 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing Private Image Generation via Coarse-to-Fine Wavelet Modeling
Feb 26, 2026Generative models trained on sensitive image datasets risk memorizing and reproducing individual training examples, making strong privacy guarantees essential. While differential privacy (DP) provides a principled framework for such guarantees, standard DP finetuning (e.g., with DP-SGD) often results in severe degradation of image quality, particularly in high-frequency textures, due to the indiscriminate addition of noise across all model parameters. In this work, we propose a spectral DP framework based on the hypothesis that the most privacy-sensitive portions of an image are often low-frequency components in the wavelet space (e.g., facial features and object shapes) while high-frequency components are largely generic and public. Based on this hypothesis, we propose the following two-stage framework for DP image generation with coarse image intermediaries: (1) DP finetune an autoregressive spectral image tokenizer model on the low-resolution wavelet coefficients of the sensitive images, and (2) perform high-resolution upsampling using a publicly pretrained super-resolution model. By restricting the privacy budget to the global structures of the image in the first stage, and leveraging the post-processing property of DP for detail refinement, we achieve promising trade-offs between privacy and utility. Experiments on the MS-COCO and MM-CelebA-HQ datasets show that our method generates images with improved quality and style capture relative to other leading DP image frameworks.
Learning Mixture Density via Natural Gradient Expectation Maximization
Feb 11, 2026Mixture density networks are neural networks that produce Gaussian mixtures to represent continuous multimodal conditional densities. Standard training procedures involve maximum likelihood estimation using the negative log-likelihood (NLL) objective, which suffers from slow convergence and mode collapse. In this work, we improve the optimization of mixture density networks by integrating their information geometry. Specifically, we interpret mixture density networks as deep latent-variable models and analyze them through an expectation maximization framework, which reveals surprising theoretical connections to natural gradient descent. We then exploit such connections to derive the natural gradient expectation maximization (nGEM) objective. We show that empirically nGEM achieves up to 10$\times$ faster convergence while adding almost zerocomputational overhead, and scales well to high-dimensional data where NLL otherwise fails.
No-Regret Thompson Sampling for Finite-Horizon Markov Decision Processes with Gaussian Processes
Oct 23, 2025Thompson sampling (TS) is a powerful and widely used strategy for sequential decision-making, with applications ranging from Bayesian optimization to reinforcement learning (RL). Despite its success, the theoretical foundations of TS remain limited, particularly in settings with complex temporal structure such as RL. We address this gap by establishing no-regret guarantees for TS using models with Gaussian marginal distributions. Specifically, we consider TS in episodic RL with joint Gaussian process (GP) priors over rewards and transitions. We prove a regret bound of $\mathcal{\tilde{O}}(\sqrt{KH\Gamma(KH)})$ over $K$ episodes of horizon $H$, where $\Gamma(\cdot)$ captures the complexity of the GP model. Our analysis addresses several challenges, including the non-Gaussian nature of value functions and the recursive structure of Bellman updates, and extends classical tools such as the elliptical potential lemma to multi-output settings. This work advances the understanding of TS in RL and highlights how structural assumptions and model uncertainty shape its performance in finite-horizon Markov Decision Processes.
Differentially Private Decentralized Deep Learning with Consensus Algorithms
Jun 24, 2023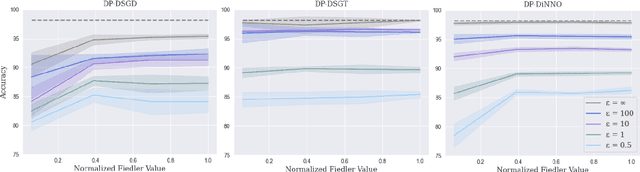

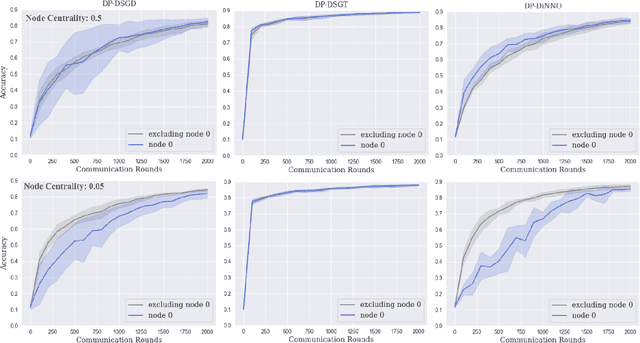
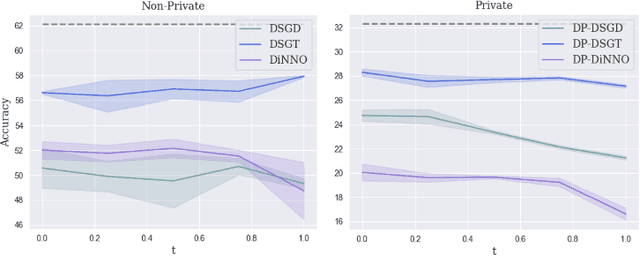
Cooperative decentralized deep learning relies on direct information exchange between communicating agents, each with access to a local dataset which should be kept private. The goal is for all agents to achieve consensus on model parameters after training. However, sharing parameters with untrustworthy neighboring agents could leak exploitable information about local datasets. To combat this, we introduce differentially private decentralized learning that secures each agent's local dataset during and after cooperative training. In our approach, we generalize Differentially Private Stochastic Gradient Descent (DP-SGD) -- a popular differentially private training method for centralized deep learning -- to practical subgradient- and ADMM-based decentralized learning methods. Our algorithms' differential privacy guarantee holds for arbitrary deep learning objective functions, and we analyze the convergence properties for strongly convex objective functions. We compare our algorithms against centrally trained models on standard classification tasks and evaluate the relationships between performance, privacy budget, graph connectivity, and degree of training data overlap among agents. We find that differentially private gradient tracking is resistant to performance degradation under sparse graphs and non-uniform data distributions. Furthermore, we show that it is possible to learn a model achieving high accuracies, within 3% of DP-SGD on MNIST under (1, 10^-5)-differential privacy and within 6% of DP-SGD on CIFAR-100 under (10, 10^-5)-differential privacy, without ever sharing raw data with other agents. Open source code can be found at: https://github.com/jbayrooti/dp-dec-learning.
Multispectral Self-Supervised Learning with Viewmaker Networks
Feb 11, 2023



Contrastive learning methods have been applied to a range of domains and modalities by training models to identify similar ``views'' of data points. However, specialized scientific modalities pose a challenge for this paradigm, as identifying good views for each scientific instrument is complex and time-intensive. In this paper, we focus on applying contrastive learning approaches to a variety of remote sensing datasets. We show that Viewmaker networks, a recently proposed method for generating views, are promising for producing views in this setting without requiring extensive domain knowledge and trial and error. We apply Viewmaker to four multispectral imaging problems, each with a different format, finding that Viewmaker can outperform cropping- and reflection-based methods for contrastive learning in every case when evaluated on downstream classification tasks. This provides additional evidence that domain-agnostic methods can empower contrastive learning to scale to real-world scientific domains. Open source code can be found at https://github.com/jbayrooti/divmaker.
Temperature as Uncertainty in Contrastive Learning
Oct 08, 2021
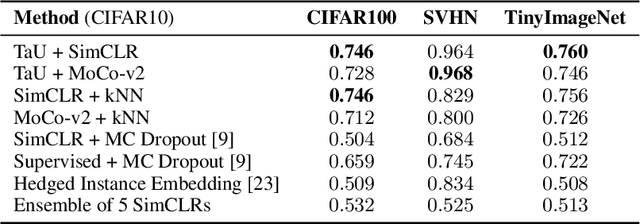


Contrastive learning has demonstrated great capability to learn representations without annotations, even outperforming supervised baselines. However, it still lacks important properties useful for real-world application, one of which is uncertainty. In this paper, we propose a simple way to generate uncertainty scores for many contrastive methods by re-purposing temperature, a mysterious hyperparameter used for scaling. By observing that temperature controls how sensitive the objective is to specific embedding locations, we aim to learn temperature as an input-dependent variable, treating it as a measure of embedding confidence. We call this approach "Temperature as Uncertainty", or TaU. Through experiments, we demonstrate that TaU is useful for out-of-distribution detection, while remaining competitive with benchmarks on linear evaluation. Moreover, we show that TaU can be learned on top of pretrained models, enabling uncertainty scores to be generated post-hoc with popular off-the-shelf models. In summary, TaU is a simple yet versatile method for generating uncertainties for contrastive learning. Open source code can be found at: https://github.com/mhw32/temperature-as-uncertainty-public.
Reading Between the Demographic Lines: Resolving Sources of Bias in Toxicity Classifiers
Jun 29, 2020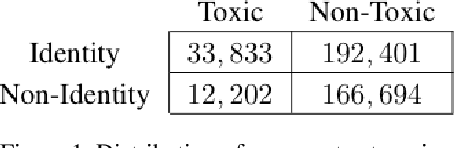
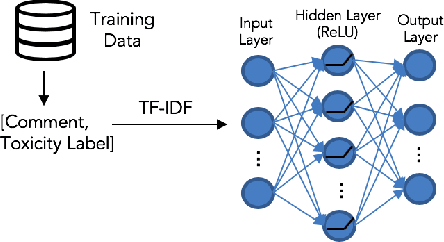
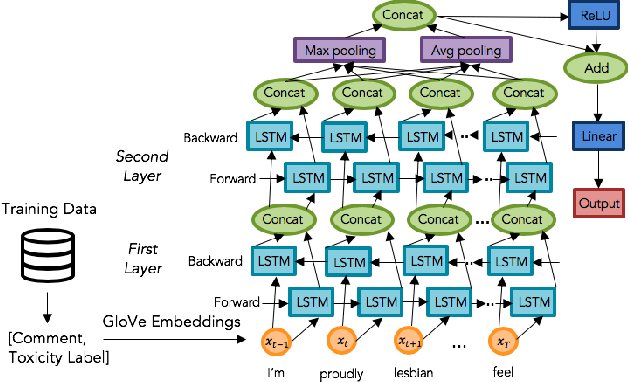
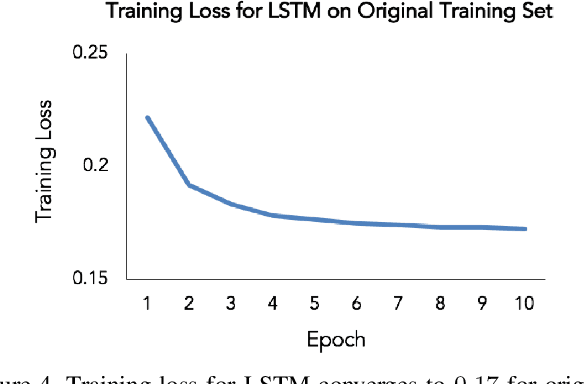
The censorship of toxic comments is often left to the judgment of imperfect models. Perspective API, a creation of Google technology incubator Jigsaw, is perhaps the most widely used toxicity classifier in industry; the model is employed by several online communities including The New York Times to identify and filter out toxic comments with the goal of preserving online safety. Unfortunately, Google's model tends to unfairly assign higher toxicity scores to comments containing words referring to the identities of commonly targeted groups (e.g., "woman,'' "gay,'' etc.) because these identities are frequently referenced in a disrespectful manner in the training data. As a result, comments generated by marginalized groups referencing their identities are often mistakenly censored. It is important to be cognizant of this unintended bias and strive to mitigate its effects. To address this issue, we have constructed several toxicity classifiers with the intention of reducing unintended bias while maintaining strong classification performance.
Keep Your AI-es on the Road: Tackling Distracted Driver Detection with Convolutional Neural Networks and Targeted Data Augmentation
Jun 24, 2020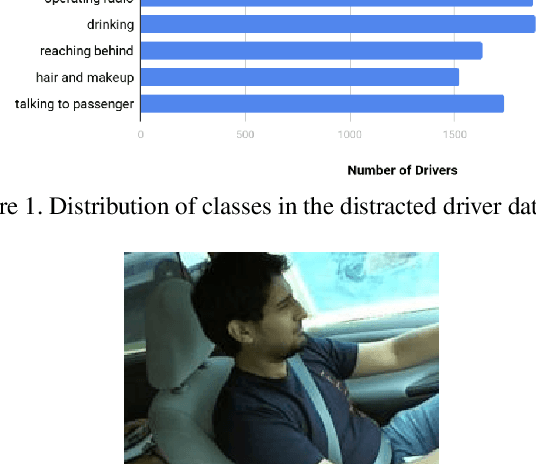


According to the World Health Organization, distracted driving is one of the leading cause of motor accidents and deaths in the world. In our study, we tackle the problem of distracted driving by aiming to build a robust multi-class classifier to detect and identify different forms of driver inattention using the State Farm Distracted Driving Dataset. We utilize combinations of pretrained image classification models, classical data augmentation, OpenCV based image preprocessing and skin segmentation augmentation approaches. Our best performing model combines several augmentation techniques, including skin segmentation, facial blurring, and classical augmentation techniques. This model achieves an approximately 15% increase in F1 score over the baseline, thus showing the promise in these techniques in enhancing the power of neural networks for the task of distracted driver detection.