 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Implicit Bias in Generative Spaces for Accelerating Protein Dynamics Emulation
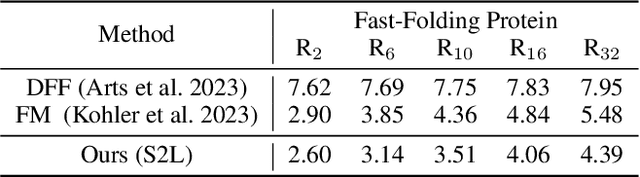
Jun 01, 2026Generative emulators of protein dynamics produce plausible trajectories at a fraction of the cost of molecular dynamics, but they inherit their training distribution and tend to revisit known states rather than reach rare ones under long-horizon extrapolation. Inspired by classical enhanced sampling, we introduce an implicit, history-dependent bias in the generative space of a pretrained emulator. Specifically, a history-aware score estimator augments the frozen emulator with a distance-weighted bias that steers reverse-time sampling away from previously generated structures, regularized by an environment-support term. To preserve structural validity at long horizons, a score-based refinement step re-projects drifted samples onto the data manifold using the frozen emulator. Our experiments demonstrate that the method (i) raises diversity by $35\%$ on DynamicPDB-80; (ii) on $12$ zero-shot Fast-Folding proteins, the learned bias alone reaches the unbiased emulator's coverage up to ${\sim}15\times$ faster, and pairing it with refinement reaches the coverage up to ${\sim}37\times$ faster while covering ${\sim}3\times$ as many low-energy states. Code will be released soon.
Prompt Reinjection: Alleviating Prompt Forgetting in Multimodal Diffusion Transformers
Feb 06, 2026Multimodal Diffusion Transformers (MMDiTs) for text-to-image generation maintain separate text and image branches, with bidirectional information flow between text tokens and visual latents throughout denoising. In this setting, we observe a prompt forgetting phenomenon: the semantics of the prompt representation in the text branch is progressively forgotten as depth increases. We further verify this effect on three representative MMDiTs--SD3, SD3.5, and FLUX.1 by probing linguistic attributes of the representations over the layers in the text branch. Motivated by these findings, we introduce a training-free approach, prompt reinjection, which reinjects prompt representations from early layers into later layers to alleviate this forgetting. Experiments on GenEval, DPG, and T2I-CompBench++ show consistent gains in instruction-following capability, along with improvements on metrics capturing preference, aesthetics, and overall text--image generation quality.
MixFlow Training: Alleviating Exposure Bias with Slowed Interpolation Mixture
Dec 22, 2025This paper studies the training-testing discrepancy (a.k.a. exposure bias) problem for improving the diffusion models. During training, the input of a prediction network at one training timestep is the corresponding ground-truth noisy data that is an interpolation of the noise and the data, and during testing, the input is the generated noisy data. We present a novel training approach, named MixFlow, for improving the performance. Our approach is motivated by the Slow Flow phenomenon: the ground-truth interpolation that is the nearest to the generated noisy data at a given sampling timestep is observed to correspond to a higher-noise timestep (termed slowed timestep), i.e., the corresponding ground-truth timestep is slower than the sampling timestep. MixFlow leverages the interpolations at the slowed timesteps, named slowed interpolation mixture, for post-training the prediction network for each training timestep. Experiments over class-conditional image generation (including SiT, REPA, and RAE) and text-to-image generation validate the effectiveness of our approach. Our approach MixFlow over the RAE models achieve strong generation results on ImageNet: 1.43 FID (without guidance) and 1.10 (with guidance) at 256 x 256, and 1.55 FID (without guidance) and 1.10 (with guidance) at 512 x 512.
OpenHumanVid: A Large-Scale High-Quality Dataset for Enhancing Human-Centric Video Generation
Dec 03, 2024



Recent advancements in visual generation technologies have markedly increased the scale and availability of video datasets, which are crucial for training effective video generation models. However, a significant lack of high-quality, human-centric video datasets presents a challenge to progress in this field. To bridge this gap, we introduce OpenHumanVid, a large-scale and high-quality human-centric video dataset characterized by precise and detailed captions that encompass both human appearance and motion states, along with supplementary human motion conditions, including skeleton sequences and speech audio. To validate the efficacy of this dataset and the associated training strategies, we propose an extension of existing classical diffusion transformer architectures and conduct further pretraining of our models on the proposed dataset. Our findings yield two critical insights: First, the incorporation of a large-scale, high-quality dataset substantially enhances evaluation metrics for generated human videos while preserving performance in general video generation tasks. Second, the effective alignment of text with human appearance, human motion, and facial motion is essential for producing high-quality video outputs. Based on these insights and corresponding methodologies, the straightforward extended network trained on the proposed dataset demonstrates an obvious improvement in the generation of human-centric videos. Project page https://fudan-generative-vision.github.io/OpenHumanVid
Hallo3: Highly Dynamic and Realistic Portrait Image Animation with Diffusion Transformer Networks
Dec 01, 2024Existing methodologies for animating portrait images face significant challenges, particularly in handling non-frontal perspectives, rendering dynamic objects around the portrait, and generating immersive, realistic backgrounds. In this paper, we introduce the first application of a pretrained transformer-based video generative model that demonstrates strong generalization capabilities and generates highly dynamic, realistic videos for portrait animation, effectively addressing these challenges. The adoption of a new video backbone model makes previous U-Net-based methods for identity maintenance, audio conditioning, and video extrapolation inapplicable. To address this limitation, we design an identity reference network consisting of a causal 3D VAE combined with a stacked series of transformer layers, ensuring consistent facial identity across video sequences. Additionally, we investigate various speech audio conditioning and motion frame mechanisms to enable the generation of continuous video driven by speech audio. Our method is validated through experiments on benchmark and newly proposed wild datasets, demonstrating substantial improvements over prior methods in generating realistic portraits characterized by diverse orientations within dynamic and immersive scenes. Further visualizations and the source code are available at: https://github.com/fudan-generative-vision/hallo3.
Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation
Oct 10, 2024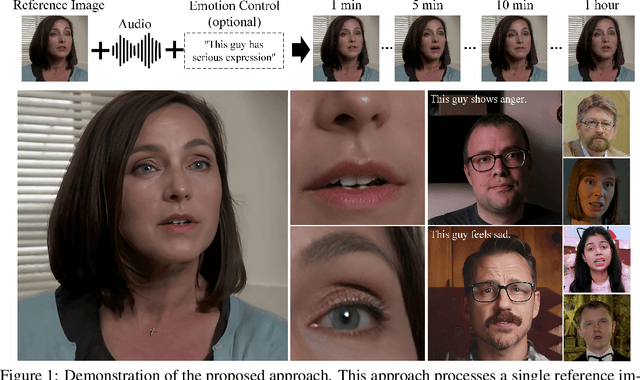


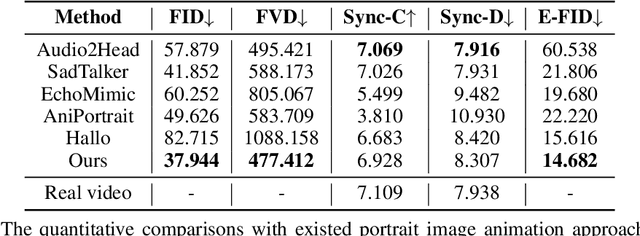
Recent advances in latent diffusion-based generative models for portrait image animation, such as Hallo, have achieved impressive results in short-duration video synthesis. In this paper, we present updates to Hallo, introducing several design enhancements to extend its capabilities. First, we extend the method to produce long-duration videos. To address substantial challenges such as appearance drift and temporal artifacts, we investigate augmentation strategies within the image space of conditional motion frames. Specifically, we introduce a patch-drop technique augmented with Gaussian noise to enhance visual consistency and temporal coherence over long duration. Second, we achieve 4K resolution portrait video generation. To accomplish this, we implement vector quantization of latent codes and apply temporal alignment techniques to maintain coherence across the temporal dimension. By integrating a high-quality decoder, we realize visual synthesis at 4K resolution. Third, we incorporate adjustable semantic textual labels for portrait expressions as conditional inputs. This extends beyond traditional audio cues to improve controllability and increase the diversity of the generated content. To the best of our knowledge, Hallo2, proposed in this paper, is the first method to achieve 4K resolution and generate hour-long, audio-driven portrait image animations enhanced with textual prompts. We have conducted extensive experiments to evaluate our method on publicly available datasets, including HDTF, CelebV, and our introduced "Wild" dataset. The experimental results demonstrate that our approach achieves state-of-the-art performance in long-duration portrait video animation, successfully generating rich and controllable content at 4K resolution for duration extending up to tens of minutes. Project page https://fudan-generative-vision.github.io/hallo2
4D Diffusion for Dynamic Protein Structure Prediction with Reference Guided Motion Alignment
Aug 22, 2024
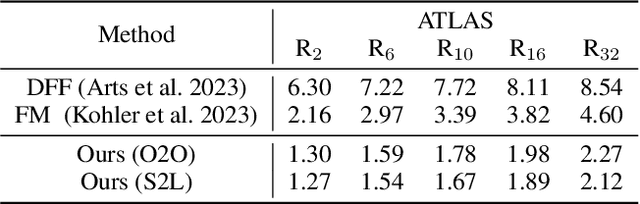
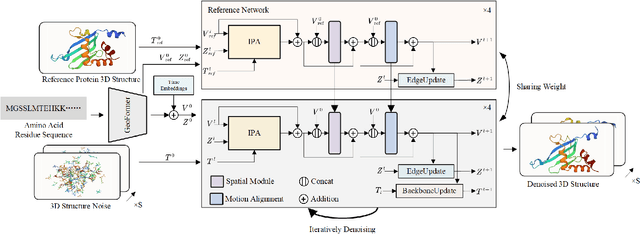
Protein structure prediction is pivotal for understanding the structure-function relationship of proteins, advancing biological research, and facilitating pharmaceutical development and experimental design. While deep learning methods and the expanded availability of experimental 3D protein structures have accelerated structure prediction, the dynamic nature of protein structures has received limited attention. This study introduces an innovative 4D diffusion model incorporating molecular dynamics (MD) simulation data to learn dynamic protein structures. Our approach is distinguished by the following components: (1) a unified diffusion model capable of generating dynamic protein structures, including both the backbone and side chains, utilizing atomic grouping and side-chain dihedral angle predictions; (2) a reference network that enhances structural consistency by integrating the latent embeddings of the initial 3D protein structures; and (3) a motion alignment module aimed at improving temporal structural coherence across multiple time steps. To our knowledge, this is the first diffusion-based model aimed at predicting protein trajectories across multiple time steps simultaneously. Validation on benchmark datasets demonstrates that our model exhibits high accuracy in predicting dynamic 3D structures of proteins containing up to 256 amino acids over 32 time steps, effectively capturing both local flexibility in stable states and significant conformational changes.
Dynamic PDB: A New Dataset and a SE(3) Model Extension by Integrating Dynamic Behaviors and Physical Properties in Protein Structures
Aug 22, 2024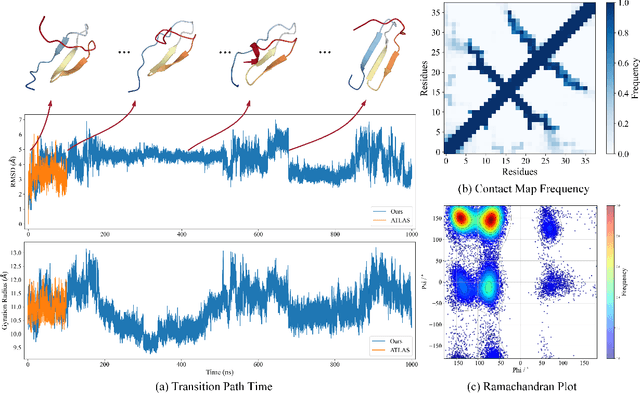
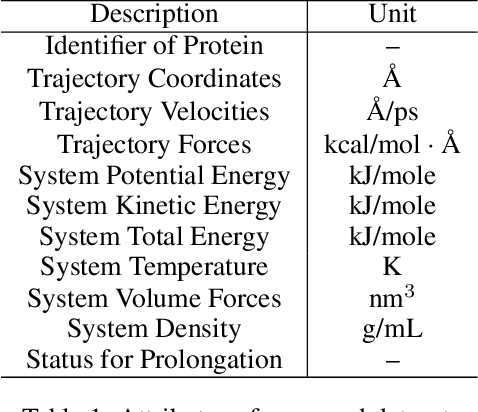

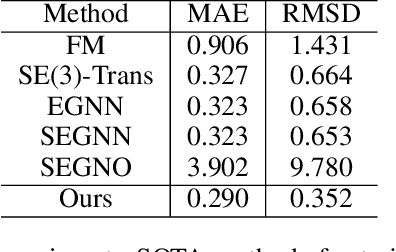
Despite significant progress in static protein structure collection and prediction, the dynamic behavior of proteins, one of their most vital characteristics, has been largely overlooked in prior research. This oversight can be attributed to the limited availability, diversity, and heterogeneity of dynamic protein datasets. To address this gap, we propose to enhance existing prestigious static 3D protein structural databases, such as the Protein Data Bank (PDB), by integrating dynamic data and additional physical properties. Specifically, we introduce a large-scale dataset, Dynamic PDB, encompassing approximately 12.6K proteins, each subjected to all-atom molecular dynamics (MD) simulations lasting 1 microsecond to capture conformational changes. Furthermore, we provide a comprehensive suite of physical properties, including atomic velocities and forces, potential and kinetic energies of proteins, and the temperature of the simulation environment, recorded at 1 picosecond intervals throughout the simulations. For benchmarking purposes, we evaluate state-of-the-art methods on the proposed dataset for the task of trajectory prediction. To demonstrate the value of integrating richer physical properties in the study of protein dynamics and related model design, we base our approach on the SE(3) diffusion model and incorporate these physical properties into the trajectory prediction process. Preliminary results indicate that this straightforward extension of the SE(3) model yields improved accuracy, as measured by MAE and RMSD, when the proposed physical properties are taken into consideration.
LPN: Language-guided Prototypical Network for few-shot classification
Jul 04, 2023Few-shot classification aims to adapt to new tasks with limited labeled examples. To fully use the accessible data, recent methods explore suitable measures for the similarity between the query and support images and better high-dimensional features with meta-training and pre-training strategies. However, the potential of multi-modality information has barely been explored, which may bring promising improvement for few-shot classification. In this paper, we propose a Language-guided Prototypical Network (LPN) for few-shot classification, which leverages the complementarity of vision and language modalities via two parallel branches. Concretely, to introduce language modality with limited samples in the visual task, we leverage a pre-trained text encoder to extract class-level text features directly from class names while processing images with a conventional image encoder. Then, a language-guided decoder is introduced to obtain text features corresponding to each image by aligning class-level features with visual features. In addition, to take advantage of class-level features and prototypes, we build a refined prototypical head that generates robust prototypes in the text branch for follow-up measurement. Finally, we aggregate the visual and text logits to calibrate the deviation of a single modality. Extensive experiments demonstrate the competitiveness of LPN against state-of-the-art methods on benchmark datasets.