 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed Form Variances for Variational Auto-Encoders
Dec 27, 2019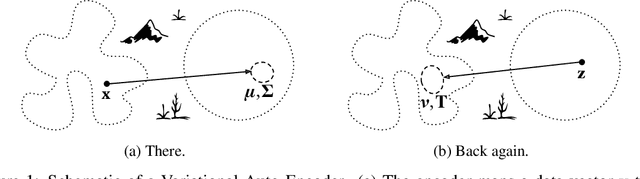
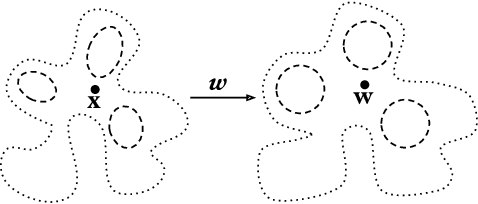

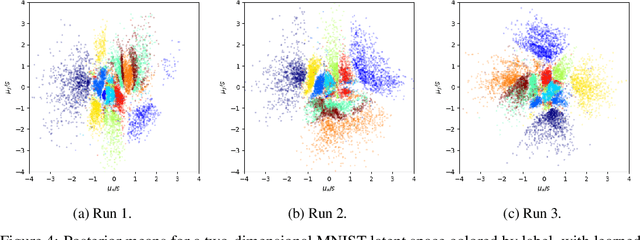
We propose a reformulation of Variational Auto-Encoders eliminating half of the network outputs (the variances) in a deep network setting. While it is well known that the posterior is in general intractable, we show that the variances of Gaussian posteriors and likelihoods may be solved in closed form, producing improved variational lower bounds over their learned counterparts in experiments. The closed forms reduce to remarkably simple expressions -- in particular, one optimal choice for the posterior variance is simply the identity matrix. We arrive at these conclusions by analyzing the variational lower bound objective irrespective of any particular network architecture, deriving its partial derivatives and closed form solutions for all parameters but the posterior means. In deriving the closed form likelihood variance, we show that the objective is underdetermined, which we resolve by constraining the presumed information content of the data examples. Any of these modifications may be applied to simplify, and perhaps improve, any Variational Auto-Encoder.
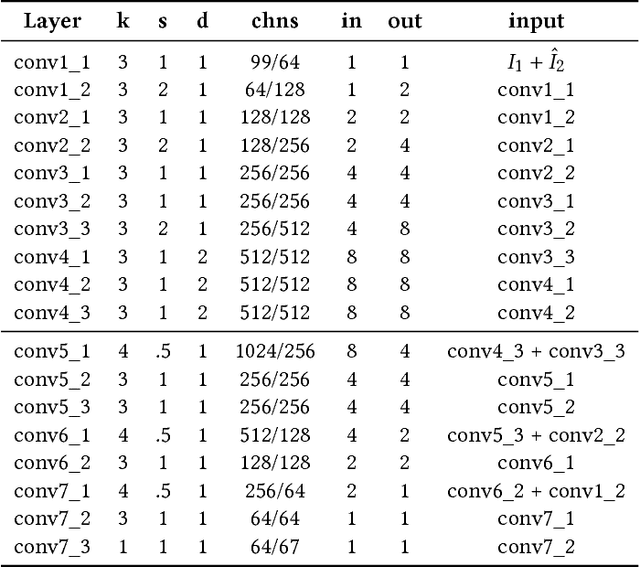
DeepView: View Synthesis with Learned Gradient Descent
Jun 18, 2019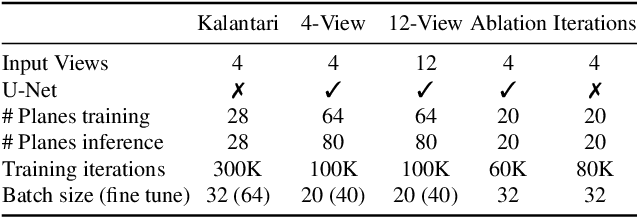
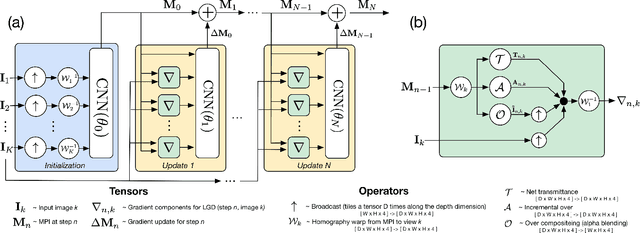

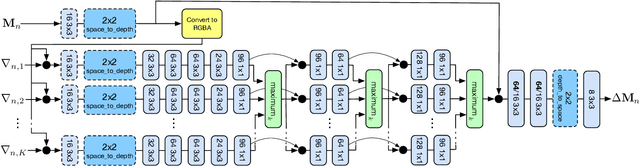
We present a novel approach to view synthesis using multiplane images (MPIs). Building on recent advances in learned gradient descent, our algorithm generates an MPI from a set of sparse camera viewpoints. The resulting method incorporates occlusion reasoning, improving performance on challenging scene features such as object boundaries, lighting reflections, thin structures, and scenes with high depth complexity. We show that our method achieves high-quality, state-of-the-art results on two datasets: the Kalantari light field dataset, and a new camera array dataset, Spaces, which we make publicly available.
Single Image Portrait Relighting
May 02, 2019
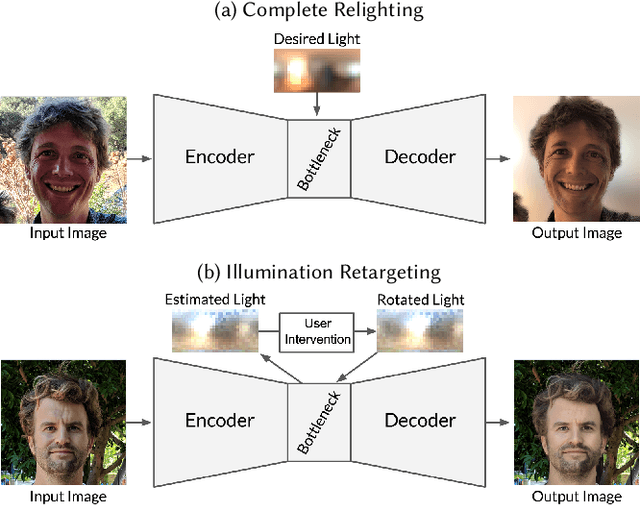
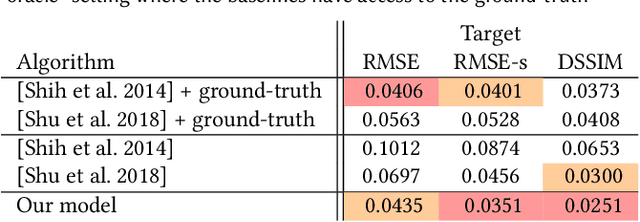

Lighting plays a central role in conveying the essence and depth of the subject in a portrait photograph. Professional photographers will carefully control the lighting in their studio to manipulate the appearance of their subject, while consumer photographers are usually constrained to the illumination of their environment. Though prior works have explored techniques for relighting an image, their utility is usually limited due to requirements of specialized hardware, multiple images of the subject under controlled or known illuminations, or accurate models of geometry and reflectance. To this end, we present a system for portrait relighting: a neural network that takes as input a single RGB image of a portrait taken with a standard cellphone camera in an unconstrained environment, and from that image produces a relit image of that subject as though it were illuminated according to any provided environment map. Our method is trained on a small database of 18 individuals captured under different directional light sources in a controlled light stage setup consisting of a densely sampled sphere of lights. Our proposed technique produces quantitatively superior results on our dataset's validation set compared to prior works, and produces convincing qualitative relighting results on a dataset of hundreds of real-world cellphone portraits. Because our technique can produce a 640 $\times$ 640 image in only 160 milliseconds, it may enable interactive user-facing photographic applications in the future.
* SIGGRAPH 2019 Technical Paper accepted
DeepLight: Learning Illumination for Unconstrained Mobile Mixed Reality
Apr 02, 2019

We present a learning-based method to infer plausible high dynamic range (HDR), omnidirectional illumination given an unconstrained, low dynamic range (LDR) image from a mobile phone camera with a limited field of view (FOV). For training data, we collect videos of various reflective spheres placed within the camera's FOV, leaving most of the background unoccluded, leveraging that materials with diverse reflectance functions reveal different lighting cues in a single exposure. We train a deep neural network to regress from the LDR background image to HDR lighting by matching the LDR ground truth sphere images to those rendered with the predicted illumination using image-based relighting, which is differentiable. Our inference runs at interactive frame rates on a mobile device, enabling realistic rendering of virtual objects into real scenes for mobile mixed reality. Training on automatically exposed and white-balanced videos, we improve the realism of rendered objects compared to the state-of-the art methods for both indoor and outdoor scenes.
Stereo Magnification: Learning View Synthesis using Multiplane Images
May 24, 2018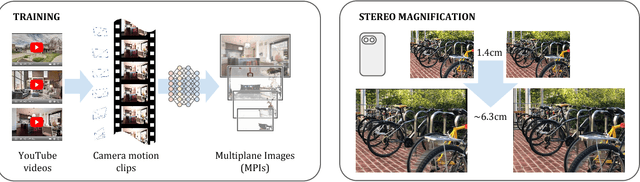
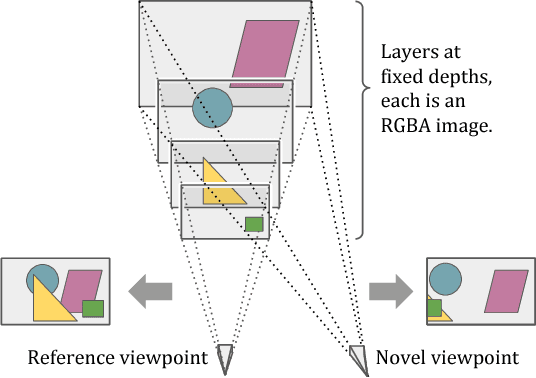
The view synthesis problem--generating novel views of a scene from known imagery--has garnered recent attention due in part to compelling applications in virtual and augmented reality. In this paper, we explore an intriguing scenario for view synthesis: extrapolating views from imagery captured by narrow-baseline stereo cameras, including VR cameras and now-widespread dual-lens camera phones. We call this problem stereo magnification, and propose a learning framework that leverages a new layered representation that we call multiplane images (MPIs). Our method also uses a massive new data source for learning view extrapolation: online videos on YouTube. Using data mined from such videos, we train a deep network that predicts an MPI from an input stereo image pair. This inferred MPI can then be used to synthesize a range of novel views of the scene, including views that extrapolate significantly beyond the input baseline. We show that our method compares favorably with several recent view synthesis methods, and demonstrate applications in magnifying narrow-baseline stereo images.