 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditYourself: Audio-Driven Generation and Manipulation of Talking Head Videos with Diffusion Transformers
Jan 29, 2026Current generative video models excel at producing novel content from text and image prompts, but leave a critical gap in editing existing pre-recorded videos, where minor alterations to the spoken script require preserving motion, temporal coherence, speaker identity, and accurate lip synchronization. We introduce EditYourself, a DiT-based framework for audio-driven video-to-video (V2V) editing that enables transcript-based modification of talking head videos, including the seamless addition, removal, and retiming of visually spoken content. Building on a general-purpose video diffusion model, EditYourself augments its V2V capabilities with audio conditioning and region-aware, edit-focused training extensions. This enables precise lip synchronization and temporally coherent restructuring of existing performances via spatiotemporal inpainting, including the synthesis of realistic human motion in newly added segments, while maintaining visual fidelity and identity consistency over long durations. This work represents a foundational step toward generative video models as practical tools for professional video post-production.
Selfi: Self Improving Reconstruction Engine via 3D Geometric Feature Alignment
Dec 21, 2025Novel View Synthesis (NVS) has traditionally relied on models with explicit 3D inductive biases combined with known camera parameters from Structure-from-Motion (SfM) beforehand. Recent vision foundation models like VGGT take an orthogonal approach -- 3D knowledge is gained implicitly through training data and loss objectives, enabling feed-forward prediction of both camera parameters and 3D representations directly from a set of uncalibrated images. While flexible, VGGT features lack explicit multi-view geometric consistency, and we find that improving such 3D feature consistency benefits both NVS and pose estimation tasks. We introduce Selfi, a self-improving 3D reconstruction pipeline via feature alignment, transforming a VGGT backbone into a high-fidelity 3D reconstruction engine by leveraging its own outputs as pseudo-ground-truth. Specifically, we train a lightweight feature adapter using a reprojection-based consistency loss, which distills VGGT outputs into a new geometrically-aligned feature space that captures spatial proximity in 3D. This enables state-of-the-art performance in both NVS and camera pose estimation, demonstrating that feature alignment is a highly beneficial step for downstream 3D reasoning.
Quark: Real-time, High-resolution, and General Neural View Synthesis
Nov 25, 2024We present a novel neural algorithm for performing high-quality, high-resolution, real-time novel view synthesis. From a sparse set of input RGB images or videos streams, our network both reconstructs the 3D scene and renders novel views at 1080p resolution at 30fps on an NVIDIA A100. Our feed-forward network generalizes across a wide variety of datasets and scenes and produces state-of-the-art quality for a real-time method. Our quality approaches, and in some cases surpasses, the quality of some of the top offline methods. In order to achieve these results we use a novel combination of several key concepts, and tie them together into a cohesive and effective algorithm. We build on previous works that represent the scene using semi-transparent layers and use an iterative learned render-and-refine approach to improve those layers. Instead of flat layers, our method reconstructs layered depth maps (LDMs) that efficiently represent scenes with complex depth and occlusions. The iterative update steps are embedded in a multi-scale, UNet-style architecture to perform as much compute as possible at reduced resolution. Within each update step, to better aggregate the information from multiple input views, we use a specialized Transformer-based network component. This allows the majority of the per-input image processing to be performed in the input image space, as opposed to layer space, further increasing efficiency. Finally, due to the real-time nature of our reconstruction and rendering, we dynamically create and discard the internal 3D geometry for each frame, generating the LDM for each view. Taken together, this produces a novel and effective algorithm for view synthesis. Through extensive evaluation, we demonstrate that we achieve state-of-the-art quality at real-time rates. Project page: https://quark-3d.github.io/
DeepView: View Synthesis with Learned Gradient Descent
Jun 18, 2019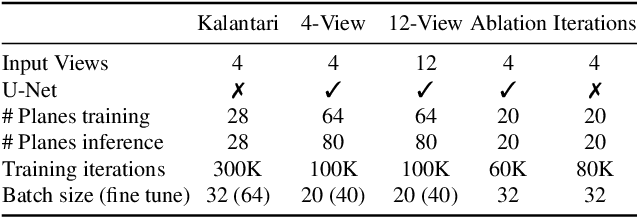
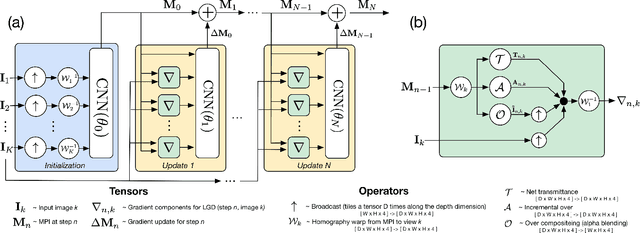

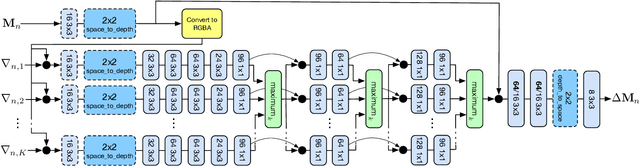
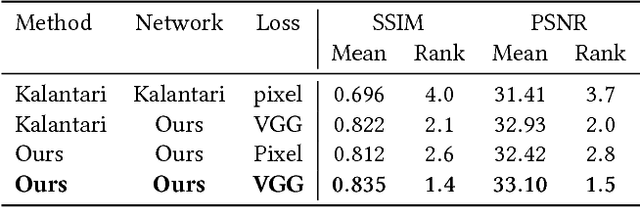
We present a novel approach to view synthesis using multiplane images (MPIs). Building on recent advances in learned gradient descent, our algorithm generates an MPI from a set of sparse camera viewpoints. The resulting method incorporates occlusion reasoning, improving performance on challenging scene features such as object boundaries, lighting reflections, thin structures, and scenes with high depth complexity. We show that our method achieves high-quality, state-of-the-art results on two datasets: the Kalantari light field dataset, and a new camera array dataset, Spaces, which we make publicly available.
DeepLight: Learning Illumination for Unconstrained Mobile Mixed Reality
Apr 02, 2019

We present a learning-based method to infer plausible high dynamic range (HDR), omnidirectional illumination given an unconstrained, low dynamic range (LDR) image from a mobile phone camera with a limited field of view (FOV). For training data, we collect videos of various reflective spheres placed within the camera's FOV, leaving most of the background unoccluded, leveraging that materials with diverse reflectance functions reveal different lighting cues in a single exposure. We train a deep neural network to regress from the LDR background image to HDR lighting by matching the LDR ground truth sphere images to those rendered with the predicted illumination using image-based relighting, which is differentiable. Our inference runs at interactive frame rates on a mobile device, enabling realistic rendering of virtual objects into real scenes for mobile mixed reality. Training on automatically exposed and white-balanced videos, we improve the realism of rendered objects compared to the state-of-the art methods for both indoor and outdoor scenes.
Stereo Magnification: Learning View Synthesis using Multiplane Images
May 24, 2018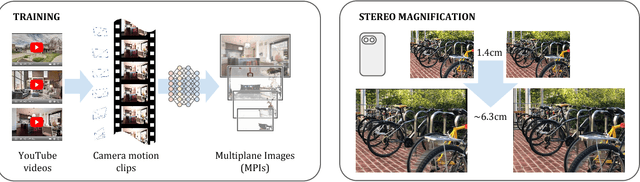
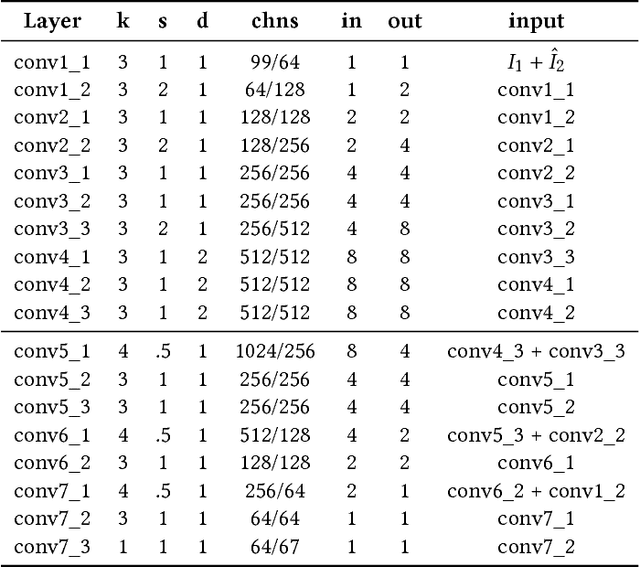
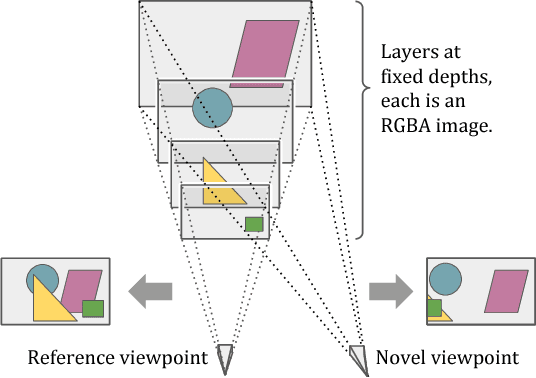
The view synthesis problem--generating novel views of a scene from known imagery--has garnered recent attention due in part to compelling applications in virtual and augmented reality. In this paper, we explore an intriguing scenario for view synthesis: extrapolating views from imagery captured by narrow-baseline stereo cameras, including VR cameras and now-widespread dual-lens camera phones. We call this problem stereo magnification, and propose a learning framework that leverages a new layered representation that we call multiplane images (MPIs). Our method also uses a massive new data source for learning view extrapolation: online videos on YouTube. Using data mined from such videos, we train a deep network that predicts an MPI from an input stereo image pair. This inferred MPI can then be used to synthesize a range of novel views of the scene, including views that extrapolate significantly beyond the input baseline. We show that our method compares favorably with several recent view synthesis methods, and demonstrate applications in magnifying narrow-baseline stereo images.
3D Bounding Box Estimation Using Deep Learning and Geometry
Apr 10, 2017



We present a method for 3D object detection and pose estimation from a single image. In contrast to current techniques that only regress the 3D orientation of an object, our method first regresses relatively stable 3D object properties using a deep convolutional neural network and then combines these estimates with geometric constraints provided by a 2D object bounding box to produce a complete 3D bounding box. The first network output estimates the 3D object orientation using a novel hybrid discrete-continuous loss, which significantly outperforms the L2 loss. The second output regresses the 3D object dimensions, which have relatively little variance compared to alternatives and can often be predicted for many object types. These estimates, combined with the geometric constraints on translation imposed by the 2D bounding box, enable us to recover a stable and accurate 3D object pose. We evaluate our method on the challenging KITTI object detection benchmark both on the official metric of 3D orientation estimation and also on the accuracy of the obtained 3D bounding boxes. Although conceptually simple, our method outperforms more complex and computationally expensive approaches that leverage semantic segmentation, instance level segmentation and flat ground priors and sub-category detection. Our discrete-continuous loss also produces state of the art results for 3D viewpoint estimation on the Pascal 3D+ dataset.
Geometric Neural Phrase Pooling: Modeling the Spatial Co-occurrence of Neurons
Jul 21, 2016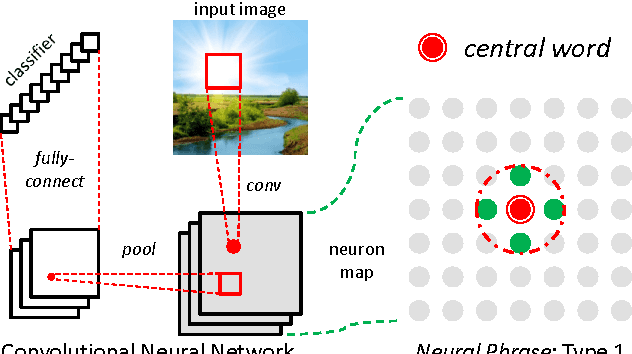

Deep Convolutional Neural Networks (CNNs) are playing important roles in state-of-the-art visual recognition. This paper focuses on modeling the spatial co-occurrence of neuron responses, which is less studied in the previous work. For this, we consider the neurons in the hidden layer as neural words, and construct a set of geometric neural phrases on top of them. The idea that grouping neural words into neural phrases is borrowed from the Bag-of-Visual-Words (BoVW) model. Next, the Geometric Neural Phrase Pooling (GNPP) algorithm is proposed to efficiently encode these neural phrases. GNPP acts as a new type of hidden layer, which punishes the isolated neuron responses after convolution, and can be inserted into a CNN model with little extra computational overhead. Experimental results show that GNPP produces significant and consistent accuracy gain in image classification.
DeepStereo: Learning to Predict New Views from the World's Imagery
Jun 22, 2015

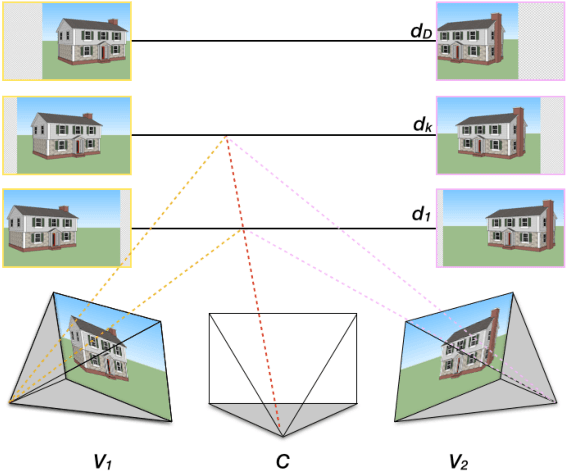
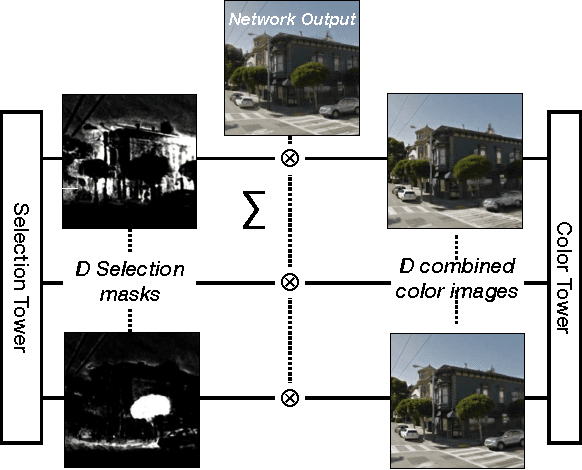
Deep networks have recently enjoyed enormous success when applied to recognition and classification problems in computer vision, but their use in graphics problems has been limited. In this work, we present a novel deep architecture that performs new view synthesis directly from pixels, trained from a large number of posed image sets. In contrast to traditional approaches which consist of multiple complex stages of processing, each of which require careful tuning and can fail in unexpected ways, our system is trained end-to-end. The pixels from neighboring views of a scene are presented to the network which then directly produces the pixels of the unseen view. The benefits of our approach include generality (we only require posed image sets and can easily apply our method to different domains), and high quality results on traditionally difficult scenes. We believe this is due to the end-to-end nature of our system which is able to plausibly generate pixels according to color, depth, and texture priors learnt automatically from the training data. To verify our method we show that it can convincingly reproduce known test views from nearby imagery. Additionally we show images rendered from novel viewpoints. To our knowledge, our work is the first to apply deep learning to the problem of new view synthesis from sets of real-world, natural imagery.
Representing Data by a Mixture of Activated Simplices
Dec 12, 2014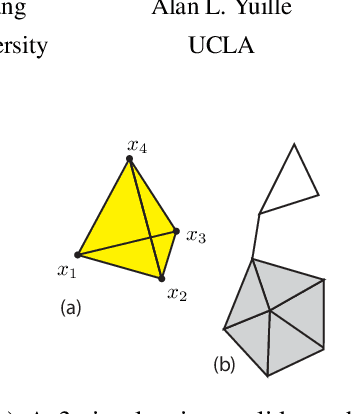
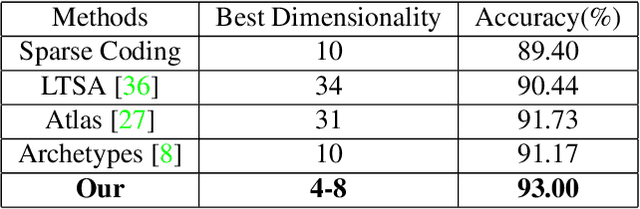
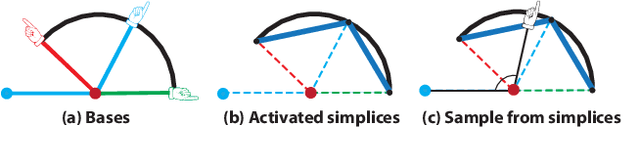

We present a new model which represents data as a mixture of simplices. Simplices are geometric structures that generalize triangles. We give a simple geometric understanding that allows us to learn a simplicial structure efficiently. Our method requires that the data are unit normalized (and thus lie on the unit sphere). We show that under this restriction, building a model with simplices amounts to constructing a convex hull inside the sphere whose boundary facets is close to the data. We call the boundary facets of the convex hull that are close to the data Activated Simplices. While the total number of bases used to build the simplices is a parameter of the model, the dimensions of the individual activated simplices are learned from the data. Simplices can have different dimensions, which facilitates modeling of inhomogeneous data sources. The simplicial structure is bounded --- this is appropriate for modeling data with constraints, such as human elbows can not bend more than 180 degrees. The simplices are easy to interpret and extremes within the data can be discovered among the vertices. The method provides good reconstruction and regularization. It supports good nearest neighbor classification and it allows realistic generative models to be constructed. It achieves state-of-the-art results on benchmark datasets, including 3D poses and digits.