 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Chronicles: Using Multimodal LLMs to Analyze Massive Collections of Images
Apr 14, 2025
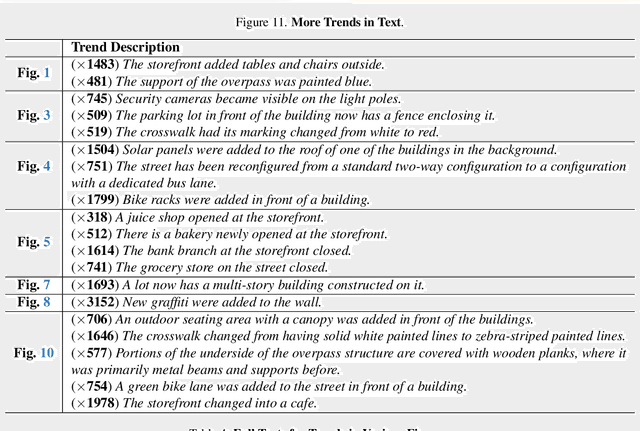


We present a system using Multimodal LLMs (MLLMs) to analyze a large database with tens of millions of images captured at different times, with the aim of discovering patterns in temporal changes. Specifically, we aim to capture frequent co-occurring changes ("trends") across a city over a certain period. Unlike previous visual analyses, our analysis answers open-ended queries (e.g., "what are the frequent types of changes in the city?") without any predetermined target subjects or training labels. These properties cast prior learning-based or unsupervised visual analysis tools unsuitable. We identify MLLMs as a novel tool for their open-ended semantic understanding capabilities. Yet, our datasets are four orders of magnitude too large for an MLLM to ingest as context. So we introduce a bottom-up procedure that decomposes the massive visual analysis problem into more tractable sub-problems. We carefully design MLLM-based solutions to each sub-problem. During experiments and ablation studies with our system, we find it significantly outperforms baselines and is able to discover interesting trends from images captured in large cities (e.g., "addition of outdoor dining,", "overpass was painted blue," etc.). See more results and interactive demos at https://boyangdeng.com/visual-chronicles.
Semi-Supervised Weed Detection in Vegetable Fields: In-domain and Cross-domain Experiments
Feb 24, 2025
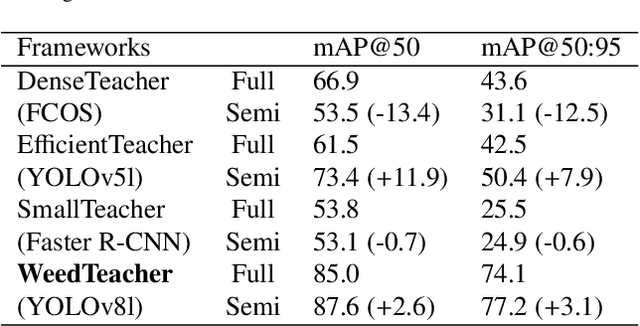

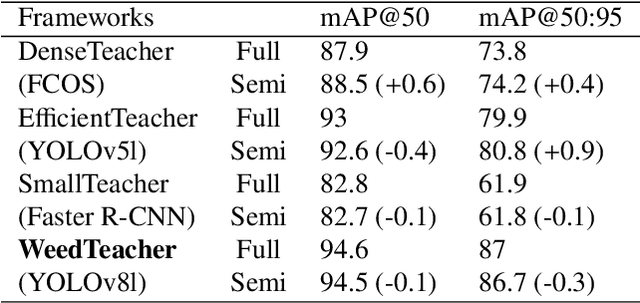
Robust weed detection remains a challenging task in precision weeding, requiring not only potent weed detection models but also large-scale, labeled data. However, the labeled data adequate for model training is practically difficult to come by due to the time-consuming, labor-intensive process that requires specialized expertise to recognize plant species. This study introduces semi-supervised object detection (SSOD) methods for leveraging unlabeled data for enhanced weed detection and proposes a new YOLOv8-based SSOD method, i.e., WeedTeacher. An experimental comparison of four SSOD methods, including three existing frameworks (i.e., DenseTeacher, EfficientTeacher, and SmallTeacher) and WeedTeacher, alongside fully supervised baselines, was conducted for weed detection in both in-domain and cross-domain contexts. A new, diverse weed dataset was created as the testbed, comprising a total of 19,931 field images from two differing domains, including 8,435 labeled (basic-domain) images acquired by handholding devices from 2021 to 2023 and 11,496 unlabeled (new-domain) images acquired by a ground-based mobile platform in 2024. The in-domain experiment with models trained using 10% of the labeled, basic-domain images and tested on the remaining 90% of the data, showed that the YOLOv8-basedWeedTeacher achieved the highest accuracy among all four SSOD methods, with an improvement of 2.6% mAP@50 and 3.1% mAP@50:95 over its supervised baseline (i.e., YOLOv8l). In the cross-domain experiment where the unlabeled new-domain data was incorporated, all four SSOD methods, however, resulted in no or limited improvements over their supervised counterparts. Research is needed to address the difficulty of cross-domain data utilization for robust weed detection.
Streetscapes: Large-scale Consistent Street View Generation Using Autoregressive Video Diffusion
Jul 18, 2024



We present a method for generating Streetscapes-long sequences of views through an on-the-fly synthesized city-scale scene. Our generation is conditioned by language input (e.g., city name, weather), as well as an underlying map/layout hosting the desired trajectory. Compared to recent models for video generation or 3D view synthesis, our method can scale to much longer-range camera trajectories, spanning several city blocks, while maintaining visual quality and consistency. To achieve this goal, we build on recent work on video diffusion, used within an autoregressive framework that can easily scale to long sequences. In particular, we introduce a new temporal imputation method that prevents our autoregressive approach from drifting from the distribution of realistic city imagery. We train our Streetscapes system on a compelling source of data-posed imagery from Google Street View, along with contextual map data-which allows users to generate city views conditioned on any desired city layout, with controllable camera poses. Please see more results at our project page at https://boyangdeng.com/streetscapes.
Stable diffusion for Data Augmentation in COCO and Weed Datasets
Dec 11, 2023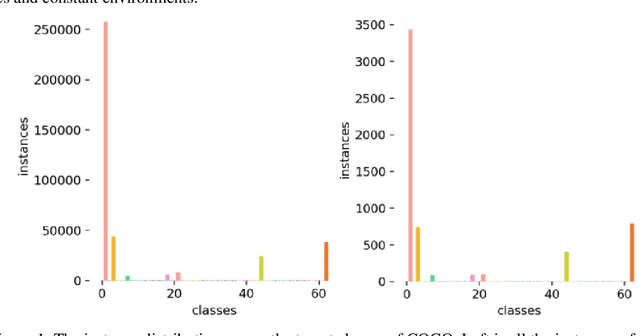

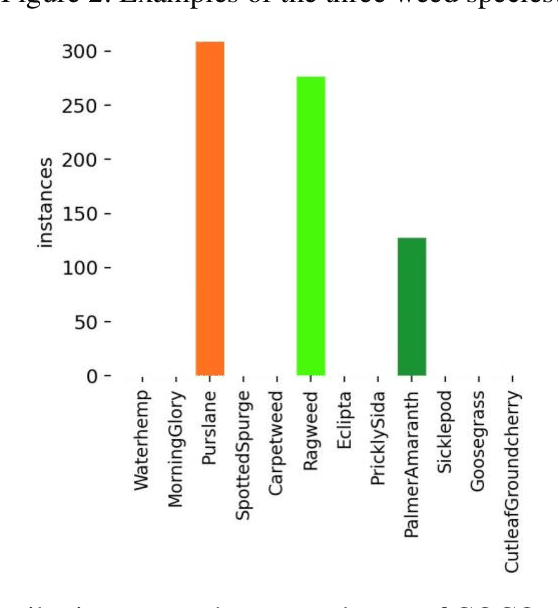

Generative models have increasingly impacted relative tasks, from computer vision to interior design and other fields. Stable diffusion is an outstanding diffusion model that paves the way for producing high-resolution images with thorough details from text prompts or reference images. It will be an interesting topic about gaining improvements for small datasets with image-sparse categories. This study utilized seven common categories and three widespread weed species to evaluate the efficiency of a stable diffusion model. In detail, Stable diffusion was used to generate synthetic images belonging to these classes; three techniques (i.e., Image-to-image translation, Dreambooth, and ControlNet) based on stable diffusion were leveraged for image generation with different focuses. Then, classification and detection tasks were conducted based on these synthetic images, whose performance was compared to the models trained on original images. Promising results have been achieved in some classes. This seminal study may expedite the adaption of stable diffusion models to different fields.
An Improved Neural Network Model Based On CNN Using For Fruit Sugar Degree Detection
Nov 18, 2023



Artificial Intelligence(AI) widely applies in Image Classification and Recognition, Text Understanding and Natural Language Processing, which makes great progress. In this paper, we introduced AI into the fruit quality detection field. We designed a fruit sugar degree regression model using an Artificial Neural Network based on spectra of fruits within the visible/near-infrared(V/NIR)range. After analysis of fruit spectra, we innovatively proposed a new neural network structure: low layers consist of a Multilayer Perceptron(MLP), a middle layer is a 2-dimensional correlation matrix layer, and high layers consist of several Convolutional Neural Network(CNN) layers. In this study, we used fruit sugar value as a detection target, collecting two fruits called Gan Nan Navel and Tian Shan Pear as samples, doing experiments respectively, and comparing their results. We used Analysis of Variance(ANOVA) to evaluate the reliability of the dataset we collected. Then, we tried multiple strategies to process spectrum data, evaluating their effects. In this paper, we tried to add Wavelet Decomposition(WD) to reduce feature dimensions and a Genetic Algorithm(GA) to find excellent features. Then, we compared Neural Network models with traditional Partial Least Squares(PLS) based models. We also compared the neural network structure we designed(MLP-CNN) with other traditional neural network structures. In this paper, we proposed a new evaluation standard derived from dataset standard deviation(STD) for evaluating detection performance, validating the viability of using an artificial neural network model to do fruit sugar degree nondestructive detection.
LumiGAN: Unconditional Generation of Relightable 3D Human Faces
Apr 25, 2023



Unsupervised learning of 3D human faces from unstructured 2D image data is an active research area. While recent works have achieved an impressive level of photorealism, they commonly lack control of lighting, which prevents the generated assets from being deployed in novel environments. To this end, we introduce LumiGAN, an unconditional Generative Adversarial Network (GAN) for 3D human faces with a physically based lighting module that enables relighting under novel illumination at inference time. Unlike prior work, LumiGAN can create realistic shadow effects using an efficient visibility formulation that is learned in a self-supervised manner. LumiGAN generates plausible physical properties for relightable faces, including surface normals, diffuse albedo, and specular tint without any ground truth data. In addition to relightability, we demonstrate significantly improved geometry generation compared to state-of-the-art non-relightable 3D GANs and notably better photorealism than existing relightable GANs.
GINA-3D: Learning to Generate Implicit Neural Assets in the Wild
Apr 04, 2023



Modeling the 3D world from sensor data for simulation is a scalable way of developing testing and validation environments for robotic learning problems such as autonomous driving. However, manually creating or re-creating real-world-like environments is difficult, expensive, and not scalable. Recent generative model techniques have shown promising progress to address such challenges by learning 3D assets using only plentiful 2D images -- but still suffer limitations as they leverage either human-curated image datasets or renderings from manually-created synthetic 3D environments. In this paper, we introduce GINA-3D, a generative model that uses real-world driving data from camera and LiDAR sensors to create realistic 3D implicit neural assets of diverse vehicles and pedestrians. Compared to the existing image datasets, the real-world driving setting poses new challenges due to occlusions, lighting-variations and long-tail distributions. GINA-3D tackles these challenges by decoupling representation learning and generative modeling into two stages with a learned tri-plane latent structure, inspired by recent advances in generative modeling of images. To evaluate our approach, we construct a large-scale object-centric dataset containing over 520K images of vehicles and pedestrians from the Waymo Open Dataset, and a new set of 80K images of long-tail instances such as construction equipment, garbage trucks, and cable cars. We compare our model with existing approaches and demonstrate that it achieves state-of-the-art performance in quality and diversity for both generated images and geometries.
Object Occlusion of Adding New Categories in Objection Detection
Jun 14, 2022
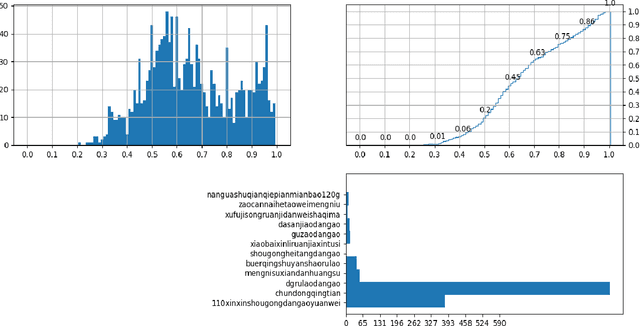
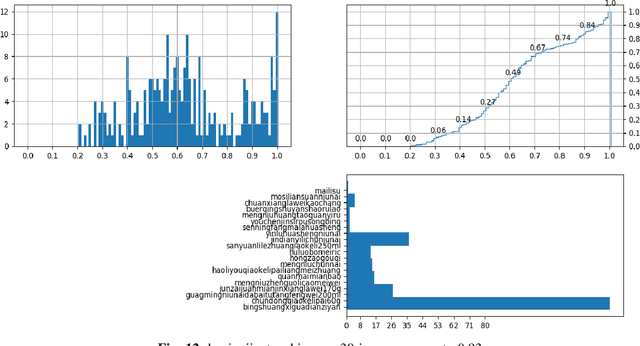

Building instance detection models that are data efficient and can handle rare object categories is an important challenge in computer vision. But data collection methods and metrics are lack of research towards real scenarios application using neural network. Here, we perform a systematic study of the Object Occlusion data collection and augmentation methods where we imitate object occlusion relationship in target scenarios. However, we find that the simple mechanism of object occlusion is good enough and can provide acceptable accuracy in real scenarios adding new category. We illustate that only adding 15 images of new category in a half million training dataset with hundreds categories, can give this new category 95% accuracy in unseen test dataset including thousands of images of this category.
Revisiting 3D Object Detection From an Egocentric Perspective
Dec 14, 2021
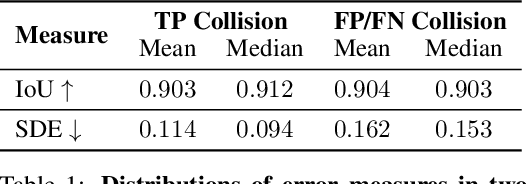
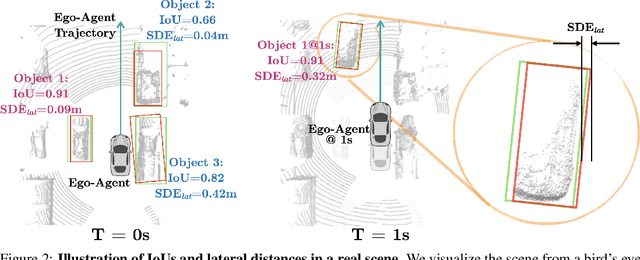
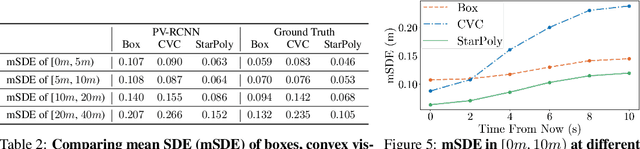
3D object detection is a key module for safety-critical robotics applications such as autonomous driving. For these applications, we care most about how the detections affect the ego-agent's behavior and safety (the egocentric perspective). Intuitively, we seek more accurate descriptions of object geometry when it's more likely to interfere with the ego-agent's motion trajectory. However, current detection metrics, based on box Intersection-over-Union (IoU), are object-centric and aren't designed to capture the spatio-temporal relationship between objects and the ego-agent. To address this issue, we propose a new egocentric measure to evaluate 3D object detection, namely Support Distance Error (SDE). Our analysis based on SDE reveals that the egocentric detection quality is bounded by the coarse geometry of the bounding boxes. Given the insight that SDE would benefit from more accurate geometry descriptions, we propose to represent objects as amodal contours, specifically amodal star-shaped polygons, and devise a simple model, StarPoly, to predict such contours. Our experiments on the large-scale Waymo Open Dataset show that SDE better reflects the impact of detection quality on the ego-agent's safety compared to IoU; and the estimated contours from StarPoly consistently improve the egocentric detection quality over recent 3D object detectors.
NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination
Jun 03, 2021
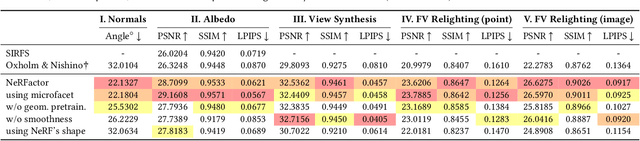
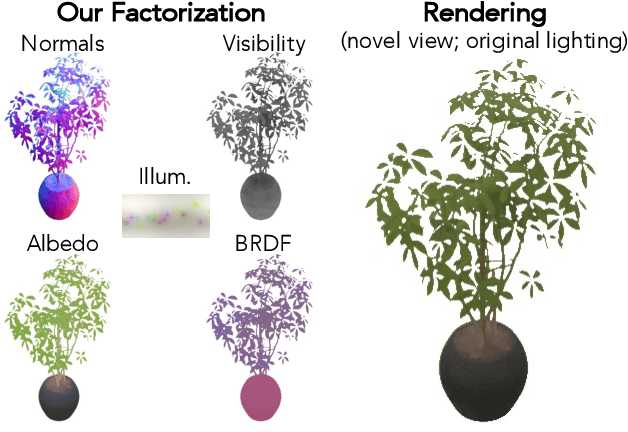

We address the problem of recovering the shape and spatially-varying reflectance of an object from posed multi-view images of the object illuminated by one unknown lighting condition. This enables the rendering of novel views of the object under arbitrary environment lighting and editing of the object's material properties. The key to our approach, which we call Neural Radiance Factorization (NeRFactor), is to distill the volumetric geometry of a Neural Radiance Field (NeRF) [Mildenhall et al. 2020] representation of the object into a surface representation and then jointly refine the geometry while solving for the spatially-varying reflectance and the environment lighting. Specifically, NeRFactor recovers 3D neural fields of surface normals, light visibility, albedo, and Bidirectional Reflectance Distribution Functions (BRDFs) without any supervision, using only a re-rendering loss, simple smoothness priors, and a data-driven BRDF prior learned from real-world BRDF measurements. By explicitly modeling light visibility, NeRFactor is able to separate shadows from albedo and synthesize realistic soft or hard shadows under arbitrary lighting conditions. NeRFactor is able to recover convincing 3D models for free-viewpoint relighting in this challenging and underconstrained capture setup for both synthetic and real scenes. Qualitative and quantitative experiments show that NeRFactor outperforms classic and deep learning-based state of the art across various tasks. Our code and data are available at people.csail.mit.edu/xiuming/projects/nerfactor/.