 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOC-SLT: Partial Object Completion with SDF Latent Transformers
Nov 08, 2024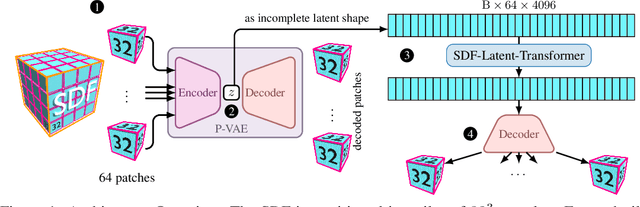

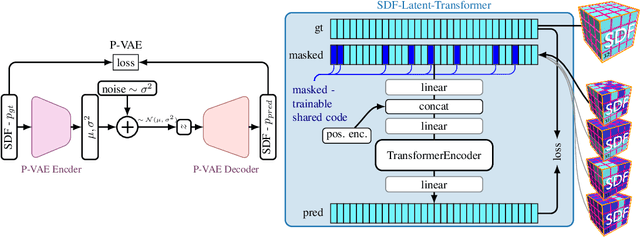
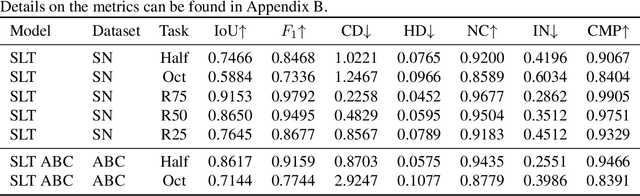
3D geometric shape completion hinges on representation learning and a deep understanding of geometric data. Without profound insights into the three-dimensional nature of the data, this task remains unattainable. Our work addresses this challenge of 3D shape completion given partial observations by proposing a transformer operating on the latent space representing Signed Distance Fields (SDFs). Instead of a monolithic volume, the SDF of an object is partitioned into smaller high-resolution patches leading to a sequence of latent codes. The approach relies on a smooth latent space encoding learned via a variational autoencoder (VAE), trained on millions of 3D patches. We employ an efficient masked autoencoder transformer to complete partial sequences into comprehensive shapes in latent space. Our approach is extensively evaluated on partial observations from ShapeNet and the ABC dataset where only fractions of the objects are given. The proposed POC-SLT architecture compares favorably with several baseline state-of-the-art methods, demonstrating a significant improvement in 3D shape completion, both qualitatively and quantitatively.
Subsurface Scattering for 3D Gaussian Splatting
Aug 22, 2024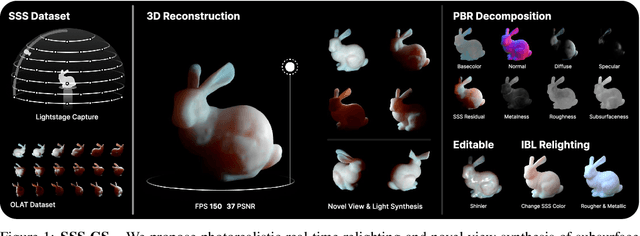
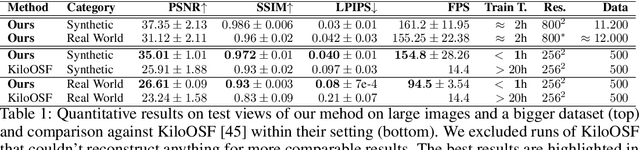
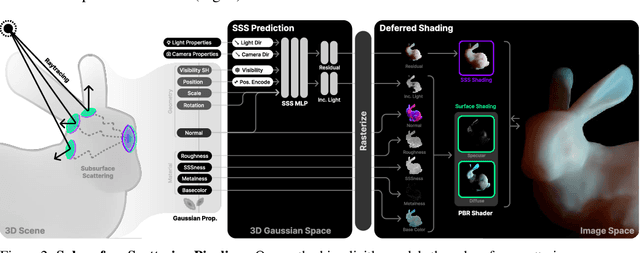

3D reconstruction and relighting of objects made from scattering materials present a significant challenge due to the complex light transport beneath the surface. 3D Gaussian Splatting introduced high-quality novel view synthesis at real-time speeds. While 3D Gaussians efficiently approximate an object's surface, they fail to capture the volumetric properties of subsurface scattering. We propose a framework for optimizing an object's shape together with the radiance transfer field given multi-view OLAT (one light at a time) data. Our method decomposes the scene into an explicit surface represented as 3D Gaussians, with a spatially varying BRDF, and an implicit volumetric representation of the scattering component. A learned incident light field accounts for shadowing. We optimize all parameters jointly via ray-traced differentiable rendering. Our approach enables material editing, relighting and novel view synthesis at interactive rates. We show successful application on synthetic data and introduce a newly acquired multi-view multi-light dataset of objects in a light-stage setup. Compared to previous work we achieve comparable or better results at a fraction of optimization and rendering time while enabling detailed control over material attributes. Project page https://sss.jdihlmann.com/
CANDID: Correspondence AligNment for Deep-burst Image Denoising
Jun 16, 2023With the advent of mobile phone photography and point-and-shoot cameras, deep-burst imaging is widely used for a number of photographic effects such as depth of field, super-resolution, motion deblurring, and image denoising. In this work, we propose to solve the problem of deep-burst image denoising by including an optical flow-based correspondence estimation module which aligns all the input burst images with respect to a reference frame. In order to deal with varying noise levels the individual burst images are pre-filtered with different settings. Exploiting the established correspondences one network block predicts a pixel-wise spatially-varying filter kernel to smooth each image in the original and prefiltered bursts before fusing all images to generate the final denoised output. The resulting pipeline achieves state-of-the-art results by combining all available information provided by the burst.
Neural-PIL: Neural Pre-Integrated Lighting for Reflectance Decomposition
Oct 27, 2021
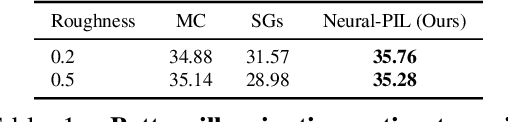


Decomposing a scene into its shape, reflectance and illumination is a fundamental problem in computer vision and graphics. Neural approaches such as NeRF have achieved remarkable success in view synthesis, but do not explicitly perform decomposition and instead operate exclusively on radiance (the product of reflectance and illumination). Extensions to NeRF, such as NeRD, can perform decomposition but struggle to accurately recover detailed illumination, thereby significantly limiting realism. We propose a novel reflectance decomposition network that can estimate shape, BRDF, and per-image illumination given a set of object images captured under varying illumination. Our key technique is a novel illumination integration network called Neural-PIL that replaces a costly illumination integral operation in the rendering with a simple network query. In addition, we also learn deep low-dimensional priors on BRDF and illumination representations using novel smooth manifold auto-encoders. Our decompositions can result in considerably better BRDF and light estimates enabling more accurate novel view-synthesis and relighting compared to prior art. Project page: https://markboss.me/publication/2021-neural-pil/
NeRD: Neural Reflectance Decomposition from Image Collections
Dec 08, 2020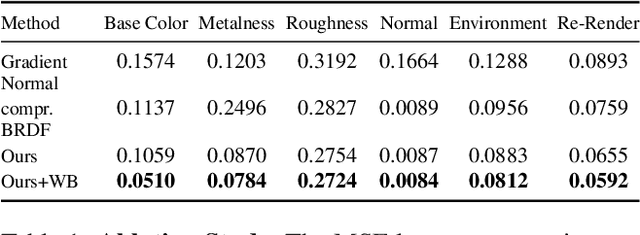
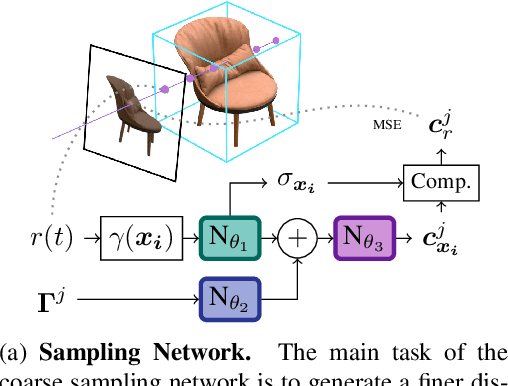

Decomposing a scene into its shape, reflectance, and illumination is a challenging but essential problem in computer vision and graphics. This problem is inherently more challenging when the illumination is not a single light source under laboratory conditions but is instead an unconstrained environmental illumination. Though recent work has shown that implicit representations can be used to model the radiance field of an object, these techniques only enable view synthesis and not relighting. Additionally, evaluating these radiance fields is resource and time-intensive. By decomposing a scene into explicit representations, any rendering framework can be leveraged to generate novel views under any illumination in real-time. NeRD is a method that achieves this decomposition by introducing physically-based rendering to neural radiance fields. Even challenging non-Lambertian reflectances, complex geometry, and unknown illumination can be decomposed to high-quality models. The datasets and code is available at the project page: https://markboss.me/publication/2021-nerd/