 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallo4: High-Fidelity Dynamic Portrait Animation via Direct Preference Optimization and Temporal Motion Modulation
May 29, 2025Generating highly dynamic and photorealistic portrait animations driven by audio and skeletal motion remains challenging due to the need for precise lip synchronization, natural facial expressions, and high-fidelity body motion dynamics. We propose a human-preference-aligned diffusion framework that addresses these challenges through two key innovations. First, we introduce direct preference optimization tailored for human-centric animation, leveraging a curated dataset of human preferences to align generated outputs with perceptual metrics for portrait motion-video alignment and naturalness of expression. Second, the proposed temporal motion modulation resolves spatiotemporal resolution mismatches by reshaping motion conditions into dimensionally aligned latent features through temporal channel redistribution and proportional feature expansion, preserving the fidelity of high-frequency motion details in diffusion-based synthesis. The proposed mechanism is complementary to existing UNet and DiT-based portrait diffusion approaches, and experiments demonstrate obvious improvements in lip-audio synchronization, expression vividness, body motion coherence over baseline methods, alongside notable gains in human preference metrics. Our model and source code can be found at: https://github.com/xyz123xyz456/hallo4.
Tumor Detection, Segmentation and Classification Challenge on Automated 3D Breast Ultrasound: The TDSC-ABUS Challenge
Jan 26, 2025



Breast cancer is one of the most common causes of death among women worldwide. Early detection helps in reducing the number of deaths. Automated 3D Breast Ultrasound (ABUS) is a newer approach for breast screening, which has many advantages over handheld mammography such as safety, speed, and higher detection rate of breast cancer. Tumor detection, segmentation, and classification are key components in the analysis of medical images, especially challenging in the context of 3D ABUS due to the significant variability in tumor size and shape, unclear tumor boundaries, and a low signal-to-noise ratio. The lack of publicly accessible, well-labeled ABUS datasets further hinders the advancement of systems for breast tumor analysis. Addressing this gap, we have organized the inaugural Tumor Detection, Segmentation, and Classification Challenge on Automated 3D Breast Ultrasound 2023 (TDSC-ABUS2023). This initiative aims to spearhead research in this field and create a definitive benchmark for tasks associated with 3D ABUS image analysis. In this paper, we summarize the top-performing algorithms from the challenge and provide critical analysis for ABUS image examination. We offer the TDSC-ABUS challenge as an open-access platform at https://tdsc-abus2023.grand-challenge.org/ to benchmark and inspire future developments in algorithmic research.
OpenHumanVid: A Large-Scale High-Quality Dataset for Enhancing Human-Centric Video Generation
Dec 03, 2024



Recent advancements in visual generation technologies have markedly increased the scale and availability of video datasets, which are crucial for training effective video generation models. However, a significant lack of high-quality, human-centric video datasets presents a challenge to progress in this field. To bridge this gap, we introduce OpenHumanVid, a large-scale and high-quality human-centric video dataset characterized by precise and detailed captions that encompass both human appearance and motion states, along with supplementary human motion conditions, including skeleton sequences and speech audio. To validate the efficacy of this dataset and the associated training strategies, we propose an extension of existing classical diffusion transformer architectures and conduct further pretraining of our models on the proposed dataset. Our findings yield two critical insights: First, the incorporation of a large-scale, high-quality dataset substantially enhances evaluation metrics for generated human videos while preserving performance in general video generation tasks. Second, the effective alignment of text with human appearance, human motion, and facial motion is essential for producing high-quality video outputs. Based on these insights and corresponding methodologies, the straightforward extended network trained on the proposed dataset demonstrates an obvious improvement in the generation of human-centric videos. Project page https://fudan-generative-vision.github.io/OpenHumanVid
Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation
Jun 16, 2024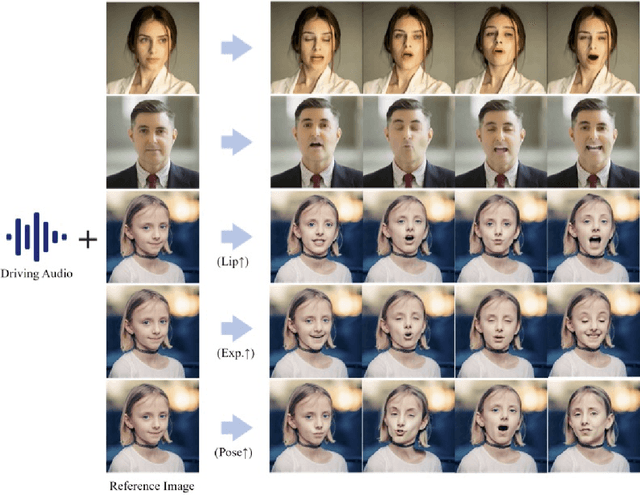
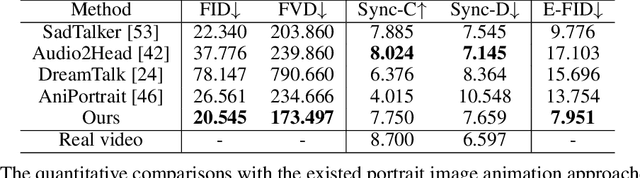
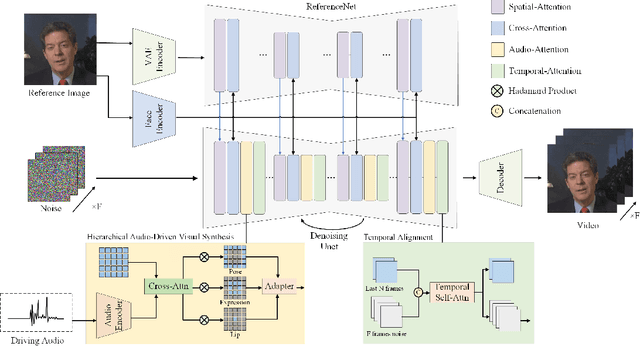
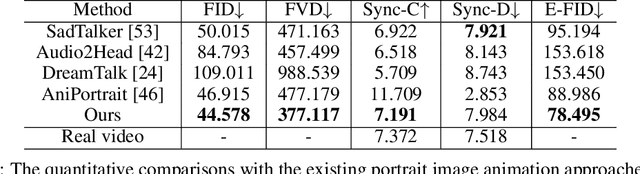
The field of portrait image animation, driven by speech audio input, has experienced significant advancements in the generation of realistic and dynamic portraits. This research delves into the complexities of synchronizing facial movements and creating visually appealing, temporally consistent animations within the framework of diffusion-based methodologies. Moving away from traditional paradigms that rely on parametric models for intermediate facial representations, our innovative approach embraces the end-to-end diffusion paradigm and introduces a hierarchical audio-driven visual synthesis module to enhance the precision of alignment between audio inputs and visual outputs, encompassing lip, expression, and pose motion. Our proposed network architecture seamlessly integrates diffusion-based generative models, a UNet-based denoiser, temporal alignment techniques, and a reference network. The proposed hierarchical audio-driven visual synthesis offers adaptive control over expression and pose diversity, enabling more effective personalization tailored to different identities. Through a comprehensive evaluation that incorporates both qualitative and quantitative analyses, our approach demonstrates obvious enhancements in image and video quality, lip synchronization precision, and motion diversity. Further visualization and access to the source code can be found at: https://fudan-generative-vision.github.io/hallo.
The state-of-the-art 3D anisotropic intracranial hemorrhage segmentation on non-contrast head CT: The INSTANCE challenge
Jan 12, 2023Automatic intracranial hemorrhage segmentation in 3D non-contrast head CT (NCCT) scans is significant in clinical practice. Existing hemorrhage segmentation methods usually ignores the anisotropic nature of the NCCT, and are evaluated on different in-house datasets with distinct metrics, making it highly challenging to improve segmentation performance and perform objective comparisons among different methods. The INSTANCE 2022 was a grand challenge held in conjunction with the 2022 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). It is intended to resolve the above-mentioned problems and promote the development of both intracranial hemorrhage segmentation and anisotropic data processing. The INSTANCE released a training set of 100 cases with ground-truth and a validation set with 30 cases without ground-truth labels that were available to the participants. A held-out testing set with 70 cases is utilized for the final evaluation and ranking. The methods from different participants are ranked based on four metrics, including Dice Similarity Coefficient (DSC), Hausdorff Distance (HD), Relative Volume Difference (RVD) and Normalized Surface Dice (NSD). A total of 13 teams submitted distinct solutions to resolve the challenges, making several baseline models, pre-processing strategies and anisotropic data processing techniques available to future researchers. The winner method achieved an average DSC of 0.6925, demonstrating a significant growth over our proposed baseline method. To the best of our knowledge, the proposed INSTANCE challenge releases the first intracranial hemorrhage segmentation benchmark, and is also the first challenge that intended to resolve the anisotropic problem in 3D medical image segmentation, which provides new alternatives in these research fields.