 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDicFace: Dirichlet-Constrained Variational Codebook Learning for Temporally Coherent Video Face Restoration
Jun 16, 2025



Video face restoration faces a critical challenge in maintaining temporal consistency while recovering fine facial details from degraded inputs. This paper presents a novel approach that extends Vector-Quantized Variational Autoencoders (VQ-VAEs), pretrained on static high-quality portraits, into a video restoration framework through variational latent space modeling. Our key innovation lies in reformulating discrete codebook representations as Dirichlet-distributed continuous variables, enabling probabilistic transitions between facial features across frames. A spatio-temporal Transformer architecture jointly models inter-frame dependencies and predicts latent distributions, while a Laplacian-constrained reconstruction loss combined with perceptual (LPIPS) regularization enhances both pixel accuracy and visual quality. Comprehensive evaluations on blind face restoration, video inpainting, and facial colorization tasks demonstrate state-of-the-art performance. This work establishes an effective paradigm for adapting intensive image priors, pretrained on high-quality images, to video restoration while addressing the critical challenge of flicker artifacts. The source code has been open-sourced and is available at https://github.com/fudan-generative-vision/DicFace.
Hallo4: High-Fidelity Dynamic Portrait Animation via Direct Preference Optimization and Temporal Motion Modulation
May 29, 2025Generating highly dynamic and photorealistic portrait animations driven by audio and skeletal motion remains challenging due to the need for precise lip synchronization, natural facial expressions, and high-fidelity body motion dynamics. We propose a human-preference-aligned diffusion framework that addresses these challenges through two key innovations. First, we introduce direct preference optimization tailored for human-centric animation, leveraging a curated dataset of human preferences to align generated outputs with perceptual metrics for portrait motion-video alignment and naturalness of expression. Second, the proposed temporal motion modulation resolves spatiotemporal resolution mismatches by reshaping motion conditions into dimensionally aligned latent features through temporal channel redistribution and proportional feature expansion, preserving the fidelity of high-frequency motion details in diffusion-based synthesis. The proposed mechanism is complementary to existing UNet and DiT-based portrait diffusion approaches, and experiments demonstrate obvious improvements in lip-audio synchronization, expression vividness, body motion coherence over baseline methods, alongside notable gains in human preference metrics. Our model and source code can be found at: https://github.com/xyz123xyz456/hallo4.
Hallo3: Highly Dynamic and Realistic Portrait Image Animation with Diffusion Transformer Networks
Dec 01, 2024Existing methodologies for animating portrait images face significant challenges, particularly in handling non-frontal perspectives, rendering dynamic objects around the portrait, and generating immersive, realistic backgrounds. In this paper, we introduce the first application of a pretrained transformer-based video generative model that demonstrates strong generalization capabilities and generates highly dynamic, realistic videos for portrait animation, effectively addressing these challenges. The adoption of a new video backbone model makes previous U-Net-based methods for identity maintenance, audio conditioning, and video extrapolation inapplicable. To address this limitation, we design an identity reference network consisting of a causal 3D VAE combined with a stacked series of transformer layers, ensuring consistent facial identity across video sequences. Additionally, we investigate various speech audio conditioning and motion frame mechanisms to enable the generation of continuous video driven by speech audio. Our method is validated through experiments on benchmark and newly proposed wild datasets, demonstrating substantial improvements over prior methods in generating realistic portraits characterized by diverse orientations within dynamic and immersive scenes. Further visualizations and the source code are available at: https://github.com/fudan-generative-vision/hallo3.
Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation
Oct 10, 2024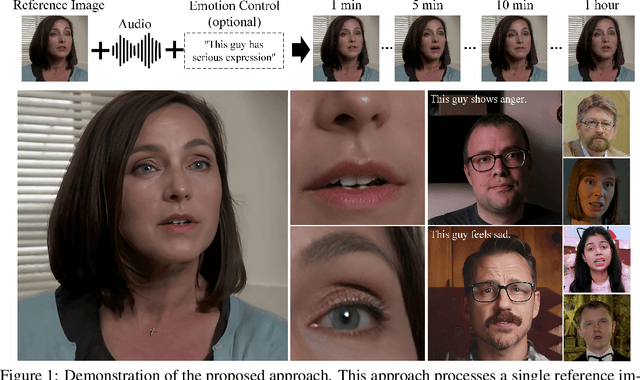


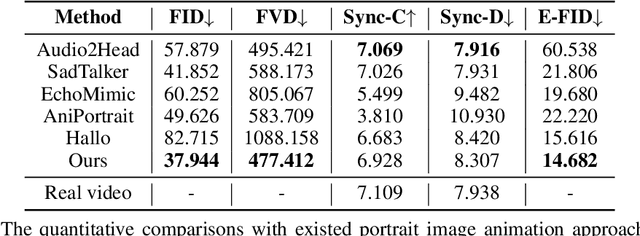
Recent advances in latent diffusion-based generative models for portrait image animation, such as Hallo, have achieved impressive results in short-duration video synthesis. In this paper, we present updates to Hallo, introducing several design enhancements to extend its capabilities. First, we extend the method to produce long-duration videos. To address substantial challenges such as appearance drift and temporal artifacts, we investigate augmentation strategies within the image space of conditional motion frames. Specifically, we introduce a patch-drop technique augmented with Gaussian noise to enhance visual consistency and temporal coherence over long duration. Second, we achieve 4K resolution portrait video generation. To accomplish this, we implement vector quantization of latent codes and apply temporal alignment techniques to maintain coherence across the temporal dimension. By integrating a high-quality decoder, we realize visual synthesis at 4K resolution. Third, we incorporate adjustable semantic textual labels for portrait expressions as conditional inputs. This extends beyond traditional audio cues to improve controllability and increase the diversity of the generated content. To the best of our knowledge, Hallo2, proposed in this paper, is the first method to achieve 4K resolution and generate hour-long, audio-driven portrait image animations enhanced with textual prompts. We have conducted extensive experiments to evaluate our method on publicly available datasets, including HDTF, CelebV, and our introduced "Wild" dataset. The experimental results demonstrate that our approach achieves state-of-the-art performance in long-duration portrait video animation, successfully generating rich and controllable content at 4K resolution for duration extending up to tens of minutes. Project page https://fudan-generative-vision.github.io/hallo2
Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation
Jun 16, 2024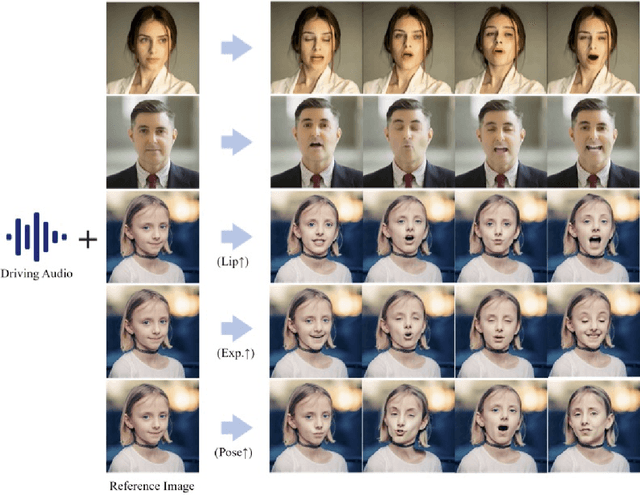
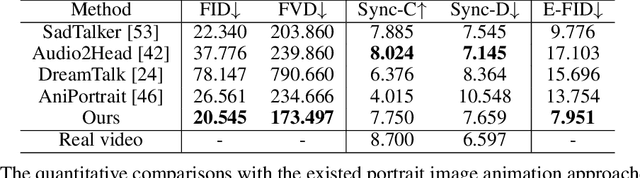
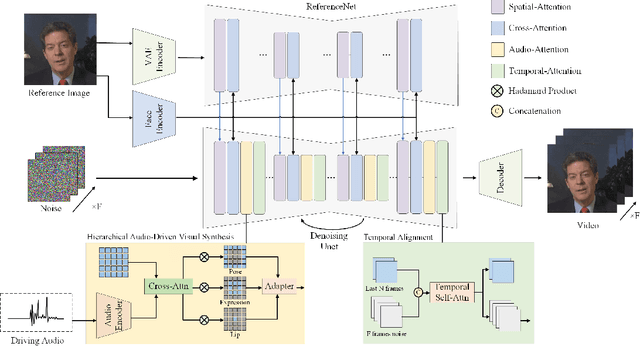
The field of portrait image animation, driven by speech audio input, has experienced significant advancements in the generation of realistic and dynamic portraits. This research delves into the complexities of synchronizing facial movements and creating visually appealing, temporally consistent animations within the framework of diffusion-based methodologies. Moving away from traditional paradigms that rely on parametric models for intermediate facial representations, our innovative approach embraces the end-to-end diffusion paradigm and introduces a hierarchical audio-driven visual synthesis module to enhance the precision of alignment between audio inputs and visual outputs, encompassing lip, expression, and pose motion. Our proposed network architecture seamlessly integrates diffusion-based generative models, a UNet-based denoiser, temporal alignment techniques, and a reference network. The proposed hierarchical audio-driven visual synthesis offers adaptive control over expression and pose diversity, enabling more effective personalization tailored to different identities. Through a comprehensive evaluation that incorporates both qualitative and quantitative analyses, our approach demonstrates obvious enhancements in image and video quality, lip synchronization precision, and motion diversity. Further visualization and access to the source code can be found at: https://fudan-generative-vision.github.io/hallo.
On projection methods for functional time series forecasting
May 10, 2021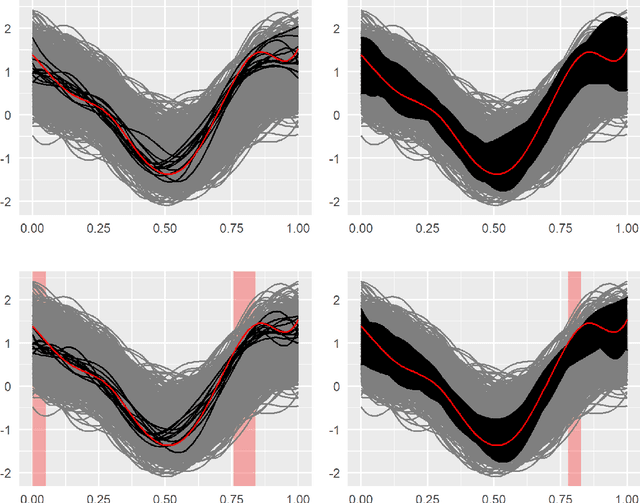
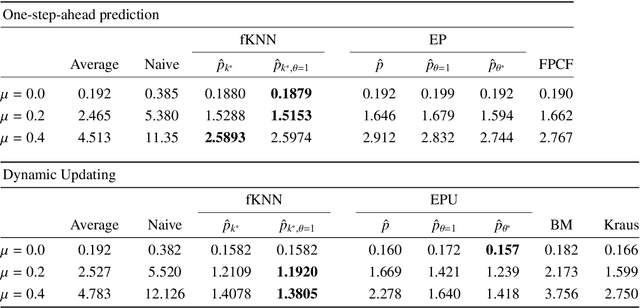

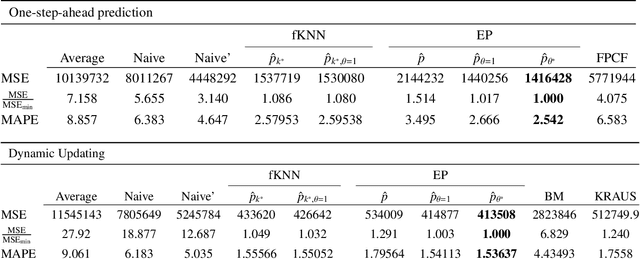
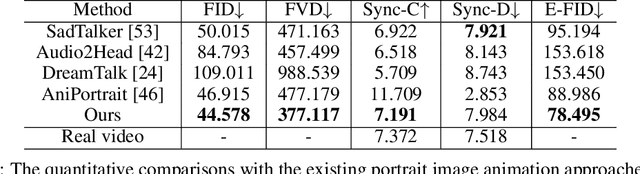
Two nonparametric methods are presented for forecasting functional time series (FTS). The FTS we observe is a curve at a discrete-time point. We address both one-step-ahead forecasting and dynamic updating. Dynamic updating is a forward prediction of the unobserved segment of the most recent curve. Among the two proposed methods, the first one is a straightforward adaptation to FTS of the $k$-nearest neighbors methods for univariate time series forecasting. The second one is based on a selection of curves, termed \emph{the curve envelope}, that aims to be representative in shape and magnitude of the most recent functional observation, either a whole curve or the observed part of a partially observed curve. In a similar fashion to $k$-nearest neighbors and other projection methods successfully used for time series forecasting, we ``project'' the $k$-nearest neighbors and the curves in the envelope for forecasting. In doing so, we keep track of the next period evolution of the curves. The methods are applied to simulated data, daily electricity demand, and NOx emissions and provide competitive results with and often superior to several benchmark predictions. The approach offers a model-free alternative to statistical methods based on FTS modeling to study the cyclic or seasonal behavior of many FTS.