 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
May 28, 2026We demonstrate that sparse autoencoders can extract interpretable features from Claude 3 Sonnet, a production-scale language model, addressing the open question of whether dictionary learning methods scale beyond small transformers. We trained sparse autoencoders with up to 34 million features on the model's middle layer residual stream, using scaling laws to guide hyperparameter selection. The resulting features are multilingual and multimodal (generalizing to images despite text-only training), respond to both concrete instances and abstract discussions of concepts, and can be used to steer model behavior in ways consistent with their interpretations. We find features corresponding to famous entities and locations, as well as more abstract concepts like sarcasm or errors in code. We also identify features relevant to ways in which language models might cause harm--including features representing deception, power-seeking, sycophancy, and bias--and show that these causally influence model outputs when manipulated. Additionally, we conduct analyses of feature interpretability, geometry, and computational function. However, significant limitations remain: our suite of features is incomplete, and we lack rigorous methods for evaluating whether our features faithfully capture model computations.
How AI Impacts Skill Formation
Jan 28, 2026AI assistance produces significant productivity gains across professional domains, particularly for novice workers. Yet how this assistance affects the development of skills required to effectively supervise AI remains unclear. Novice workers who rely heavily on AI to complete unfamiliar tasks may compromise their own skill acquisition in the process. We conduct randomized experiments to study how developers gained mastery of a new asynchronous programming library with and without the assistance of AI. We find that AI use impairs conceptual understanding, code reading, and debugging abilities, without delivering significant efficiency gains on average. Participants who fully delegated coding tasks showed some productivity improvements, but at the cost of learning the library. We identify six distinct AI interaction patterns, three of which involve cognitive engagement and preserve learning outcomes even when participants receive AI assistance. Our findings suggest that AI-enhanced productivity is not a shortcut to competence and AI assistance should be carefully adopted into workflows to preserve skill formation -- particularly in safety-critical domains.
Values in the Wild: Discovering and Analyzing Values in Real-World Language Model Interactions
Apr 21, 2025



AI assistants can impart value judgments that shape people's decisions and worldviews, yet little is known empirically about what values these systems rely on in practice. To address this, we develop a bottom-up, privacy-preserving method to extract the values (normative considerations stated or demonstrated in model responses) that Claude 3 and 3.5 models exhibit in hundreds of thousands of real-world interactions. We empirically discover and taxonomize 3,307 AI values and study how they vary by context. We find that Claude expresses many practical and epistemic values, and typically supports prosocial human values while resisting values like "moral nihilism". While some values appear consistently across contexts (e.g. "transparency"), many are more specialized and context-dependent, reflecting the diversity of human interlocutors and their varied contexts. For example, "harm prevention" emerges when Claude resists users, "historical accuracy" when responding to queries about controversial events, "healthy boundaries" when asked for relationship advice, and "human agency" in technology ethics discussions. By providing the first large-scale empirical mapping of AI values in deployment, our work creates a foundation for more grounded evaluation and design of values in AI systems.
Clio: Privacy-Preserving Insights into Real-World AI Use
Dec 18, 2024How are AI assistants being used in the real world? While model providers in theory have a window into this impact via their users' data, both privacy concerns and practical challenges have made analyzing this data difficult. To address these issues, we present Clio (Claude insights and observations), a privacy-preserving platform that uses AI assistants themselves to analyze and surface aggregated usage patterns across millions of conversations, without the need for human reviewers to read raw conversations. We validate this can be done with a high degree of accuracy and privacy by conducting extensive evaluations. We demonstrate Clio's usefulness in two broad ways. First, we share insights about how models are being used in the real world from one million Claude.ai Free and Pro conversations, ranging from providing advice on hairstyles to providing guidance on Git operations and concepts. We also identify the most common high-level use cases on Claude.ai (coding, writing, and research tasks) as well as patterns that differ across languages (e.g., conversations in Japanese discuss elder care and aging populations at higher-than-typical rates). Second, we use Clio to make our systems safer by identifying coordinated attempts to abuse our systems, monitoring for unknown unknowns during critical periods like launches of new capabilities or major world events, and improving our existing monitoring systems. We also discuss the limitations of our approach, as well as risks and ethical concerns. By enabling analysis of real-world AI usage, Clio provides a scalable platform for empirically grounded AI safety and governance.
Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models
Jun 17, 2024



In reinforcement learning, specification gaming occurs when AI systems learn undesired behaviors that are highly rewarded due to misspecified training goals. Specification gaming can range from simple behaviors like sycophancy to sophisticated and pernicious behaviors like reward-tampering, where a model directly modifies its own reward mechanism. However, these more pernicious behaviors may be too complex to be discovered via exploration. In this paper, we study whether Large Language Model (LLM) assistants which find easily discovered forms of specification gaming will generalize to perform rarer and more blatant forms, up to and including reward-tampering. We construct a curriculum of increasingly sophisticated gameable environments and find that training on early-curriculum environments leads to more specification gaming on remaining environments. Strikingly, a small but non-negligible proportion of the time, LLM assistants trained on the full curriculum generalize zero-shot to directly rewriting their own reward function. Retraining an LLM not to game early-curriculum environments mitigates, but does not eliminate, reward-tampering in later environments. Moreover, adding harmlessness training to our gameable environments does not prevent reward-tampering. These results demonstrate that LLMs can generalize from common forms of specification gaming to more pernicious reward tampering and that such behavior may be nontrivial to remove.
Collective Constitutional AI: Aligning a Language Model with Public Input
Jun 12, 2024There is growing consensus that language model (LM) developers should not be the sole deciders of LM behavior, creating a need for methods that enable the broader public to collectively shape the behavior of LM systems that affect them. To address this need, we present Collective Constitutional AI (CCAI): a multi-stage process for sourcing and integrating public input into LMs-from identifying a target population to sourcing principles to training and evaluating a model. We demonstrate the real-world practicality of this approach by creating what is, to our knowledge, the first LM fine-tuned with collectively sourced public input and evaluating this model against a baseline model trained with established principles from a LM developer. Our quantitative evaluations demonstrate several benefits of our approach: the CCAI-trained model shows lower bias across nine social dimensions compared to the baseline model, while maintaining equivalent performance on language, math, and helpful-harmless evaluations. Qualitative comparisons of the models suggest that the models differ on the basis of their respective constitutions, e.g., when prompted with contentious topics, the CCAI-trained model tends to generate responses that reframe the matter positively instead of a refusal. These results demonstrate a promising, tractable pathway toward publicly informed development of language models.
Bayesian Preference Elicitation with Language Models
Mar 08, 2024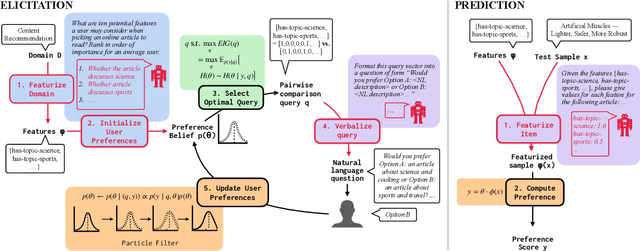
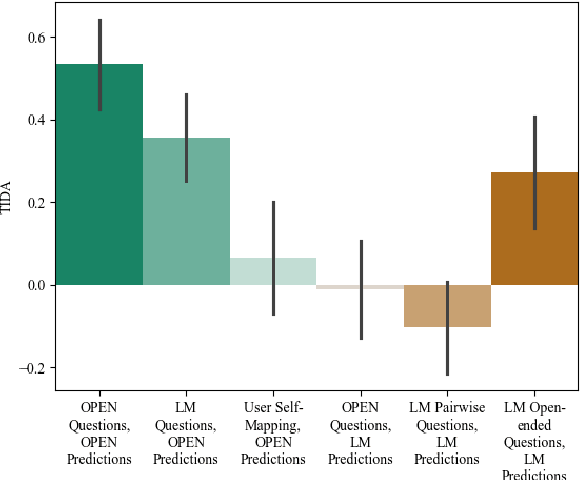
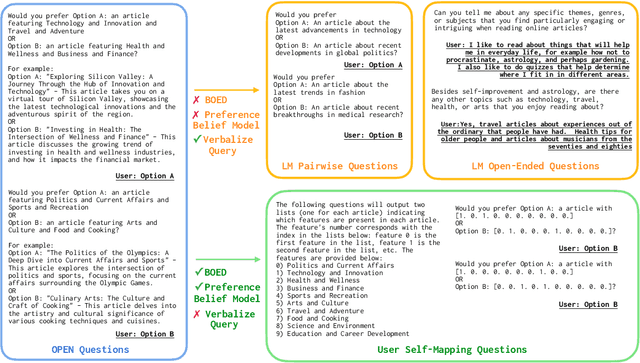

Aligning AI systems to users' interests requires understanding and incorporating humans' complex values and preferences. Recently, language models (LMs) have been used to gather information about the preferences of human users. This preference data can be used to fine-tune or guide other LMs and/or AI systems. However, LMs have been shown to struggle with crucial aspects of preference learning: quantifying uncertainty, modeling human mental states, and asking informative questions. These challenges have been addressed in other areas of machine learning, such as Bayesian Optimal Experimental Design (BOED), which focus on designing informative queries within a well-defined feature space. But these methods, in turn, are difficult to scale and apply to real-world problems where simply identifying the relevant features can be difficult. We introduce OPEN (Optimal Preference Elicitation with Natural language) a framework that uses BOED to guide the choice of informative questions and an LM to extract features and translate abstract BOED queries into natural language questions. By combining the flexibility of LMs with the rigor of BOED, OPEN can optimize the informativity of queries while remaining adaptable to real-world domains. In user studies, we find that OPEN outperforms existing LM- and BOED-based methods for preference elicitation.
Evaluating and Mitigating Discrimination in Language Model Decisions
Dec 06, 2023



As language models (LMs) advance, interest is growing in applying them to high-stakes societal decisions, such as determining financing or housing eligibility. However, their potential for discrimination in such contexts raises ethical concerns, motivating the need for better methods to evaluate these risks. We present a method for proactively evaluating the potential discriminatory impact of LMs in a wide range of use cases, including hypothetical use cases where they have not yet been deployed. Specifically, we use an LM to generate a wide array of potential prompts that decision-makers may input into an LM, spanning 70 diverse decision scenarios across society, and systematically vary the demographic information in each prompt. Applying this methodology reveals patterns of both positive and negative discrimination in the Claude 2.0 model in select settings when no interventions are applied. While we do not endorse or permit the use of language models to make automated decisions for the high-risk use cases we study, we demonstrate techniques to significantly decrease both positive and negative discrimination through careful prompt engineering, providing pathways toward safer deployment in use cases where they may be appropriate. Our work enables developers and policymakers to anticipate, measure, and address discrimination as language model capabilities and applications continue to expand. We release our dataset and prompts at https://huggingface.co/datasets/Anthropic/discrim-eval
Social Contract AI: Aligning AI Assistants with Implicit Group Norms
Oct 26, 2023We explore the idea of aligning an AI assistant by inverting a model of users' (unknown) preferences from observed interactions. To validate our proposal, we run proof-of-concept simulations in the economic ultimatum game, formalizing user preferences as policies that guide the actions of simulated players. We find that the AI assistant accurately aligns its behavior to match standard policies from the economic literature (e.g., selfish, altruistic). However, the assistant's learned policies lack robustness and exhibit limited generalization in an out-of-distribution setting when confronted with a currency (e.g., grams of medicine) that was not included in the assistant's training distribution. Additionally, we find that when there is inconsistency in the relationship between language use and an unknown policy (e.g., an altruistic policy combined with rude language), the assistant's learning of the policy is slowed. Overall, our preliminary results suggest that developing simulation frameworks in which AI assistants need to infer preferences from diverse users can provide a valuable approach for studying practical alignment questions.
Codebook Features: Sparse and Discrete Interpretability for Neural Networks
Oct 26, 2023



Understanding neural networks is challenging in part because of the dense, continuous nature of their hidden states. We explore whether we can train neural networks to have hidden states that are sparse, discrete, and more interpretable by quantizing their continuous features into what we call codebook features. Codebook features are produced by finetuning neural networks with vector quantization bottlenecks at each layer, producing a network whose hidden features are the sum of a small number of discrete vector codes chosen from a larger codebook. Surprisingly, we find that neural networks can operate under this extreme bottleneck with only modest degradation in performance. This sparse, discrete bottleneck also provides an intuitive way of controlling neural network behavior: first, find codes that activate when the desired behavior is present, then activate those same codes during generation to elicit that behavior. We validate our approach by training codebook Transformers on several different datasets. First, we explore a finite state machine dataset with far more hidden states than neurons. In this setting, our approach overcomes the superposition problem by assigning states to distinct codes, and we find that we can make the neural network behave as if it is in a different state by activating the code for that state. Second, we train Transformer language models with up to 410M parameters on two natural language datasets. We identify codes in these models representing diverse, disentangled concepts (ranging from negative emotions to months of the year) and find that we can guide the model to generate different topics by activating the appropriate codes during inference. Overall, codebook features appear to be a promising unit of analysis and control for neural networks and interpretability. Our codebase and models are open-sourced at https://github.com/taufeeque9/codebook-features.