 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEye2Eye: A Simple Approach for Monocular-to-Stereo Video Synthesis
Apr 30, 2025The rising popularity of immersive visual experiences has increased interest in stereoscopic 3D video generation. Despite significant advances in video synthesis, creating 3D videos remains challenging due to the relative scarcity of 3D video data. We propose a simple approach for transforming a text-to-video generator into a video-to-stereo generator. Given an input video, our framework automatically produces the video frames from a shifted viewpoint, enabling a compelling 3D effect. Prior and concurrent approaches for this task typically operate in multiple phases, first estimating video disparity or depth, then warping the video accordingly to produce a second view, and finally inpainting the disoccluded regions. This approach inherently fails when the scene involves specular surfaces or transparent objects. In such cases, single-layer disparity estimation is insufficient, resulting in artifacts and incorrect pixel shifts during warping. Our work bypasses these restrictions by directly synthesizing the new viewpoint, avoiding any intermediate steps. This is achieved by leveraging a pre-trained video model's priors on geometry, object materials, optics, and semantics, without relying on external geometry models or manually disentangling geometry from the synthesis process. We demonstrate the advantages of our approach in complex, real-world scenarios featuring diverse object materials and compositions. See videos on https://video-eye2eye.github.io
Stereo4D: Learning How Things Move in 3D from Internet Stereo Videos
Dec 12, 2024Learning to understand dynamic 3D scenes from imagery is crucial for applications ranging from robotics to scene reconstruction. Yet, unlike other problems where large-scale supervised training has enabled rapid progress, directly supervising methods for recovering 3D motion remains challenging due to the fundamental difficulty of obtaining ground truth annotations. We present a system for mining high-quality 4D reconstructions from internet stereoscopic, wide-angle videos. Our system fuses and filters the outputs of camera pose estimation, stereo depth estimation, and temporal tracking methods into high-quality dynamic 3D reconstructions. We use this method to generate large-scale data in the form of world-consistent, pseudo-metric 3D point clouds with long-term motion trajectories. We demonstrate the utility of this data by training a variant of DUSt3R to predict structure and 3D motion from real-world image pairs, showing that training on our reconstructed data enables generalization to diverse real-world scenes. Project page: https://stereo4d.github.io
MegaSaM: Accurate, Fast, and Robust Structure and Motion from Casual Dynamic Videos
Dec 05, 2024



We present a system that allows for accurate, fast, and robust estimation of camera parameters and depth maps from casual monocular videos of dynamic scenes. Most conventional structure from motion and monocular SLAM techniques assume input videos that feature predominantly static scenes with large amounts of parallax. Such methods tend to produce erroneous estimates in the absence of these conditions. Recent neural network-based approaches attempt to overcome these challenges; however, such methods are either computationally expensive or brittle when run on dynamic videos with uncontrolled camera motion or unknown field of view. We demonstrate the surprising effectiveness of a deep visual SLAM framework: with careful modifications to its training and inference schemes, this system can scale to real-world videos of complex dynamic scenes with unconstrained camera paths, including videos with little camera parallax. Extensive experiments on both synthetic and real videos demonstrate that our system is significantly more accurate and robust at camera pose and depth estimation when compared with prior and concurrent work, with faster or comparable running times. See interactive results on our project page: https://mega-sam.github.io/
Streetscapes: Large-scale Consistent Street View Generation Using Autoregressive Video Diffusion
Jul 18, 2024



We present a method for generating Streetscapes-long sequences of views through an on-the-fly synthesized city-scale scene. Our generation is conditioned by language input (e.g., city name, weather), as well as an underlying map/layout hosting the desired trajectory. Compared to recent models for video generation or 3D view synthesis, our method can scale to much longer-range camera trajectories, spanning several city blocks, while maintaining visual quality and consistency. To achieve this goal, we build on recent work on video diffusion, used within an autoregressive framework that can easily scale to long sequences. In particular, we introduce a new temporal imputation method that prevents our autoregressive approach from drifting from the distribution of realistic city imagery. We train our Streetscapes system on a compelling source of data-posed imagery from Google Street View, along with contextual map data-which allows users to generate city views conditioned on any desired city layout, with controllable camera poses. Please see more results at our project page at https://boyangdeng.com/streetscapes.
Generative Image Dynamics
Sep 14, 2023



We present an approach to modeling an image-space prior on scene dynamics. Our prior is learned from a collection of motion trajectories extracted from real video sequences containing natural, oscillating motion such as trees, flowers, candles, and clothes blowing in the wind. Given a single image, our trained model uses a frequency-coordinated diffusion sampling process to predict a per-pixel long-term motion representation in the Fourier domain, which we call a neural stochastic motion texture. This representation can be converted into dense motion trajectories that span an entire video. Along with an image-based rendering module, these trajectories can be used for a number of downstream applications, such as turning still images into seamlessly looping dynamic videos, or allowing users to realistically interact with objects in real pictures.
Persistent Nature: A Generative Model of Unbounded 3D Worlds
Mar 23, 2023

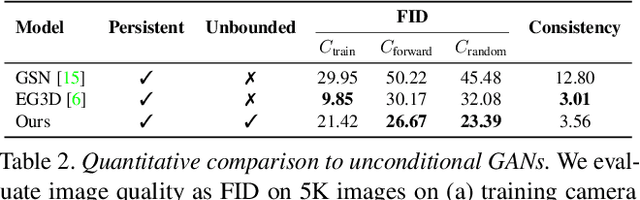

Despite increasingly realistic image quality, recent 3D image generative models often operate on 3D volumes of fixed extent with limited camera motions. We investigate the task of unconditionally synthesizing unbounded nature scenes, enabling arbitrarily large camera motion while maintaining a persistent 3D world model. Our scene representation consists of an extendable, planar scene layout grid, which can be rendered from arbitrary camera poses via a 3D decoder and volume rendering, and a panoramic skydome. Based on this representation, we learn a generative world model solely from single-view internet photos. Our method enables simulating long flights through 3D landscapes, while maintaining global scene consistency--for instance, returning to the starting point yields the same view of the scene. Our approach enables scene extrapolation beyond the fixed bounds of current 3D generative models, while also supporting a persistent, camera-independent world representation that stands in contrast to auto-regressive 3D prediction models. Our project page: https://chail.github.io/persistent-nature/.
DynIBaR: Neural Dynamic Image-Based Rendering
Nov 28, 2022



We address the problem of synthesizing novel views from a monocular video depicting a complex dynamic scene. State-of-the-art methods based on temporally varying Neural Radiance Fields (aka dynamic NeRFs) have shown impressive results on this task. However, for long videos with complex object motions and uncontrolled camera trajectories, these methods can produce blurry or inaccurate renderings, hampering their use in real-world applications. Instead of encoding the entire dynamic scene within the weights of an MLP, we present a new approach that addresses these limitations by adopting a volumetric image-based rendering framework that synthesizes new viewpoints by aggregating features from nearby views in a scene-motion-aware manner. Our system retains the advantages of prior methods in its ability to model complex scenes and view-dependent effects, but also enables synthesizing photo-realistic novel views from long videos featuring complex scene dynamics with unconstrained camera trajectories. We demonstrate significant improvements over state-of-the-art methods on dynamic scene datasets, and also apply our approach to in-the-wild videos with challenging camera and object motion, where prior methods fail to produce high-quality renderings. Our project webpage is at dynibar.github.io.
Deformable Sprites for Unsupervised Video Decomposition
Apr 14, 2022
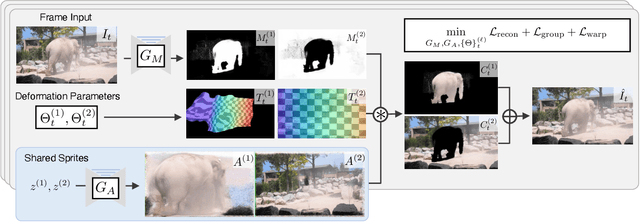


We describe a method to extract persistent elements of a dynamic scene from an input video. We represent each scene element as a \emph{Deformable Sprite} consisting of three components: 1) a 2D texture image for the entire video, 2) per-frame masks for the element, and 3) non-rigid deformations that map the texture image into each video frame. The resulting decomposition allows for applications such as consistent video editing. Deformable Sprites are a type of video auto-encoder model that is optimized on individual videos, and does not require training on a large dataset, nor does it rely on pre-trained models. Moreover, our method does not require object masks or other user input, and discovers moving objects of a wider variety than previous work. We evaluate our approach on standard video datasets and show qualitative results on a diverse array of Internet videos. Code and video results can be found at https://deformable-sprites.github.io
Simple and Effective Synthesis of Indoor 3D Scenes
Apr 06, 2022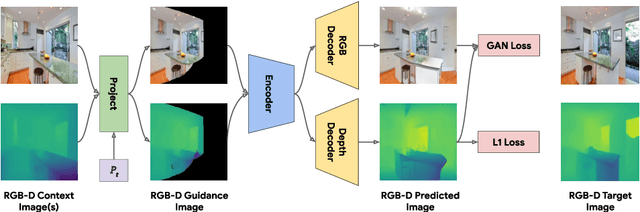
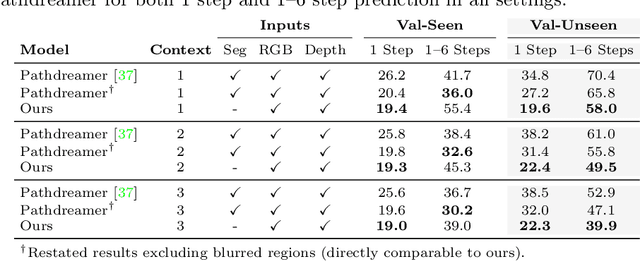


We study the problem of synthesizing immersive 3D indoor scenes from one or more images. Our aim is to generate high-resolution images and videos from novel viewpoints, including viewpoints that extrapolate far beyond the input images while maintaining 3D consistency. Existing approaches are highly complex, with many separately trained stages and components. We propose a simple alternative: an image-to-image GAN that maps directly from reprojections of incomplete point clouds to full high-resolution RGB-D images. On the Matterport3D and RealEstate10K datasets, our approach significantly outperforms prior work when evaluated by humans, as well as on FID scores. Further, we show that our model is useful for generative data augmentation. A vision-and-language navigation (VLN) agent trained with trajectories spatially-perturbed by our model improves success rate by up to 1.5% over a state of the art baseline on the R2R benchmark. Our code will be made available to facilitate generative data augmentation and applications to downstream robotics and embodied AI tasks.
Dimensions of Motion: Learning to Predict a Subspace of Optical Flow from a Single Image
Jan 06, 2022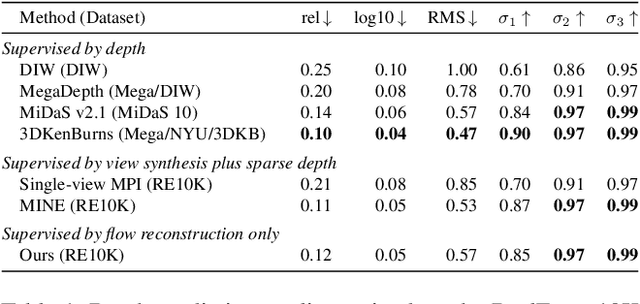


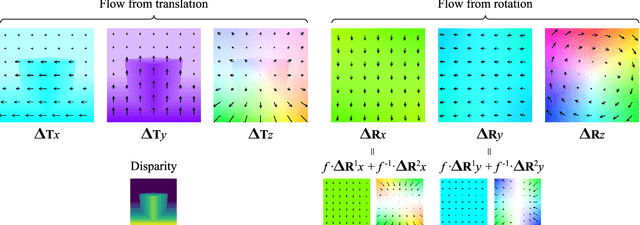
We introduce the problem of predicting, from a single video frame, a low-dimensional subspace of optical flow which includes the actual instantaneous optical flow. We show how several natural scene assumptions allow us to identify an appropriate flow subspace via a set of basis flow fields parameterized by disparity and a representation of object instances. The flow subspace, together with a novel loss function, can be used for the tasks of predicting monocular depth or predicting depth plus an object instance embedding. This provides a new approach to learning these tasks in an unsupervised fashion using monocular input video without requiring camera intrinsics or poses.