 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Environment-Trajectory Co-Optimization for Safe Multi-Agent Navigation
Apr 08, 2026The environment plays a critical role in multi-agent navigation by imposing spatial constraints, rules, and limitations that agents must navigate around. Traditional approaches treat the environment as fixed, without exploring its impact on agents' performance. This work considers environment configurations as decision variables, alongside agent actions, to jointly achieve safe navigation. We formulate a bi-level problem, where the lower-level sub-problem optimizes agent trajectories that minimize navigation cost and the upper-level sub-problem optimizes environment configurations that maximize navigation safety. We develop a differentiable optimization method that iteratively solves the lower-level sub-problem with interior point methods and the upper-level sub-problem with gradient ascent. A key challenge lies in analytically coupling these two levels. We address this by leveraging KKT conditions and the Implicit Function Theorem to compute gradients of agent trajectories w.r.t. environment parameters, enabling differentiation throughout the bi-level structure. Moreover, we propose a novel metric that quantifies navigation safety as a criterion for the upper-level environment optimization, and prove its validity through measure theory. Our experiments validate the effectiveness of the proposed framework in a variety of safety-critical navigation scenarios, inspired from warehouse logistics to urban transportation. The results demonstrate that optimized environments provide navigation guidance, improving both agents' safety and efficiency.
Stochastic Sequential Decision Making over Expanding Networks with Graph Filtering
Mar 19, 2026Graph filters leverage topological information to process networked data with existing methods mainly studying fixed graphs, ignoring that graphs often expand as nodes continually attach with an unknown pattern. The latter requires developing filter-based decision-making paradigms that take evolution and uncertainty into account. Existing approaches rely on either pre-designed filters or online learning, limited to a myopic view considering only past or present information. To account for future impacts, we propose a stochastic sequential decision-making framework for filtering networked data with a policy that adapts filtering to expanding graphs. By representing filter shifts as agents, we model the filter as a multi-agent system and train the policy following multi-agent reinforcement learning. This accounts for long-term rewards and captures expansion dynamics through sequential decision-making. Moreover, we develop a context-aware graph neural network to parameterize the policy, which tunes filter parameters based on information of both the graph and agents. Experiments on synthetic and real datasets from cold-start recommendation to COVID prediction highlight the benefits of using a sequential decision-making perspective over batch and online filtering alternatives.
MPA: Multimodal Prototype Augmentation for Few-Shot Learning
Feb 09, 2026Recently, few-shot learning (FSL) has become a popular task that aims to recognize new classes from only a few labeled examples and has been widely applied in fields such as natural science, remote sensing, and medical images. However, most existing methods focus only on the visual modality and compute prototypes directly from raw support images, which lack comprehensive and rich multimodal information. To address these limitations, we propose a novel Multimodal Prototype Augmentation FSL framework called MPA, including LLM-based Multi-Variant Semantic Enhancement (LMSE), Hierarchical Multi-View Augmentation (HMA), and an Adaptive Uncertain Class Absorber (AUCA). LMSE leverages large language models to generate diverse paraphrased category descriptions, enriching the support set with additional semantic cues. HMA exploits both natural and multi-view augmentations to enhance feature diversity (e.g., changes in viewing distance, camera angles, and lighting conditions). AUCA models uncertainty by introducing uncertain classes via interpolation and Gaussian sampling, effectively absorbing uncertain samples. Extensive experiments on four single-domain and six cross-domain FSL benchmarks demonstrate that MPA achieves superior performance compared to existing state-of-the-art methods across most settings. Notably, MPA surpasses the second-best method by 12.29% and 24.56% in the single-domain and cross-domain setting, respectively, in the 5-way 1-shot setting.
Tianyi: A Traditional Chinese Medicine all-rounder language model and its Real-World Clinical Practice
May 19, 2025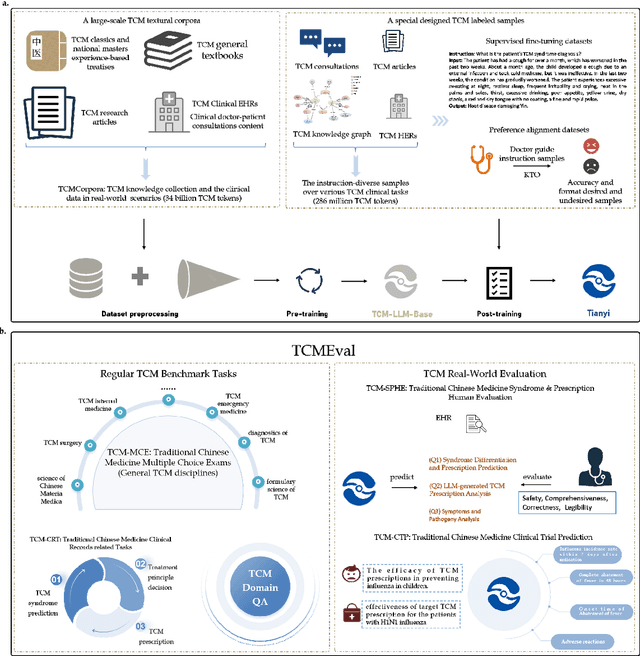
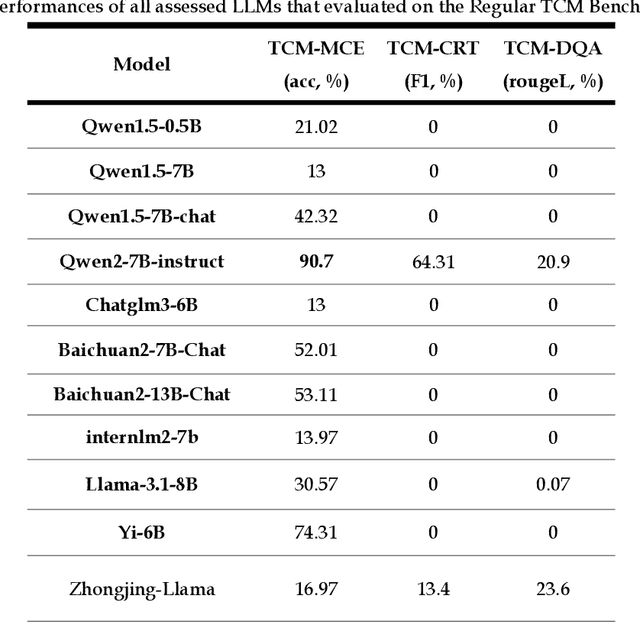

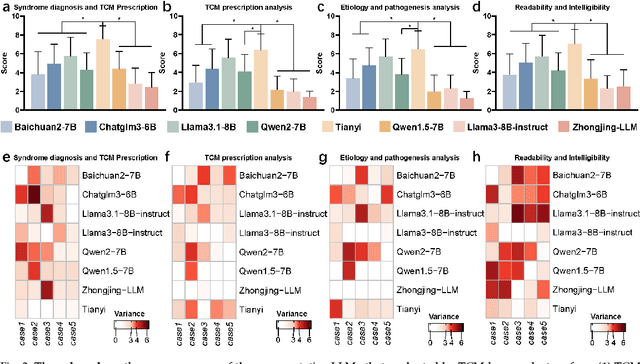
Natural medicines, particularly Traditional Chinese Medicine (TCM), are gaining global recognition for their therapeutic potential in addressing human symptoms and diseases. TCM, with its systematic theories and extensive practical experience, provides abundant resources for healthcare. However, the effective application of TCM requires precise syndrome diagnosis, determination of treatment principles, and prescription formulation, which demand decades of clinical expertise. Despite advancements in TCM-based decision systems, machine learning, and deep learning research, limitations in data and single-objective constraints hinder their practical application. In recent years, large language models (LLMs) have demonstrated potential in complex tasks, but lack specialization in TCM and face significant challenges, such as too big model scale to deploy and issues with hallucination. To address these challenges, we introduce Tianyi with 7.6-billion-parameter LLM, a model scale proper and specifically designed for TCM, pre-trained and fine-tuned on diverse TCM corpora, including classical texts, expert treatises, clinical records, and knowledge graphs. Tianyi is designed to assimilate interconnected and systematic TCM knowledge through a progressive learning manner. Additionally, we establish TCMEval, a comprehensive evaluation benchmark, to assess LLMs in TCM examinations, clinical tasks, domain-specific question-answering, and real-world trials. The extensive evaluations demonstrate the significant potential of Tianyi as an AI assistant in TCM clinical practice and research, bridging the gap between TCM knowledge and practical application.
Sparse Covariance Neural Networks
Oct 02, 2024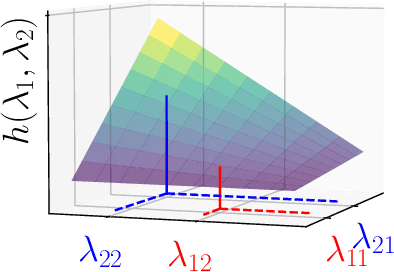
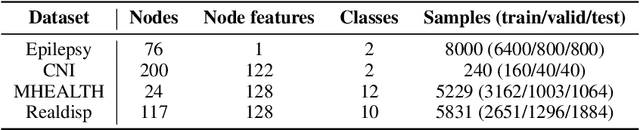
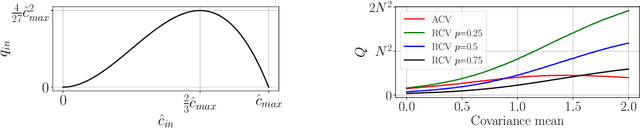
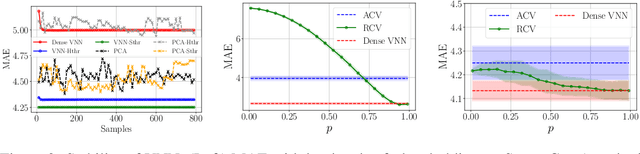
Covariance Neural Networks (VNNs) perform graph convolutions on the covariance matrix of tabular data and achieve success in a variety of applications. However, the empirical covariance matrix on which the VNNs operate may contain many spurious correlations, making VNNs' performance inconsistent due to these noisy estimates and decreasing their computational efficiency. To tackle this issue, we put forth Sparse coVariance Neural Networks (S-VNNs), a framework that applies sparsification techniques on the sample covariance matrix before convolution. When the true covariance matrix is sparse, we propose hard and soft thresholding to improve covariance estimation and reduce computational cost. Instead, when the true covariance is dense, we propose stochastic sparsification where data correlations are dropped in probability according to principled strategies. We show that S-VNNs are more stable than nominal VNNs as well as sparse principal component analysis. By analyzing the impact of sparsification on their behavior, we provide novel connections between S-VNN stability and data distribution. We support our theoretical findings with experimental results on various application scenarios, ranging from brain data to human action recognition, and show an improved task performance, stability, and computational efficiency of S-VNNs compared with nominal VNNs.
On LASSO Inference for High Dimensional Predictive Regression
Sep 16, 2024LASSO introduces shrinkage bias into estimated coefficients, which can adversely affect the desirable asymptotic normality and invalidate the standard inferential procedure based on the $t$-statistic. The desparsified LASSO has emerged as a well-known remedy for this issue. In the context of high dimensional predictive regression, the desparsified LASSO faces an additional challenge: the Stambaugh bias arising from nonstationary regressors. To restore the standard inferential procedure, we propose a novel estimator called IVX-desparsified LASSO (XDlasso). XDlasso eliminates the shrinkage bias and the Stambaugh bias simultaneously and does not require prior knowledge about the identities of nonstationary and stationary regressors. We establish the asymptotic properties of XDlasso for hypothesis testing, and our theoretical findings are supported by Monte Carlo simulations. Applying our method to real-world applications from the FRED-MD database -- which includes a rich set of control variables -- we investigate two important empirical questions: (i) the predictability of the U.S. stock returns based on the earnings-price ratio, and (ii) the predictability of the U.S. inflation using the unemployment rate.
Co-Optimization of Environment and Policies for Decentralized Multi-Agent Navigation
Mar 21, 2024This work views the multi-agent system and its surrounding environment as a co-evolving system, where the behavior of one affects the other. The goal is to take both agent actions and environment configurations as decision variables, and optimize these two components in a coordinated manner to improve some measure of interest. Towards this end, we consider the problem of decentralized multi-agent navigation in cluttered environments. By introducing two sub-objectives of multi-agent navigation and environment optimization, we propose an $\textit{agent-environment co-optimization}$ problem and develop a $\textit{coordinated algorithm}$ that alternates between these sub-objectives to search for an optimal synthesis of agent actions and obstacle configurations in the environment; ultimately, improving the navigation performance. Due to the challenge of explicitly modeling the relation between agents, environment and performance, we leverage policy gradient to formulate a model-free learning mechanism within the coordinated framework. A formal convergence analysis shows that our coordinated algorithm tracks the local minimum trajectory of an associated time-varying non-convex optimization problem. Extensive numerical results corroborate theoretical findings and show the benefits of co-optimization over baselines. Interestingly, the results also indicate that optimized environment configurations are able to offer structural guidance that is key to de-conflicting agents in motion.
On the Trade-Off between Stability and Representational Capacity in Graph Neural Networks
Dec 04, 2023Analyzing the stability of graph neural networks (GNNs) under topological perturbations is key to understanding their transferability and the role of each architecture component. However, stability has been investigated only for particular architectures, questioning whether it holds for a broader spectrum of GNNs or only for a few instances. To answer this question, we study the stability of EdgeNet: a general GNN framework that unifies more than twenty solutions including the convolutional and attention-based classes, as well as graph isomorphism networks and hybrid architectures. We prove that all GNNs within the EdgeNet framework are stable to topological perturbations. By studying the effect of different EdgeNet categories on the stability, we show that GNNs with fewer degrees of freedom in their parameter space, linked to a lower representational capacity, are more stable. The key factor yielding this trade-off is the eigenvector misalignment between the EdgeNet parameter matrices and the graph shift operator. For example, graph convolutional neural networks that assign a single scalar per signal shift (hence, with a perfect alignment) are more stable than the more involved node or edge-varying counterparts. Extensive numerical results corroborate our theoretical findings and highlight the role of different architecture components in the trade-off.
An Improved Neural Network Model Based On CNN Using For Fruit Sugar Degree Detection
Nov 18, 2023



Artificial Intelligence(AI) widely applies in Image Classification and Recognition, Text Understanding and Natural Language Processing, which makes great progress. In this paper, we introduced AI into the fruit quality detection field. We designed a fruit sugar degree regression model using an Artificial Neural Network based on spectra of fruits within the visible/near-infrared(V/NIR)range. After analysis of fruit spectra, we innovatively proposed a new neural network structure: low layers consist of a Multilayer Perceptron(MLP), a middle layer is a 2-dimensional correlation matrix layer, and high layers consist of several Convolutional Neural Network(CNN) layers. In this study, we used fruit sugar value as a detection target, collecting two fruits called Gan Nan Navel and Tian Shan Pear as samples, doing experiments respectively, and comparing their results. We used Analysis of Variance(ANOVA) to evaluate the reliability of the dataset we collected. Then, we tried multiple strategies to process spectrum data, evaluating their effects. In this paper, we tried to add Wavelet Decomposition(WD) to reduce feature dimensions and a Genetic Algorithm(GA) to find excellent features. Then, we compared Neural Network models with traditional Partial Least Squares(PLS) based models. We also compared the neural network structure we designed(MLP-CNN) with other traditional neural network structures. In this paper, we proposed a new evaluation standard derived from dataset standard deviation(STD) for evaluating detection performance, validating the viability of using an artificial neural network model to do fruit sugar degree nondestructive detection.
Limited-Memory Greedy Quasi-Newton Method with Non-asymptotic Superlinear Convergence Rate
Jun 27, 2023



Non-asymptotic convergence analysis of quasi-Newton methods has gained attention with a landmark result establishing an explicit superlinear rate of O$((1/\sqrt{t})^t)$. The methods that obtain this rate, however, exhibit a well-known drawback: they require the storage of the previous Hessian approximation matrix or instead storing all past curvature information to form the current Hessian inverse approximation. Limited-memory variants of quasi-Newton methods such as the celebrated L-BFGS alleviate this issue by leveraging a limited window of past curvature information to construct the Hessian inverse approximation. As a result, their per iteration complexity and storage requirement is O$(\tau d)$ where $\tau \le d$ is the size of the window and $d$ is the problem dimension reducing the O$(d^2)$ computational cost and memory requirement of standard quasi-Newton methods. However, to the best of our knowledge, there is no result showing a non-asymptotic superlinear convergence rate for any limited-memory quasi-Newton method. In this work, we close this gap by presenting a limited-memory greedy BFGS (LG-BFGS) method that achieves an explicit non-asymptotic superlinear rate. We incorporate displacement aggregation, i.e., decorrelating projection, in post-processing gradient variations, together with a basis vector selection scheme on variable variations, which greedily maximizes a progress measure of the Hessian estimate to the true Hessian. Their combination allows past curvature information to remain in a sparse subspace while yielding a valid representation of the full history. Interestingly, our established non-asymptotic superlinear convergence rate demonstrates a trade-off between the convergence speed and memory requirement, which to our knowledge, is the first of its kind. Numerical results corroborate our theoretical findings and demonstrate the effectiveness of our method.