 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCubePart: An Open-Vocabulary Part-Controllable 3D Generator
May 27, 2026Interactive 3D assets used in games and simulation are typically decomposed into specific semantic parts to support animation, physics, and scripted behaviors, yet most generative 3D models produce either monolithic meshes or arbitrary part decompositions that cannot be aligned with application-specific requirements. We present CubePart, a generative framework for open-vocabulary, part-controllable 3D mesh generation that exposes part structure as an explicit inference-time control signal. Given a global text prompt and a user-defined parts schema expressed as an open-ended list of part names, our method generates a set of meshes - one per schema element - that assemble into a coherent object while respecting the specified semantic structure. To enable this capability, we introduce a scalable data pipeline to construct a large open-vocabulary, part-labeled 3D dataset, along with a two-stage generative architecture that separates global shape synthesis from part-level decoding. We demonstrate that the resulting assets can be directly integrated into game engines and driven by animation and behavior scripts without manual post-processing. Project Page: https://cubepart.github.io/
Efficient Autoregressive Shape Generation via Octree-Based Adaptive Tokenization
Apr 03, 2025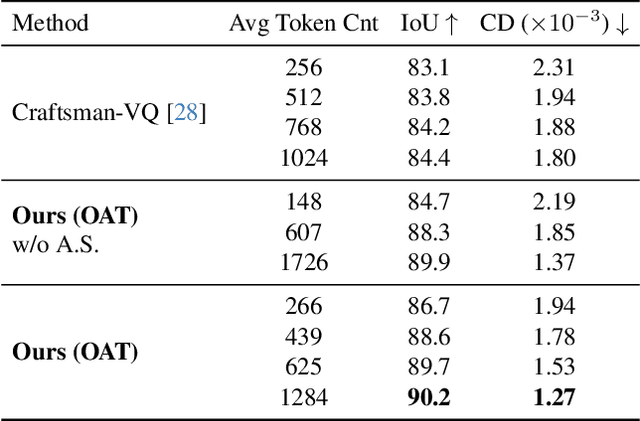

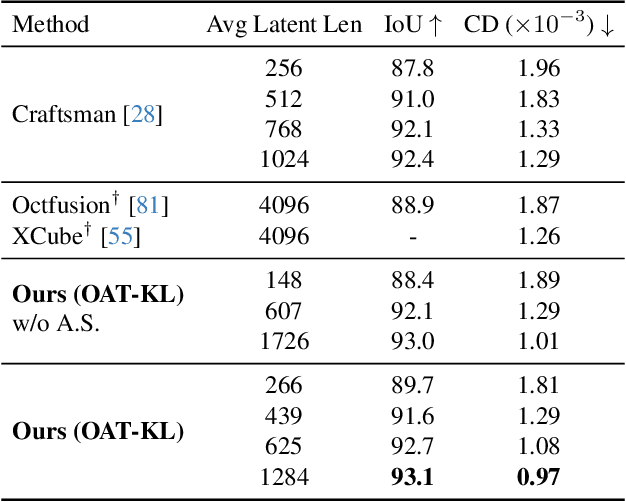
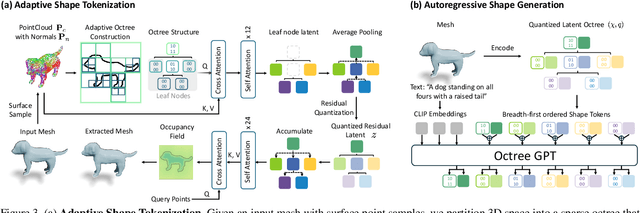
Many 3D generative models rely on variational autoencoders (VAEs) to learn compact shape representations. However, existing methods encode all shapes into a fixed-size token, disregarding the inherent variations in scale and complexity across 3D data. This leads to inefficient latent representations that can compromise downstream generation. We address this challenge by introducing Octree-based Adaptive Tokenization, a novel framework that adjusts the dimension of latent representations according to shape complexity. Our approach constructs an adaptive octree structure guided by a quadric-error-based subdivision criterion and allocates a shape latent vector to each octree cell using a query-based transformer. Building upon this tokenization, we develop an octree-based autoregressive generative model that effectively leverages these variable-sized representations in shape generation. Extensive experiments demonstrate that our approach reduces token counts by 50% compared to fixed-size methods while maintaining comparable visual quality. When using a similar token length, our method produces significantly higher-quality shapes. When incorporated with our downstream generative model, our method creates more detailed and diverse 3D content than existing approaches.
Cube: A Roblox View of 3D Intelligence
Mar 19, 2025



Foundation models trained on vast amounts of data have demonstrated remarkable reasoning and generation capabilities in the domains of text, images, audio and video. Our goal at Roblox is to build such a foundation model for 3D intelligence, a model that can support developers in producing all aspects of a Roblox experience, from generating 3D objects and scenes to rigging characters for animation to producing programmatic scripts describing object behaviors. We discuss three key design requirements for such a 3D foundation model and then present our first step towards building such a model. We expect that 3D geometric shapes will be a core data type and describe our solution for 3D shape tokenizer. We show how our tokenization scheme can be used in applications for text-to-shape generation, shape-to-text generation and text-to-scene generation. We demonstrate how these applications can collaborate with existing large language models (LLMs) to perform scene analysis and reasoning. We conclude with a discussion outlining our path to building a fully unified foundation model for 3D intelligence.
FlashTex: Fast Relightable Mesh Texturing with LightControlNet
Feb 20, 2024



Manually creating textures for 3D meshes is time-consuming, even for expert visual content creators. We propose a fast approach for automatically texturing an input 3D mesh based on a user-provided text prompt. Importantly, our approach disentangles lighting from surface material/reflectance in the resulting texture so that the mesh can be properly relit and rendered in any lighting environment. We introduce LightControlNet, a new text-to-image model based on the ControlNet architecture, which allows the specification of the desired lighting as a conditioning image to the model. Our text-to-texture pipeline then constructs the texture in two stages. The first stage produces a sparse set of visually consistent reference views of the mesh using LightControlNet. The second stage applies a texture optimization based on Score Distillation Sampling (SDS) that works with LightControlNet to increase the texture quality while disentangling surface material from lighting. Our pipeline is significantly faster than previous text-to-texture methods, while producing high-quality and relightable textures.
Learning to Factorize and Relight a City
Aug 06, 2020
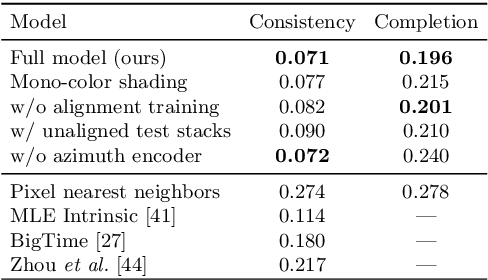


We propose a learning-based framework for disentangling outdoor scenes into temporally-varying illumination and permanent scene factors. Inspired by the classic intrinsic image decomposition, our learning signal builds upon two insights: 1) combining the disentangled factors should reconstruct the original image, and 2) the permanent factors should stay constant across multiple temporal samples of the same scene. To facilitate training, we assemble a city-scale dataset of outdoor timelapse imagery from Google Street View, where the same locations are captured repeatedly through time. This data represents an unprecedented scale of spatio-temporal outdoor imagery. We show that our learned disentangled factors can be used to manipulate novel images in realistic ways, such as changing lighting effects and scene geometry. Please visit factorize-a-city.github.io for animated results.
Transferable Recognition-Aware Image Processing
Oct 21, 2019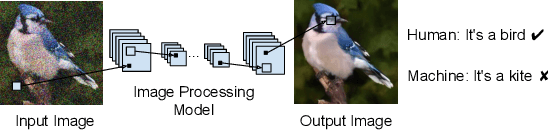
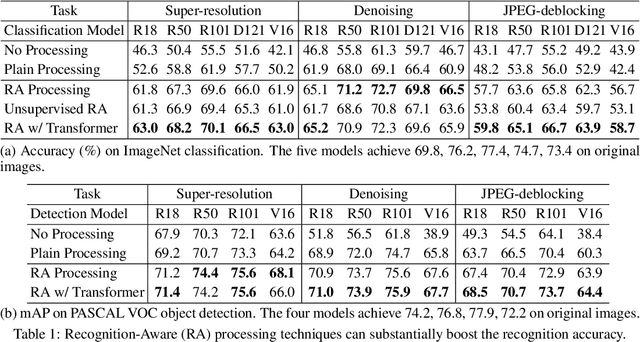
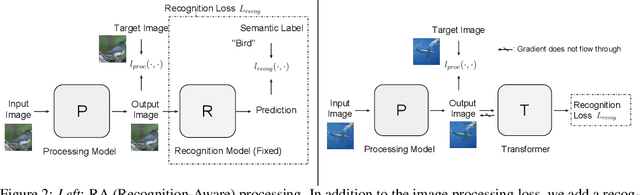
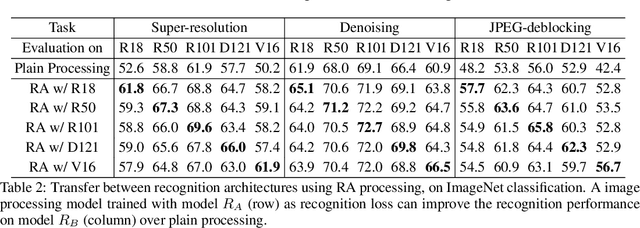
Recent progress in image recognition has stimulated the deployment of vision systems (e.g. image search engines) at an unprecedented scale. As a result, visual data are now often consumed not only by humans but also by machines. Meanwhile, existing image processing methods only optimize for better human perception, whereas the resulting images may not be accurately recognized by machines. This can be undesirable, e.g., the images can be improperly handled by search engines or recommendation systems. In this work, we propose simple approaches to improve machine interpretability of processed images: optimizing the recognition loss directly on the image processing network or through an intermediate transforming model, a process which we show can also be done in an unsupervised manner. Interestingly, the processing model's ability to enhance the recognition performance can transfer when evaluated on different recognition models, even if they are of different architectures, trained on different object categories or even different recognition tasks. This makes the solutions applicable even when we do not have the knowledge about future downstream recognition models, e.g., if we are to upload the processed images to the Internet. We conduct comprehensive experiments on three image processing tasks with two downstream recognition tasks, and confirm our method brings substantial accuracy improvement on both the same recognition model and when transferring to a different one, with minimal or no loss in the image processing quality.
Rethinking the Value of Network Pruning
Oct 11, 2018
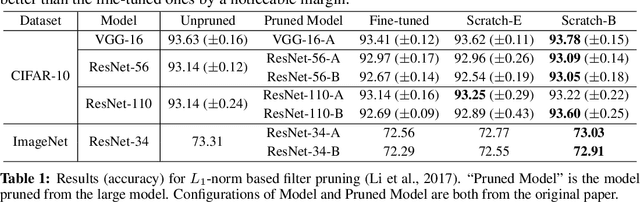
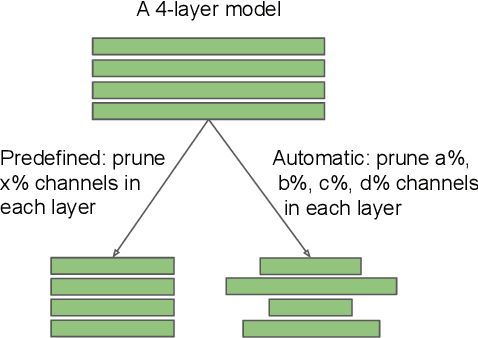
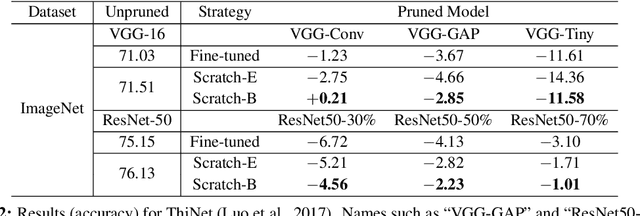
Network pruning is widely used for reducing the heavy computational cost of deep models. A typical pruning algorithm is a three-stage pipeline, i.e., training (a large model), pruning and fine-tuning. During pruning, according to a certain criterion, redundant weights are pruned and important weights are kept to best preserve the accuracy. In this work, we make several surprising observations which contradict common beliefs. For all the six state-of-the-art pruning algorithms we examined, fine-tuning a pruned model only gives comparable or even worse performance than training that model with randomly initialized weights. For pruning algorithms which assume a predefined target network architecture, one can get rid of the full pipeline and directly train the target network from scratch. Our observations are consistent for a wide variety of pruning algorithms with multiple network architectures, datasets, and tasks. Our results have several implications: 1) training a large, over-parameterized model is not necessary to obtain an efficient final model, 2) learned "important" weights of the large model are not necessarily useful for the small pruned model, 3) the pruned architecture itself, rather than a set of inherited "important" weights, is what leads to the efficiency benefit in the final model, which suggests that some pruning algorithms could be seen as performing network architecture search.
Everybody Dance Now
Aug 22, 2018


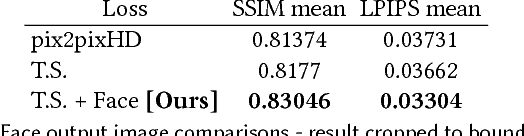
This paper presents a simple method for "do as I do" motion transfer: given a source video of a person dancing we can transfer that performance to a novel (amateur) target after only a few minutes of the target subject performing standard moves. We pose this problem as a per-frame image-to-image translation with spatio-temporal smoothing. Using pose detections as an intermediate representation between source and target, we learn a mapping from pose images to a target subject's appearance. We adapt this setup for temporally coherent video generation including realistic face synthesis. Our video demo can be found at https://youtu.be/PCBTZh41Ris .
Stereo Magnification: Learning View Synthesis using Multiplane Images
May 24, 2018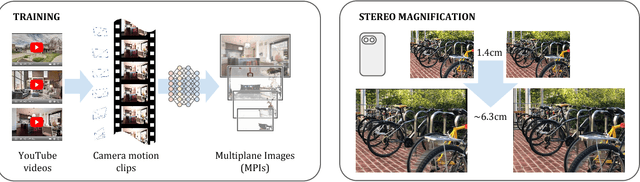
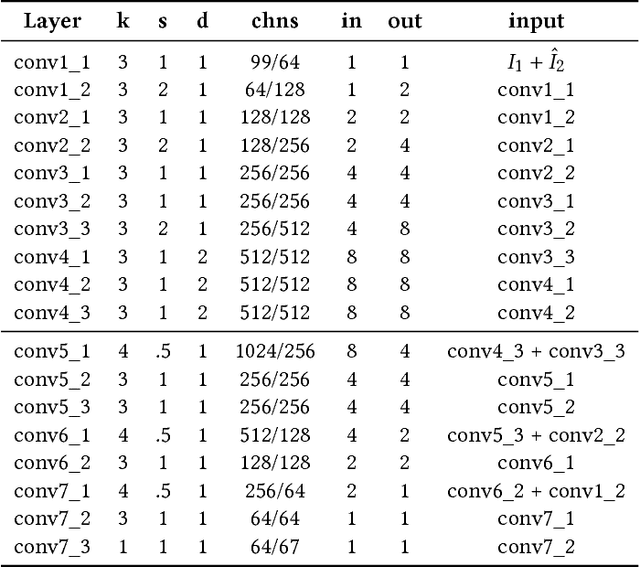
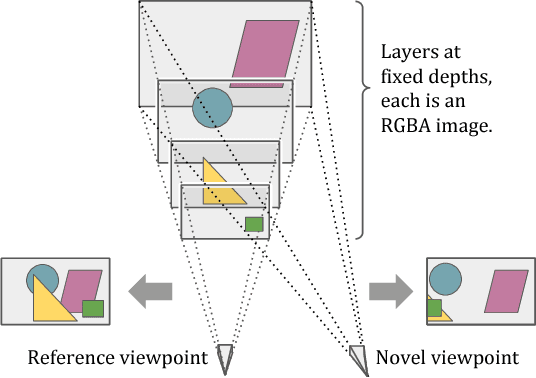
The view synthesis problem--generating novel views of a scene from known imagery--has garnered recent attention due in part to compelling applications in virtual and augmented reality. In this paper, we explore an intriguing scenario for view synthesis: extrapolating views from imagery captured by narrow-baseline stereo cameras, including VR cameras and now-widespread dual-lens camera phones. We call this problem stereo magnification, and propose a learning framework that leverages a new layered representation that we call multiplane images (MPIs). Our method also uses a massive new data source for learning view extrapolation: online videos on YouTube. Using data mined from such videos, we train a deep network that predicts an MPI from an input stereo image pair. This inferred MPI can then be used to synthesize a range of novel views of the scene, including views that extrapolate significantly beyond the input baseline. We show that our method compares favorably with several recent view synthesis methods, and demonstrate applications in magnifying narrow-baseline stereo images.
Image-to-Image Translation with Conditional Adversarial Networks
Nov 22, 2017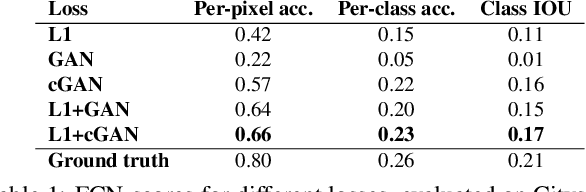
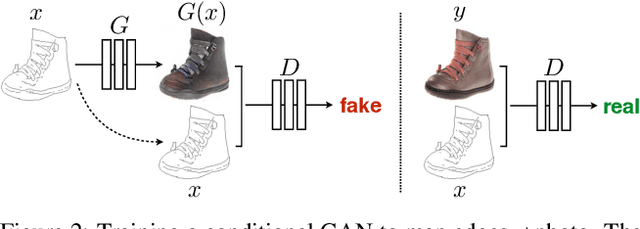

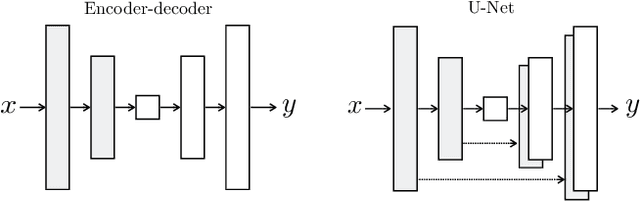
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This makes it possible to apply the same generic approach to problems that traditionally would require very different loss formulations. We demonstrate that this approach is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks. Indeed, since the release of the pix2pix software associated with this paper, a large number of internet users (many of them artists) have posted their own experiments with our system, further demonstrating its wide applicability and ease of adoption without the need for parameter tweaking. As a community, we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either.
* Website: https://phillipi.github.io/pix2pix/