 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Acquisition & Representation of Subsurface Scattering
Jun 01, 2026We present a method to acquire and estimate the sub-surface scattering properties of light transport at a highly detailed level by learning the pixel footprint response at each point on the object surface. The reconstruction leverages 3D scanning techniques as input to a U-Net CNN. A stereo projector-camera setup using phase-shifted profilometry (PSP) patterns efficiently captures the data for a variety of scattering objects. Reconstructing dense pixel footprints allows for relighting with arbitrary high-resolution projector patterns. The final output is a relit color image. Qualitative and quantitative comparison against illuminated real-world captured images demonstrate that the predicted footprints are almost identical to the actual responses. The same model is trained for multiple views across multiple objects such that the learned representations can be used to generalize to unseen sub-surface scattering materials as well.
Voxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Locate 3D: Real-World Object Localization via Self-Supervised Learning in 3D
Apr 19, 2025We present LOCATE 3D, a model for localizing objects in 3D scenes from referring expressions like "the small coffee table between the sofa and the lamp." LOCATE 3D sets a new state-of-the-art on standard referential grounding benchmarks and showcases robust generalization capabilities. Notably, LOCATE 3D operates directly on sensor observation streams (posed RGB-D frames), enabling real-world deployment on robots and AR devices. Key to our approach is 3D-JEPA, a novel self-supervised learning (SSL) algorithm applicable to sensor point clouds. It takes as input a 3D pointcloud featurized using 2D foundation models (CLIP, DINO). Subsequently, masked prediction in latent space is employed as a pretext task to aid the self-supervised learning of contextualized pointcloud features. Once trained, the 3D-JEPA encoder is finetuned alongside a language-conditioned decoder to jointly predict 3D masks and bounding boxes. Additionally, we introduce LOCATE 3D DATASET, a new dataset for 3D referential grounding, spanning multiple capture setups with over 130K annotations. This enables a systematic study of generalization capabilities as well as a stronger model.
Subsurface Scattering for 3D Gaussian Splatting
Aug 22, 2024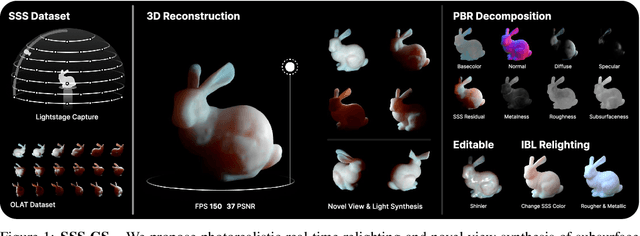
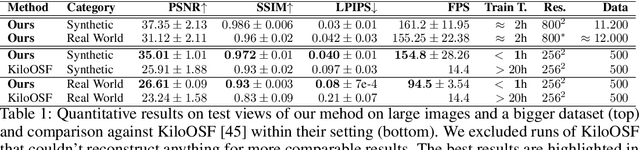
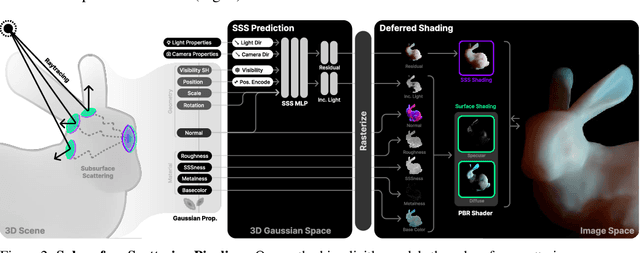

3D reconstruction and relighting of objects made from scattering materials present a significant challenge due to the complex light transport beneath the surface. 3D Gaussian Splatting introduced high-quality novel view synthesis at real-time speeds. While 3D Gaussians efficiently approximate an object's surface, they fail to capture the volumetric properties of subsurface scattering. We propose a framework for optimizing an object's shape together with the radiance transfer field given multi-view OLAT (one light at a time) data. Our method decomposes the scene into an explicit surface represented as 3D Gaussians, with a spatially varying BRDF, and an implicit volumetric representation of the scattering component. A learned incident light field accounts for shadowing. We optimize all parameters jointly via ray-traced differentiable rendering. Our approach enables material editing, relighting and novel view synthesis at interactive rates. We show successful application on synthetic data and introduce a newly acquired multi-view multi-light dataset of objects in a light-stage setup. Compared to previous work we achieve comparable or better results at a fraction of optimization and rendering time while enabling detailed control over material attributes. Project page https://sss.jdihlmann.com/
Stretch with Stretch: Physical Therapy Exercise Games Led by a Mobile Manipulator
Dec 21, 2023



Physical therapy (PT) is a key component of many rehabilitation regimens, such as treatments for Parkinson's disease (PD). However, there are shortages of physical therapists and adherence to self-guided PT is low. Robots have the potential to support physical therapists and increase adherence to self-guided PT, but prior robotic systems have been large and immobile, which can be a barrier to use in homes and clinics. We present Stretch with Stretch (SWS), a novel robotic system for leading stretching exercise games for older adults with PD. SWS consists of a compact and lightweight mobile manipulator (Hello Robot Stretch RE1) that visually and verbally guides users through PT exercises. The robot's soft end effector serves as a target that users repetitively reach towards and press with a hand, foot, or knee. For each exercise, target locations are customized for the individual via a visually estimated kinematic model, a haptically estimated range of motion, and the person's exercise performance. The system includes sound effects and verbal feedback from the robot to keep users engaged throughout a session and augment physical exercise with cognitive exercise. We conducted a user study for which people with PD (n=10) performed 6 exercises with the system. Participants perceived the SWS to be useful and easy to use. They also reported mild to moderate perceived exertion (RPE).
What do we learn from a large-scale study of pre-trained visual representations in sim and real environments?
Oct 03, 2023



We present a large empirical investigation on the use of pre-trained visual representations (PVRs) for training downstream policies that execute real-world tasks. Our study spans five different PVRs, two different policy-learning paradigms (imitation and reinforcement learning), and three different robots for 5 distinct manipulation and indoor navigation tasks. From this effort, we can arrive at three insights: 1) the performance trends of PVRs in the simulation are generally indicative of their trends in the real world, 2) the use of PVRs enables a first-of-its-kind result with indoor ImageNav (zero-shot transfer to a held-out scene in the real world), and 3) the benefits from variations in PVRs, primarily data-augmentation and fine-tuning, also transfer to the real-world performance. See project website for additional details and visuals.
Behavioral Analysis of Vision-and-Language Navigation Agents
Jul 20, 2023



To be successful, Vision-and-Language Navigation (VLN) agents must be able to ground instructions to actions based on their surroundings. In this work, we develop a methodology to study agent behavior on a skill-specific basis -- examining how well existing agents ground instructions about stopping, turning, and moving towards specified objects or rooms. Our approach is based on generating skill-specific interventions and measuring changes in agent predictions. We present a detailed case study analyzing the behavior of a recent agent and then compare multiple agents in terms of skill-specific competency scores. This analysis suggests that biases from training have lasting effects on agent behavior and that existing models are able to ground simple referring expressions. Our comparisons between models show that skill-specific scores correlate with improvements in overall VLN task performance.
* accepted to CVPR2023
Masked Trajectory Models for Prediction, Representation, and Control
May 04, 2023



We introduce Masked Trajectory Models (MTM) as a generic abstraction for sequential decision making. MTM takes a trajectory, such as a state-action sequence, and aims to reconstruct the trajectory conditioned on random subsets of the same trajectory. By training with a highly randomized masking pattern, MTM learns versatile networks that can take on different roles or capabilities, by simply choosing appropriate masks at inference time. For example, the same MTM network can be used as a forward dynamics model, inverse dynamics model, or even an offline RL agent. Through extensive experiments in several continuous control tasks, we show that the same MTM network -- i.e. same weights -- can match or outperform specialized networks trained for the aforementioned capabilities. Additionally, we find that state representations learned by MTM can significantly accelerate the learning speed of traditional RL algorithms. Finally, in offline RL benchmarks, we find that MTM is competitive with specialized offline RL algorithms, despite MTM being a generic self-supervised learning method without any explicit RL components. Code is available at https://github.com/facebookresearch/mtm
Where are we in the search for an Artificial Visual Cortex for Embodied Intelligence?
Mar 31, 2023



We present the largest and most comprehensive empirical study of pre-trained visual representations (PVRs) or visual 'foundation models' for Embodied AI. First, we curate CortexBench, consisting of 17 different tasks spanning locomotion, navigation, dexterous, and mobile manipulation. Next, we systematically evaluate existing PVRs and find that none are universally dominant. To study the effect of pre-training data scale and diversity, we combine over 4,000 hours of egocentric videos from 7 different sources (over 5.6M images) and ImageNet to train different-sized vision transformers using Masked Auto-Encoding (MAE) on slices of this data. Contrary to inferences from prior work, we find that scaling dataset size and diversity does not improve performance universally (but does so on average). Our largest model, named VC-1, outperforms all prior PVRs on average but does not universally dominate either. Finally, we show that task or domain-specific adaptation of VC-1 leads to substantial gains, with VC-1 (adapted) achieving competitive or superior performance than the best known results on all of the benchmarks in CortexBench. These models required over 10,000 GPU-hours to train and can be found on our website for the benefit of the research community.