 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH2VLR: Heterogeneous Hypergraph Vision-Language Reasoning for Few-Shot Anomaly Detection
Apr 16, 2026As a classic vision task, anomaly detection has been widely applied in industrial inspection and medical imaging. In this task, data scarcity is often a frequently-faced issue. To solve it, the few-shot anomaly detection (FSAD) scheme is attracting increasing attention. In recent years, beyond traditional visual paradigm, Vision-Language Model (VLM) has been extensively explored to boost this field. However, in currently-existing VLM-based FSAD schemes, almost all perform anomaly inference only by pairwise feature matching, ignoring structural dependencies and global consistency. To further redound to FSAD via VLM, we propose a Heterogeneous Hypergraph Vision-Language Reasoning (H2VLR) framework. It reformulates the FSAD as a high-order inference problem of visual-semantic relations, by jointly modeling visual regions and semantic concepts in a unified hypergraph. Experimental comparisons verify the effectiveness and advantages of H2VLR. It could often achieve state-of-the-art (SOTA) performance on representative industrial and medical benchmarks. Our code will be released upon acceptance.
SocialMirror: Reconstructing 3D Human Interaction Behaviors from Monocular Videos with Semantic and Geometric Guidance
Apr 15, 2026Accurately reconstructing human behavior in close-interaction scenarios is crucial for enabling realistic virtual interactions in augmented reality, precise motion analysis in sports, and natural collaborative behavior in human-robot tasks. Reliable reconstruction in these contexts significantly enhances the realism and effectiveness of AI-driven interactive applications. However, human reconstruction from monocular videos in close-interaction scenarios remains challenging due to severe mutual occlusions, leading local motion ambiguity, disrupted temporal continuity and spatial relationship error. In this paper, we propose SocialMirror, a diffusion-based framework that integrates semantic and geometric cues to effectively address these issues. Specifically, we first leverage high-level interaction descriptions generated by a vision-language model to guide a semantic-guided motion infiller, hallucinating occluded bodies and resolving local pose ambiguities. Next, we propose a sequence-level temporal refiner that enforces smooth, jitter-free motions, while incorporating geometric constraints during sampling to ensure plausible contact and spatial relationships. Evaluations on multiple interaction benchmarks show that SocialMirror achieves state-of-the-art performance in reconstructing interactive human meshes, demonstrating strong generalization across unseen datasets and in-the-wild scenarios. The code will be released upon publication.
CWRNN-INVR: A Coupled WarpRNN based Implicit Neural Video Representation
Apr 08, 2026Implicit Neural Video Representation (INVR) has emerged as a novel approach for video representation and compression, using learnable grids and neural networks. Existing methods focus on developing new grid structures efficient for latent representation and neural network architectures with large representation capability, lacking the study on their roles in video representation. In this paper, the difference between INVR based on neural network and INVR based on grid is first investigated from the perspective of video information composition to specify their own advantages, i.e., neural network for general structure while grid for specific detail. Accordingly, an INVR based on mixed neural network and residual grid framework is proposed, where the neural network is used to represent the regular and structured information and the residual grid is used to represent the remaining irregular information in a video. A Coupled WarpRNN-based multi-scale motion representation and compensation module is specifically designed to explicitly represent the regular and structured information, thus terming our method as CWRNN-INVR. For the irregular information, a mixed residual grid is learned where the irregular appearance and motion information are represented together. The mixed residual grid can be combined with the coupled WarpRNN in a way that allows for network reuse. Experiments show that our method achieves the best reconstruction results compared with the existing methods, with an average PSNR of 33.73 dB on the UVG dataset under the 3M model and outperforms existing INVR methods in other downstream tasks. The code can be found at https://github.com/yiyang-sdu/CWRNN-INVR.git}{https://github.com/yiyang-sdu/CWRNN-INVR.git.
A Noise Constrained Diffusion (NC-Diffusion) Framework for High Fidelity Image Compression
Apr 08, 2026With the great success of diffusion models in image generation, diffusion-based image compression is attracting increasing interests. However, due to the random noise introduced in the diffusion learning, they usually produce reconstructions with deviation from the original images, leading to suboptimal compression results. To address this problem, in this paper, we propose a Noise Constrained Diffusion (NC-Diffusion) framework for high fidelity image compression. Unlike existing diffusion-based compression methods that add random Gaussian noise and direct the noise into the image space, the proposed NC-Diffusion formulates the quantization noise originally added in the learned image compression as the noise in the forward process of diffusion. Then a noise constrained diffusion process is constructed from the ground-truth image to the initial compression result generated with quantization noise. The NC-Diffusion overcomes the problem of noise mismatch between compression and diffusion, significantly improving the inference efficiency. In addition, an adaptive frequency-domain filtering module is developed to enhance the skip connections in the U-Net based diffusion architecture, in order to enhance high-frequency details. Moreover, a zero-shot sample-guided enhancement method is designed to further improve the fidelity of the image. Experiments on multiple benchmark datasets demonstrate that our method can achieve the best performance compared with existing methods.
ToLL: Topological Layout Learning with Structural Multi-view Augmentation for 3D Scene Graph Pretraining
Mar 30, 20263D Scene Graph (3DSG) generation plays a pivotal role in spatial understanding and semantic-affordance perception. However, its generalizability is often constrained by data scarcity. Current solutions primarily focus on cross-modal assisted representation learning and object-centric generation pre-training. The former relies heavily on predicate annotations, while the latter's predicate learning may be bypassed due to strong object priors. Consequently, they could not often provide a label-free and robust self-supervised proxy task for 3DSG fine-tuning. To bridge this gap, we propose a Topological Layout Learning (ToLL) for 3DSG pretraining framework. In detail, we design an Anchor-Conditioned Topological Geometry Reasoning, with a GNN to recover the global layout of zero-centered subgraphs by the spatial priors from sparse anchors. This process is strictly modulated by predicate features, thereby enforcing the predicate relation learning. Furthermore, we construct a Structural Multi-view Augmentation to avoid semantic corruption, and enhancing representations via self-distillation. The extensive experiments on 3DSSG dataset demonstrate that our ToLL could improve representation quality, outperforming state-of-the-art baselines.
Weakly-supervised Contrastive Learning with Quantity Prompts for Moving Infrared Small Target Detection
Jul 03, 2025Different from general object detection, moving infrared small target detection faces huge challenges due to tiny target size and weak background contrast.Currently, most existing methods are fully-supervised, heavily relying on a large number of manual target-wise annotations. However, manually annotating video sequences is often expensive and time-consuming, especially for low-quality infrared frame images. Inspired by general object detection, non-fully supervised strategies ($e.g.$, weakly supervised) are believed to be potential in reducing annotation requirements. To break through traditional fully-supervised frameworks, as the first exploration work, this paper proposes a new weakly-supervised contrastive learning (WeCoL) scheme, only requires simple target quantity prompts during model training.Specifically, in our scheme, based on the pretrained segment anything model (SAM), a potential target mining strategy is designed to integrate target activation maps and multi-frame energy accumulation.Besides, contrastive learning is adopted to further improve the reliability of pseudo-labels, by calculating the similarity between positive and negative samples in feature subspace.Moreover, we propose a long-short term motion-aware learning scheme to simultaneously model the local motion patterns and global motion trajectory of small targets.The extensive experiments on two public datasets (DAUB and ITSDT-15K) verify that our weakly-supervised scheme could often outperform early fully-supervised methods. Even, its performance could reach over 90\% of state-of-the-art (SOTA) fully-supervised ones.
AGENT-X: Adaptive Guideline-based Expert Network for Threshold-free AI-generated teXt detection
May 21, 2025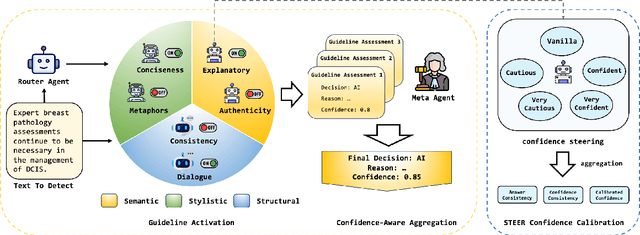
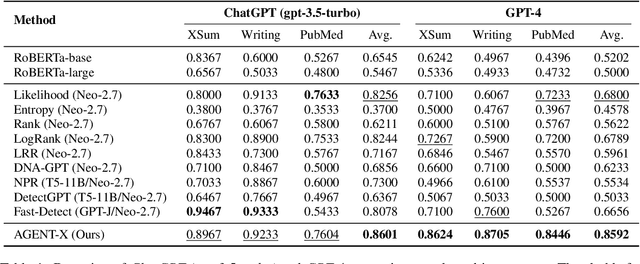
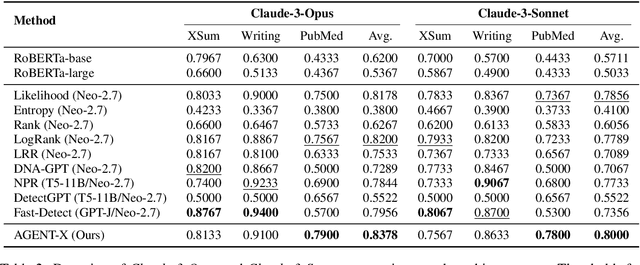
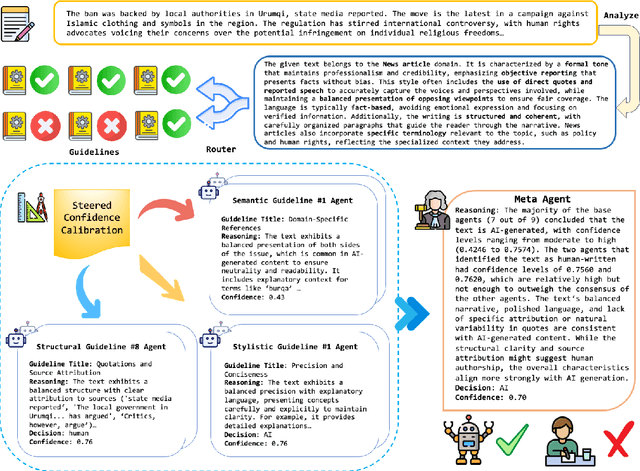
Existing AI-generated text detection methods heavily depend on large annotated datasets and external threshold tuning, restricting interpretability, adaptability, and zero-shot effectiveness. To address these limitations, we propose AGENT-X, a zero-shot multi-agent framework informed by classical rhetoric and systemic functional linguistics. Specifically, we organize detection guidelines into semantic, stylistic, and structural dimensions, each independently evaluated by specialized linguistic agents that provide explicit reasoning and robust calibrated confidence via semantic steering. A meta agent integrates these assessments through confidence-aware aggregation, enabling threshold-free, interpretable classification. Additionally, an adaptive Mixture-of-Agent router dynamically selects guidelines based on inferred textual characteristics. Experiments on diverse datasets demonstrate that AGENT-X substantially surpasses state-of-the-art supervised and zero-shot approaches in accuracy, interpretability, and generalization.
High Dynamic Range Novel View Synthesis with Single Exposure
May 02, 2025
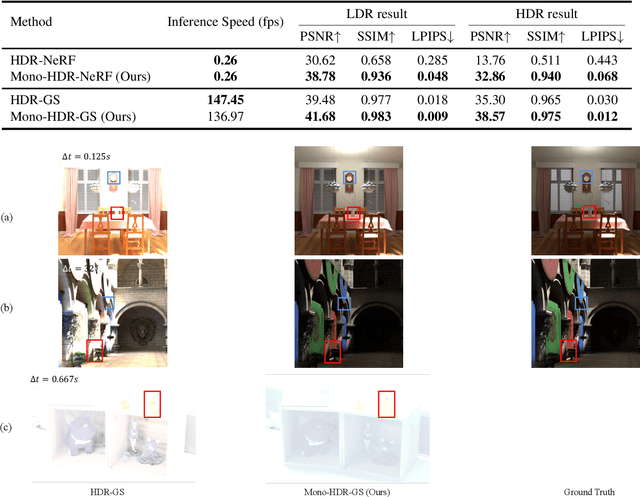
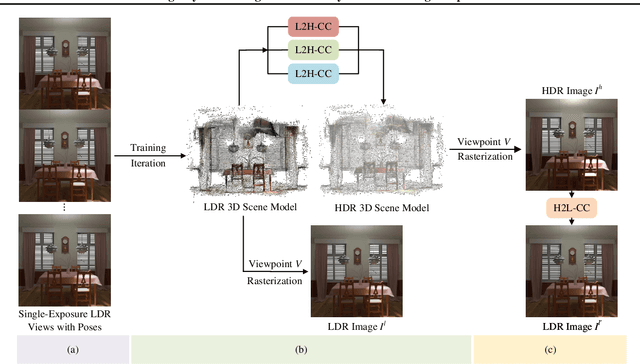
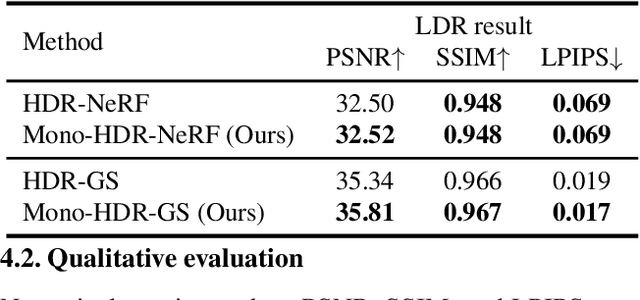
High Dynamic Range Novel View Synthesis (HDR-NVS) aims to establish a 3D scene HDR model from Low Dynamic Range (LDR) imagery. Typically, multiple-exposure LDR images are employed to capture a wider range of brightness levels in a scene, as a single LDR image cannot represent both the brightest and darkest regions simultaneously. While effective, this multiple-exposure HDR-NVS approach has significant limitations, including susceptibility to motion artifacts (e.g., ghosting and blurring), high capture and storage costs. To overcome these challenges, we introduce, for the first time, the single-exposure HDR-NVS problem, where only single exposure LDR images are available during training. We further introduce a novel approach, Mono-HDR-3D, featuring two dedicated modules formulated by the LDR image formation principles, one for converting LDR colors to HDR counterparts, and the other for transforming HDR images to LDR format so that unsupervised learning is enabled in a closed loop. Designed as a meta-algorithm, our approach can be seamlessly integrated with existing NVS models. Extensive experiments show that Mono-HDR-3D significantly outperforms previous methods. Source code will be released.
Bayesian Test-Time Adaptation for Vision-Language Models
Mar 12, 2025Test-time adaptation with pre-trained vision-language models, such as CLIP, aims to adapt the model to new, potentially out-of-distribution test data. Existing methods calculate the similarity between visual embedding and learnable class embeddings, which are initialized by text embeddings, for zero-shot image classification. In this work, we first analyze this process based on Bayes theorem, and observe that the core factors influencing the final prediction are the likelihood and the prior. However, existing methods essentially focus on adapting class embeddings to adapt likelihood, but they often ignore the importance of prior. To address this gap, we propose a novel approach, \textbf{B}ayesian \textbf{C}lass \textbf{A}daptation (BCA), which in addition to continuously updating class embeddings to adapt likelihood, also uses the posterior of incoming samples to continuously update the prior for each class embedding. This dual updating mechanism allows the model to better adapt to distribution shifts and achieve higher prediction accuracy. Our method not only surpasses existing approaches in terms of performance metrics but also maintains superior inference rates and memory usage, making it highly efficient and practical for real-world applications.
Generative Data Mining with Longtail-Guided Diffusion
Feb 04, 2025
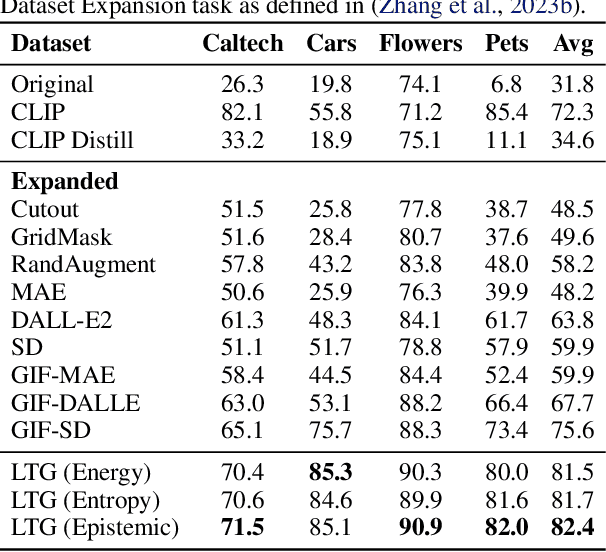
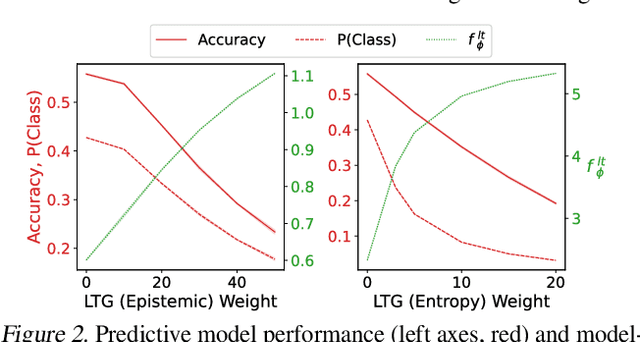
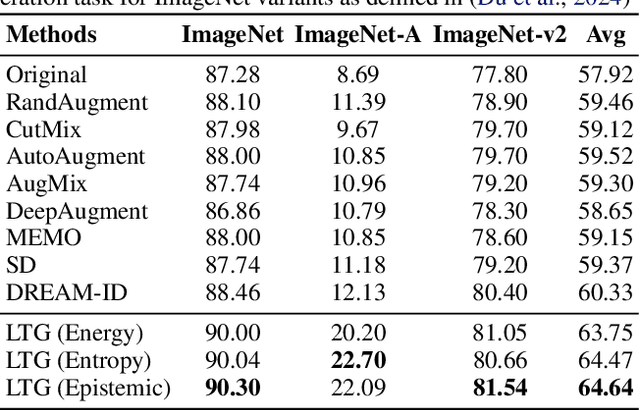
It is difficult to anticipate the myriad challenges that a predictive model will encounter once deployed. Common practice entails a reactive, cyclical approach: model deployment, data mining, and retraining. We instead develop a proactive longtail discovery process by imagining additional data during training. In particular, we develop general model-based longtail signals, including a differentiable, single forward pass formulation of epistemic uncertainty that does not impact model parameters or predictive performance but can flag rare or hard inputs. We leverage these signals as guidance to generate additional training data from a latent diffusion model in a process we call Longtail Guidance (LTG). Crucially, we can perform LTG without retraining the diffusion model or the predictive model, and we do not need to expose the predictive model to intermediate diffusion states. Data generated by LTG exhibit semantically meaningful variation, yield significant generalization improvements on image classification benchmarks, and can be analyzed to proactively discover, explain, and address conceptual gaps in a predictive model.