 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Decentralized Deep Learning with Consensus Algorithms
Paper and Code
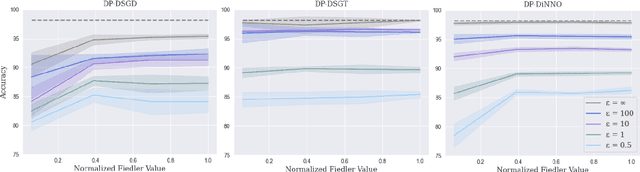

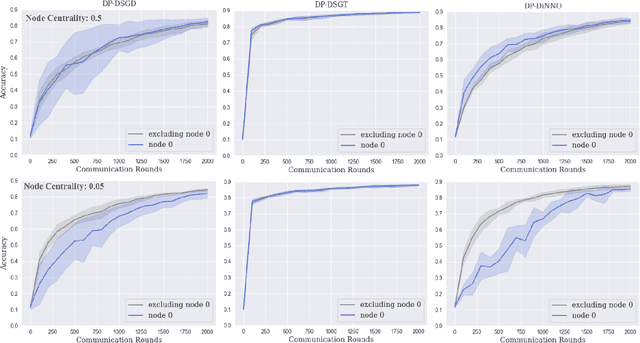
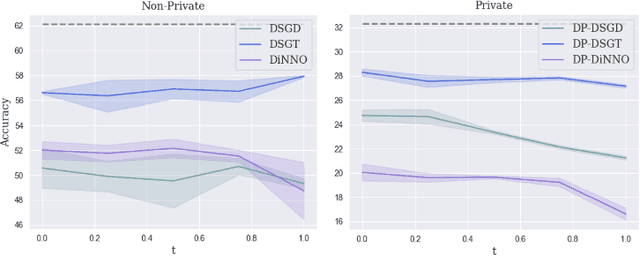
Cooperative decentralized deep learning relies on direct information exchange between communicating agents, each with access to a local dataset which should be kept private. The goal is for all agents to achieve consensus on model parameters after training. However, sharing parameters with untrustworthy neighboring agents could leak exploitable information about local datasets. To combat this, we introduce differentially private decentralized learning that secures each agent's local dataset during and after cooperative training. In our approach, we generalize Differentially Private Stochastic Gradient Descent (DP-SGD) -- a popular differentially private training method for centralized deep learning -- to practical subgradient- and ADMM-based decentralized learning methods. Our algorithms' differential privacy guarantee holds for arbitrary deep learning objective functions, and we analyze the convergence properties for strongly convex objective functions. We compare our algorithms against centrally trained models on standard classification tasks and evaluate the relationships between performance, privacy budget, graph connectivity, and degree of training data overlap among agents. We find that differentially private gradient tracking is resistant to performance degradation under sparse graphs and non-uniform data distributions. Furthermore, we show that it is possible to learn a model achieving high accuracies, within 3% of DP-SGD on MNIST under (1, 10^-5)-differential privacy and within 6% of DP-SGD on CIFAR-100 under (10, 10^-5)-differential privacy, without ever sharing raw data with other agents. Open source code can be found at: https://github.com/jbayrooti/dp-dec-learning.