 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models
Jun 17, 2024



In reinforcement learning, specification gaming occurs when AI systems learn undesired behaviors that are highly rewarded due to misspecified training goals. Specification gaming can range from simple behaviors like sycophancy to sophisticated and pernicious behaviors like reward-tampering, where a model directly modifies its own reward mechanism. However, these more pernicious behaviors may be too complex to be discovered via exploration. In this paper, we study whether Large Language Model (LLM) assistants which find easily discovered forms of specification gaming will generalize to perform rarer and more blatant forms, up to and including reward-tampering. We construct a curriculum of increasingly sophisticated gameable environments and find that training on early-curriculum environments leads to more specification gaming on remaining environments. Strikingly, a small but non-negligible proportion of the time, LLM assistants trained on the full curriculum generalize zero-shot to directly rewriting their own reward function. Retraining an LLM not to game early-curriculum environments mitigates, but does not eliminate, reward-tampering in later environments. Moreover, adding harmlessness training to our gameable environments does not prevent reward-tampering. These results demonstrate that LLMs can generalize from common forms of specification gaming to more pernicious reward tampering and that such behavior may be nontrivial to remove.
Fourier-Based Augmentations for Improved Robustness and Uncertainty Calibration
Feb 24, 2022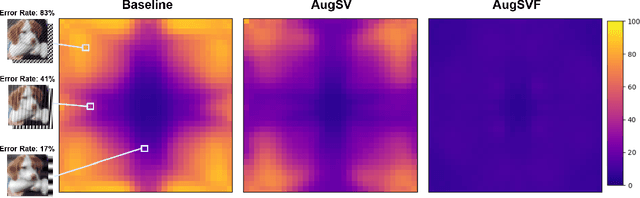
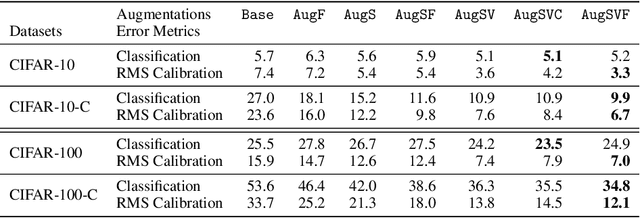
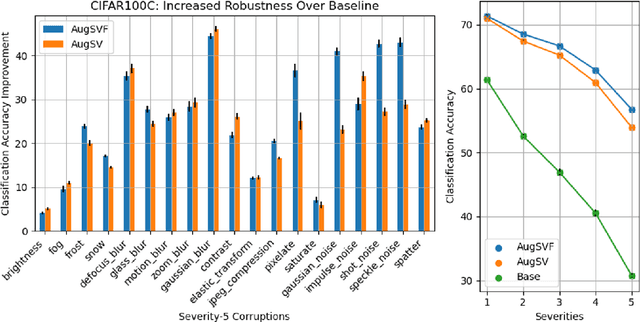
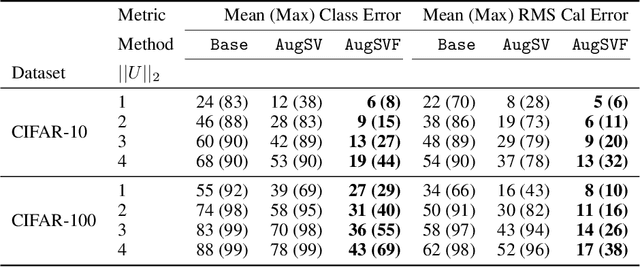
Diverse data augmentation strategies are a natural approach to improving robustness in computer vision models against unforeseen shifts in data distribution. However, the ability to tailor such strategies to inoculate a model against specific classes of corruptions or attacks -- without incurring substantial losses in robustness against other classes of corruptions -- remains elusive. In this work, we successfully harden a model against Fourier-based attacks, while producing superior-to-AugMix accuracy and calibration results on both the CIFAR-10-C and CIFAR-100-C datasets; classification error is reduced by over ten percentage points for some high-severity noise and digital-type corruptions. We achieve this by incorporating Fourier-basis perturbations in the AugMix image-augmentation framework. Thus we demonstrate that the AugMix framework can be tailored to effectively target particular distribution shifts, while boosting overall model robustness.
Tools and Practices for Responsible AI Engineering
Jan 14, 2022Responsible Artificial Intelligence (AI) - the practice of developing, evaluating, and maintaining accurate AI systems that also exhibit essential properties such as robustness and explainability - represents a multifaceted challenge that often stretches standard machine learning tooling, frameworks, and testing methods beyond their limits. In this paper, we present two new software libraries - hydra-zen and the rAI-toolbox - that address critical needs for responsible AI engineering. hydra-zen dramatically simplifies the process of making complex AI applications configurable, and their behaviors reproducible. The rAI-toolbox is designed to enable methods for evaluating and enhancing the robustness of AI-models in a way that is scalable and that composes naturally with other popular ML frameworks. We describe the design principles and methodologies that make these tools effective, including the use of property-based testing to bolster the reliability of the tools themselves. Finally, we demonstrate the composability and flexibility of the tools by showing how various use cases from adversarial robustness and explainable AI can be concisely implemented with familiar APIs.
Transparency by Design: Closing the Gap Between Performance and Interpretability in Visual Reasoning
Jul 02, 2018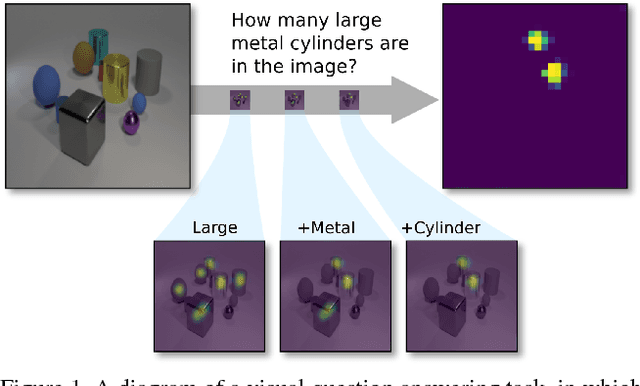


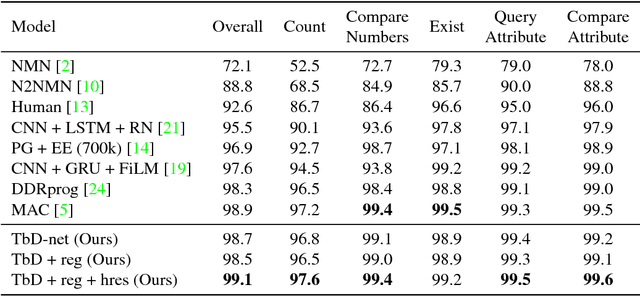
Visual question answering requires high-order reasoning about an image, which is a fundamental capability needed by machine systems to follow complex directives. Recently, modular networks have been shown to be an effective framework for performing visual reasoning tasks. While modular networks were initially designed with a degree of model transparency, their performance on complex visual reasoning benchmarks was lacking. Current state-of-the-art approaches do not provide an effective mechanism for understanding the reasoning process. In this paper, we close the performance gap between interpretable models and state-of-the-art visual reasoning methods. We propose a set of visual-reasoning primitives which, when composed, manifest as a model capable of performing complex reasoning tasks in an explicitly-interpretable manner. The fidelity and interpretability of the primitives' outputs enable an unparalleled ability to diagnose the strengths and weaknesses of the resulting model. Critically, we show that these primitives are highly performant, achieving state-of-the-art accuracy of 99.1% on the CLEVR dataset. We also show that our model is able to effectively learn generalized representations when provided a small amount of data containing novel object attributes. Using the CoGenT generalization task, we show more than a 20 percentage point improvement over the current state of the art.