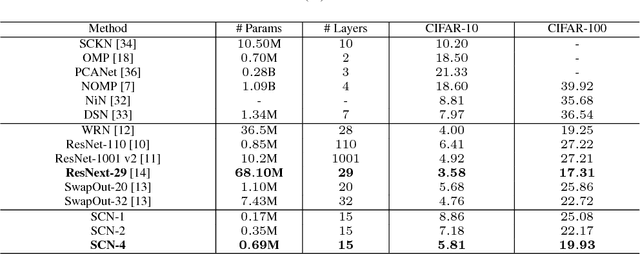
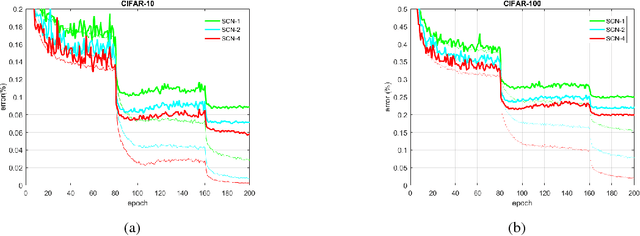
In this paper, we describe the deep sparse coding network (SCN), a novel deep network that encodes intermediate representations with nonnegative sparse coding. The SCN is built upon a number of cascading bottleneck modules, where each module consists of two sparse coding layers with relatively wide and slim dictionaries that are specialized to produce high dimensional discriminative features and low dimensional representations for clustering, respectively. During training, both the dictionaries and regularization parameters are optimized with an end-to-end supervised learning algorithm based on multilevel optimization. Effectiveness of an SCN with seven bottleneck modules is verified on several popular benchmark datasets. Remarkably, with few parameters to learn, our SCN achieves 5.81% and 19.93% classification error rate on CIFAR-10 and CIFAR-100, respectively.
Sparse Coding with Fast Image Alignment via Large Displacement Optical Flow
Dec 21, 2015
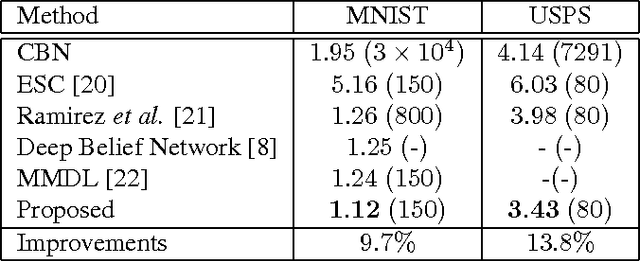
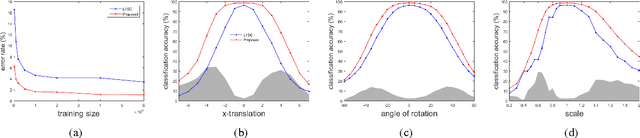
Sparse representation-based classifiers have shown outstanding accuracy and robustness in image classification tasks even with the presence of intense noise and occlusion. However, it has been discovered that the performance degrades significantly either when test image is not aligned with the dictionary atoms or the dictionary atoms themselves are not aligned with each other, in which cases the sparse linear representation assumption fails. In this paper, having both training and test images misaligned, we introduce a novel sparse coding framework that is able to efficiently adapt the dictionary atoms to the test image via large displacement optical flow. In the proposed algorithm, every dictionary atom is automatically aligned with the input image and the sparse code is then recovered using the adapted dictionary atoms. A corresponding supervised dictionary learning algorithm is also developed for the proposed framework. Experimental results on digit datasets recognition verify the efficacy and robustness of the proposed algorithm.
Unsupervised domain adaption dictionary learning for visual recognition
Jun 03, 2015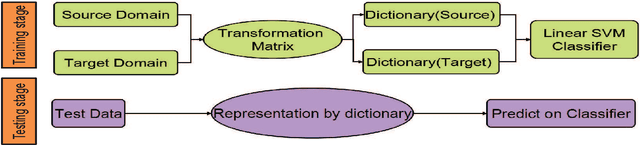
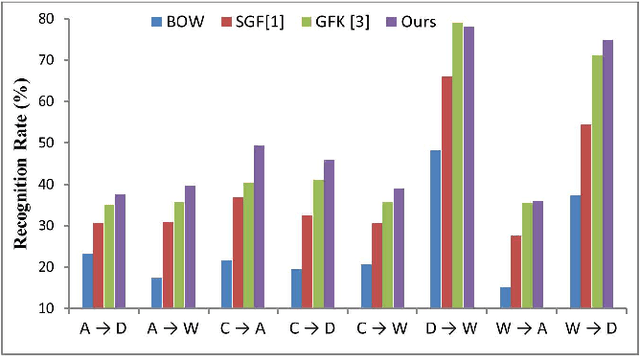
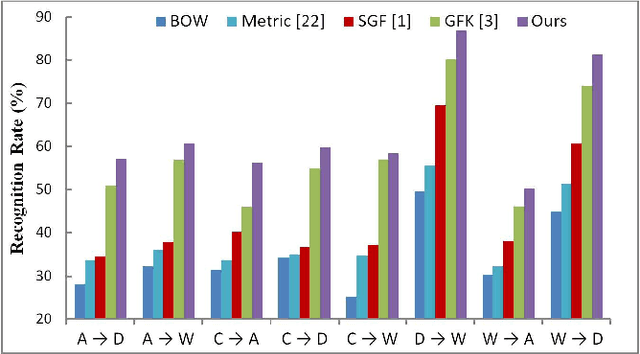
Over the last years, dictionary learning method has been extensively applied to deal with various computer vision recognition applications, and produced state-of-the-art results. However, when the data instances of a target domain have a different distribution than that of a source domain, the dictionary learning method may fail to perform well. In this paper, we address the cross-domain visual recognition problem and propose a simple but effective unsupervised domain adaption approach, where labeled data are only from source domain. In order to bring the original data in source and target domain into the same distribution, the proposed method forcing nearest coupled data between source and target domain to have identical sparse representations while jointly learning dictionaries for each domain, where the learned dictionaries can reconstruct original data in source and target domain respectively. So that sparse representations of original data can be used to perform visual recognition tasks. We demonstrate the effectiveness of our approach on standard datasets. Our method performs on par or better than competitive state-of-the-art methods.
Task-Driven Dictionary Learning for Hyperspectral Image Classification with Structured Sparsity Constraints
Feb 03, 2015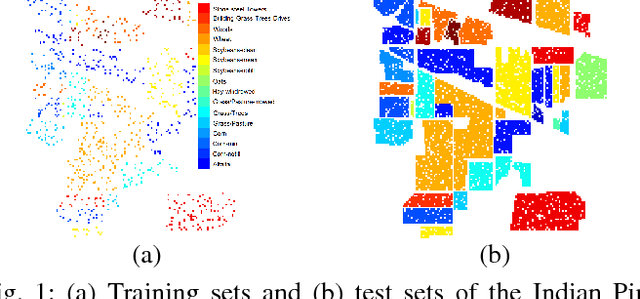
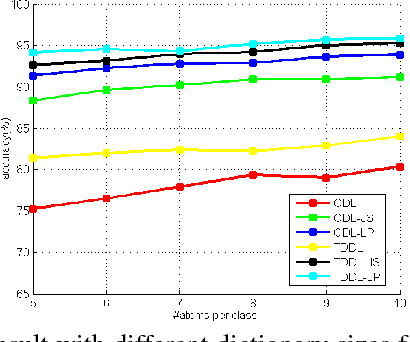
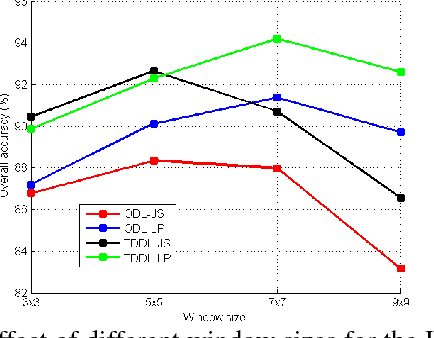

Sparse representation models a signal as a linear combination of a small number of dictionary atoms. As a generative model, it requires the dictionary to be highly redundant in order to ensure both a stable high sparsity level and a low reconstruction error for the signal. However, in practice, this requirement is usually impaired by the lack of labelled training samples. Fortunately, previous research has shown that the requirement for a redundant dictionary can be less rigorous if simultaneous sparse approximation is employed, which can be carried out by enforcing various structured sparsity constraints on the sparse codes of the neighboring pixels. In addition, numerous works have shown that applying a variety of dictionary learning methods for the sparse representation model can also improve the classification performance. In this paper, we highlight the task-driven dictionary learning algorithm, which is a general framework for the supervised dictionary learning method. We propose to enforce structured sparsity priors on the task-driven dictionary learning method in order to improve the performance of the hyperspectral classification. Our approach is able to benefit from both the advantages of the simultaneous sparse representation and those of the supervised dictionary learning. We enforce two different structured sparsity priors, the joint and Laplacian sparsity, on the task-driven dictionary learning method and provide the details of the corresponding optimization algorithms. Experiments on numerous popular hyperspectral images demonstrate that the classification performance of our approach is superior to sparse representation classifier with structured priors or the task-driven dictionary learning method.
Structured Priors for Sparse-Representation-Based Hyperspectral Image Classification
Jan 16, 2014
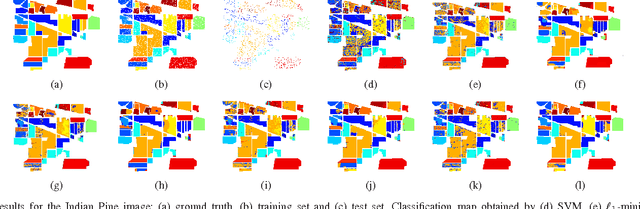
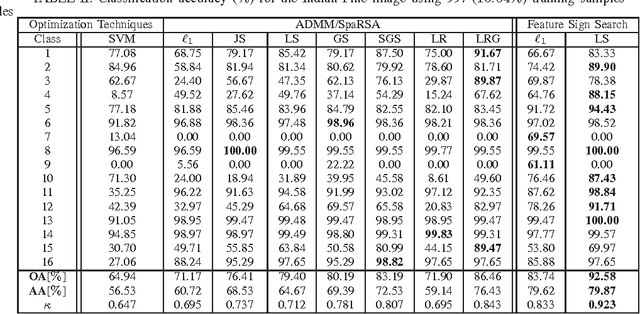
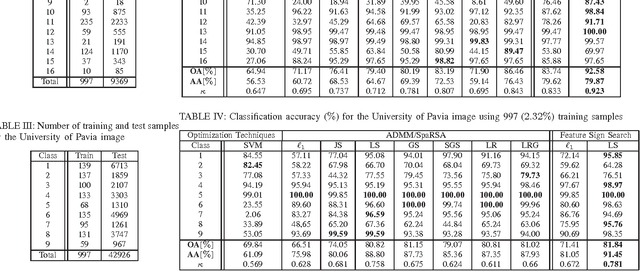
Pixel-wise classification, where each pixel is assigned to a predefined class, is one of the most important procedures in hyperspectral image (HSI) analysis. By representing a test pixel as a linear combination of a small subset of labeled pixels, a sparse representation classifier (SRC) gives rather plausible results compared with that of traditional classifiers such as the support vector machine (SVM). Recently, by incorporating additional structured sparsity priors, the second generation SRCs have appeared in the literature and are reported to further improve the performance of HSI. These priors are based on exploiting the spatial dependencies between the neighboring pixels, the inherent structure of the dictionary, or both. In this paper, we review and compare several structured priors for sparse-representation-based HSI classification. We also propose a new structured prior called the low rank group prior, which can be considered as a modification of the low rank prior. Furthermore, we will investigate how different structured priors improve the result for the HSI classification.