 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
DicFace: Dirichlet-Constrained Variational Codebook Learning for Temporally Coherent Video Face Restoration
Jun 16, 2025



Video face restoration faces a critical challenge in maintaining temporal consistency while recovering fine facial details from degraded inputs. This paper presents a novel approach that extends Vector-Quantized Variational Autoencoders (VQ-VAEs), pretrained on static high-quality portraits, into a video restoration framework through variational latent space modeling. Our key innovation lies in reformulating discrete codebook representations as Dirichlet-distributed continuous variables, enabling probabilistic transitions between facial features across frames. A spatio-temporal Transformer architecture jointly models inter-frame dependencies and predicts latent distributions, while a Laplacian-constrained reconstruction loss combined with perceptual (LPIPS) regularization enhances both pixel accuracy and visual quality. Comprehensive evaluations on blind face restoration, video inpainting, and facial colorization tasks demonstrate state-of-the-art performance. This work establishes an effective paradigm for adapting intensive image priors, pretrained on high-quality images, to video restoration while addressing the critical challenge of flicker artifacts. The source code has been open-sourced and is available at https://github.com/fudan-generative-vision/DicFace.
Simulating the Real World: A Unified Survey of Multimodal Generative Models
Mar 06, 2025



Understanding and replicating the real world is a critical challenge in Artificial General Intelligence (AGI) research. To achieve this, many existing approaches, such as world models, aim to capture the fundamental principles governing the physical world, enabling more accurate simulations and meaningful interactions. However, current methods often treat different modalities, including 2D (images), videos, 3D, and 4D representations, as independent domains, overlooking their interdependencies. Additionally, these methods typically focus on isolated dimensions of reality without systematically integrating their connections. In this survey, we present a unified survey for multimodal generative models that investigate the progression of data dimensionality in real-world simulation. Specifically, this survey starts from 2D generation (appearance), then moves to video (appearance+dynamics) and 3D generation (appearance+geometry), and finally culminates in 4D generation that integrate all dimensions. To the best of our knowledge, this is the first attempt to systematically unify the study of 2D, video, 3D and 4D generation within a single framework. To guide future research, we provide a comprehensive review of datasets, evaluation metrics and future directions, and fostering insights for newcomers. This survey serves as a bridge to advance the study of multimodal generative models and real-world simulation within a unified framework.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Dynamic PDB: A New Dataset and a SE(3) Model Extension by Integrating Dynamic Behaviors and Physical Properties in Protein Structures
Aug 22, 2024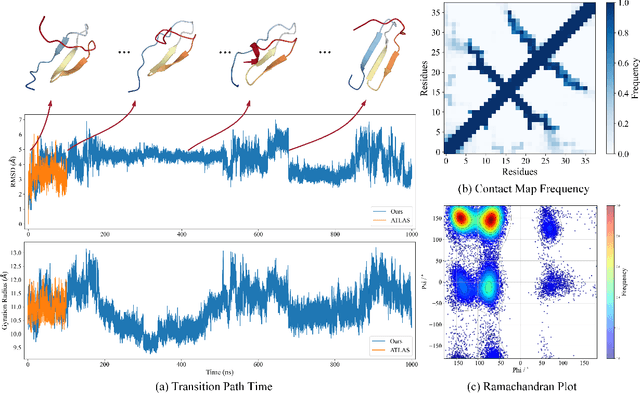
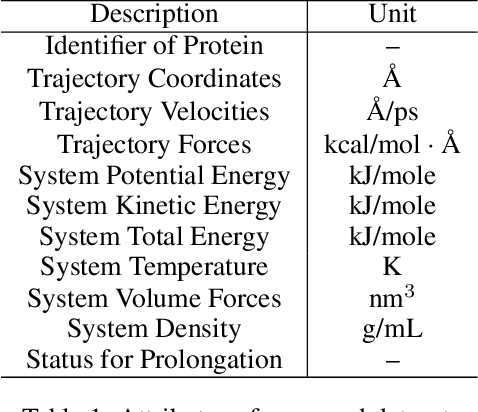

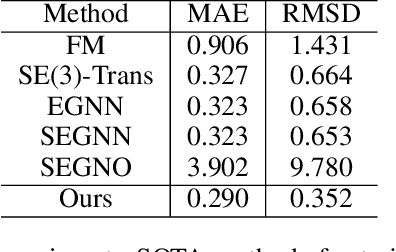
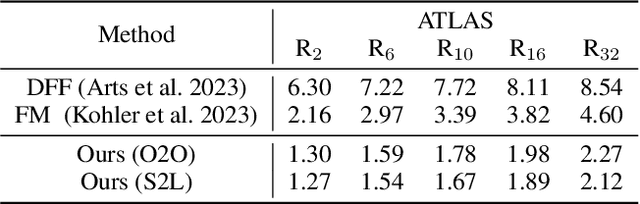
Despite significant progress in static protein structure collection and prediction, the dynamic behavior of proteins, one of their most vital characteristics, has been largely overlooked in prior research. This oversight can be attributed to the limited availability, diversity, and heterogeneity of dynamic protein datasets. To address this gap, we propose to enhance existing prestigious static 3D protein structural databases, such as the Protein Data Bank (PDB), by integrating dynamic data and additional physical properties. Specifically, we introduce a large-scale dataset, Dynamic PDB, encompassing approximately 12.6K proteins, each subjected to all-atom molecular dynamics (MD) simulations lasting 1 microsecond to capture conformational changes. Furthermore, we provide a comprehensive suite of physical properties, including atomic velocities and forces, potential and kinetic energies of proteins, and the temperature of the simulation environment, recorded at 1 picosecond intervals throughout the simulations. For benchmarking purposes, we evaluate state-of-the-art methods on the proposed dataset for the task of trajectory prediction. To demonstrate the value of integrating richer physical properties in the study of protein dynamics and related model design, we base our approach on the SE(3) diffusion model and incorporate these physical properties into the trajectory prediction process. Preliminary results indicate that this straightforward extension of the SE(3) model yields improved accuracy, as measured by MAE and RMSD, when the proposed physical properties are taken into consideration.
4D Diffusion for Dynamic Protein Structure Prediction with Reference Guided Motion Alignment
Aug 22, 2024
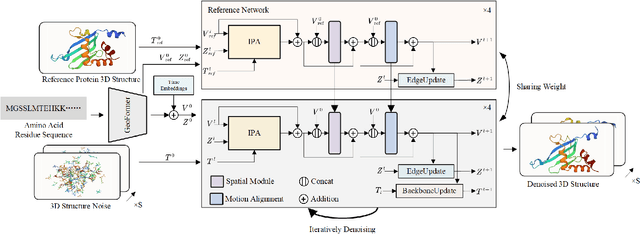
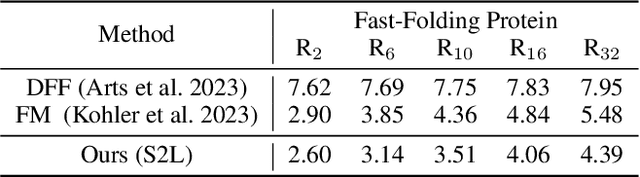
Protein structure prediction is pivotal for understanding the structure-function relationship of proteins, advancing biological research, and facilitating pharmaceutical development and experimental design. While deep learning methods and the expanded availability of experimental 3D protein structures have accelerated structure prediction, the dynamic nature of protein structures has received limited attention. This study introduces an innovative 4D diffusion model incorporating molecular dynamics (MD) simulation data to learn dynamic protein structures. Our approach is distinguished by the following components: (1) a unified diffusion model capable of generating dynamic protein structures, including both the backbone and side chains, utilizing atomic grouping and side-chain dihedral angle predictions; (2) a reference network that enhances structural consistency by integrating the latent embeddings of the initial 3D protein structures; and (3) a motion alignment module aimed at improving temporal structural coherence across multiple time steps. To our knowledge, this is the first diffusion-based model aimed at predicting protein trajectories across multiple time steps simultaneously. Validation on benchmark datasets demonstrates that our model exhibits high accuracy in predicting dynamic 3D structures of proteins containing up to 256 amino acids over 32 time steps, effectively capturing both local flexibility in stable states and significant conformational changes.
Stereo Risk: A Continuous Modeling Approach to Stereo Matching
Jul 03, 2024We introduce Stereo Risk, a new deep-learning approach to solve the classical stereo-matching problem in computer vision. As it is well-known that stereo matching boils down to a per-pixel disparity estimation problem, the popular state-of-the-art stereo-matching approaches widely rely on regressing the scene disparity values, yet via discretization of scene disparity values. Such discretization often fails to capture the nuanced, continuous nature of scene depth. Stereo Risk departs from the conventional discretization approach by formulating the scene disparity as an optimal solution to a continuous risk minimization problem, hence the name "stereo risk". We demonstrate that $L^1$ minimization of the proposed continuous risk function enhances stereo-matching performance for deep networks, particularly for disparities with multi-modal probability distributions. Furthermore, to enable the end-to-end network training of the non-differentiable $L^1$ risk optimization, we exploited the implicit function theorem, ensuring a fully differentiable network. A comprehensive analysis demonstrates our method's theoretical soundness and superior performance over the state-of-the-art methods across various benchmark datasets, including KITTI 2012, KITTI 2015, ETH3D, SceneFlow, and Middlebury 2014.
Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation
Jun 16, 2024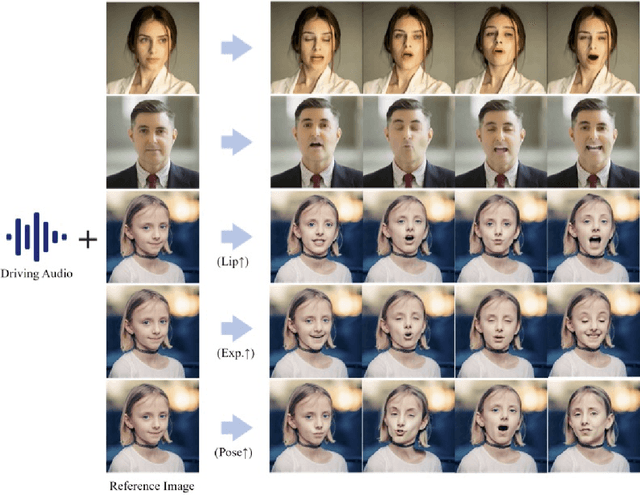
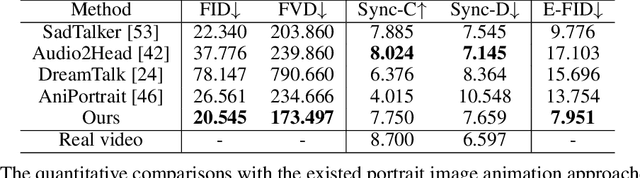
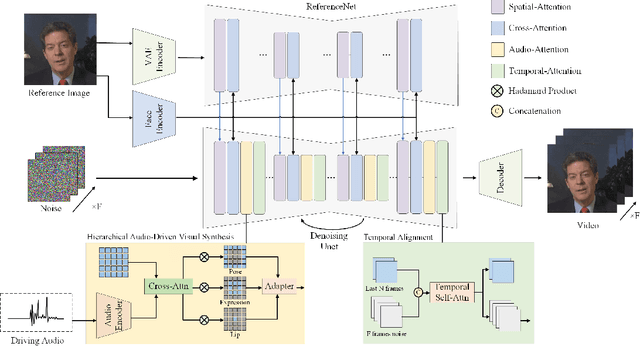
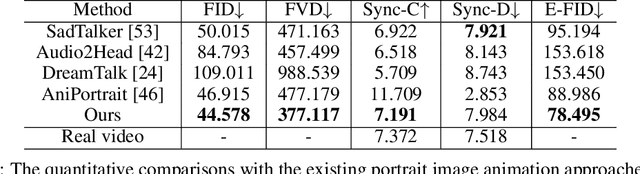
The field of portrait image animation, driven by speech audio input, has experienced significant advancements in the generation of realistic and dynamic portraits. This research delves into the complexities of synchronizing facial movements and creating visually appealing, temporally consistent animations within the framework of diffusion-based methodologies. Moving away from traditional paradigms that rely on parametric models for intermediate facial representations, our innovative approach embraces the end-to-end diffusion paradigm and introduces a hierarchical audio-driven visual synthesis module to enhance the precision of alignment between audio inputs and visual outputs, encompassing lip, expression, and pose motion. Our proposed network architecture seamlessly integrates diffusion-based generative models, a UNet-based denoiser, temporal alignment techniques, and a reference network. The proposed hierarchical audio-driven visual synthesis offers adaptive control over expression and pose diversity, enabling more effective personalization tailored to different identities. Through a comprehensive evaluation that incorporates both qualitative and quantitative analyses, our approach demonstrates obvious enhancements in image and video quality, lip synchronization precision, and motion diversity. Further visualization and access to the source code can be found at: https://fudan-generative-vision.github.io/hallo.
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Nov 10, 2023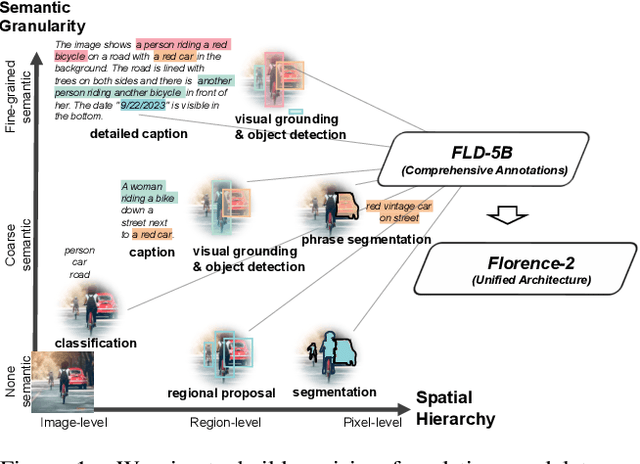
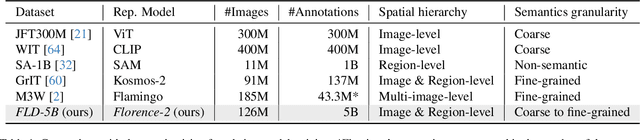
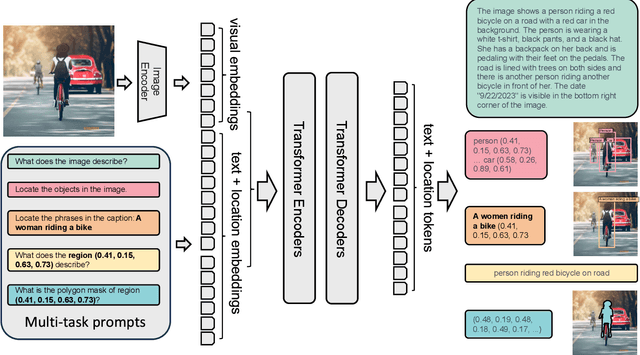
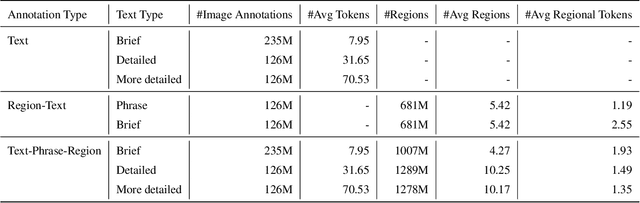
We introduce Florence-2, a novel vision foundation model with a unified, prompt-based representation for a variety of computer vision and vision-language tasks. While existing large vision models excel in transfer learning, they struggle to perform a diversity of tasks with simple instructions, a capability that implies handling the complexity of various spatial hierarchy and semantic granularity. Florence-2 was designed to take text-prompt as task instructions and generate desirable results in text forms, whether it be captioning, object detection, grounding or segmentation. This multi-task learning setup demands large-scale, high-quality annotated data. To this end, we co-developed FLD-5B that consists of 5.4 billion comprehensive visual annotations on 126 million images, using an iterative strategy of automated image annotation and model refinement. We adopted a sequence-to-sequence structure to train Florence-2 to perform versatile and comprehensive vision tasks. Extensive evaluations on numerous tasks demonstrated Florence-2 to be a strong vision foundation model contender with unprecedented zero-shot and fine-tuning capabilities.
MM-VID: Advancing Video Understanding with GPT-4V
Oct 30, 2023



We present MM-VID, an integrated system that harnesses the capabilities of GPT-4V, combined with specialized tools in vision, audio, and speech, to facilitate advanced video understanding. MM-VID is designed to address the challenges posed by long-form videos and intricate tasks such as reasoning within hour-long content and grasping storylines spanning multiple episodes. MM-VID uses a video-to-script generation with GPT-4V to transcribe multimodal elements into a long textual script. The generated script details character movements, actions, expressions, and dialogues, paving the way for large language models (LLMs) to achieve video understanding. This enables advanced capabilities, including audio description, character identification, and multimodal high-level comprehension. Experimental results demonstrate the effectiveness of MM-VID in handling distinct video genres with various video lengths. Additionally, we showcase its potential when applied to interactive environments, such as video games and graphic user interfaces.