 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeCap: Hybrid Calibration-Free Motion Capture in Open Environments
Nov 07, 2024
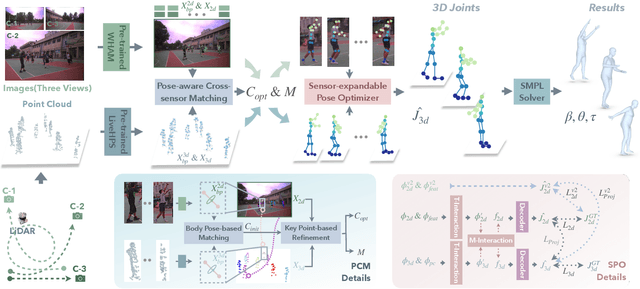
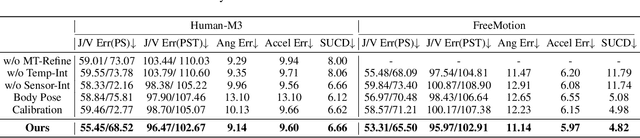

We propose a novel hybrid calibration-free method FreeCap to accurately capture global multi-person motions in open environments. Our system combines a single LiDAR with expandable moving cameras, allowing for flexible and precise motion estimation in a unified world coordinate. In particular, We introduce a local-to-global pose-aware cross-sensor human-matching module that predicts the alignment among each sensor, even in the absence of calibration. Additionally, our coarse-to-fine sensor-expandable pose optimizer further optimizes the 3D human key points and the alignments, it is also capable of incorporating additional cameras to enhance accuracy. Extensive experiments on Human-M3 and FreeMotion datasets demonstrate that our method significantly outperforms state-of-the-art single-modal methods, offering an expandable and efficient solution for multi-person motion capture across various applications.
HOI-M3:Capture Multiple Humans and Objects Interaction within Contextual Environment
Apr 02, 2024



Humans naturally interact with both others and the surrounding multiple objects, engaging in various social activities. However, recent advances in modeling human-object interactions mostly focus on perceiving isolated individuals and objects, due to fundamental data scarcity. In this paper, we introduce HOI-M3, a novel large-scale dataset for modeling the interactions of Multiple huMans and Multiple objects. Notably, it provides accurate 3D tracking for both humans and objects from dense RGB and object-mounted IMU inputs, covering 199 sequences and 181M frames of diverse humans and objects under rich activities. With the unique HOI-M3 dataset, we introduce two novel data-driven tasks with companion strong baselines: monocular capture and unstructured generation of multiple human-object interactions. Extensive experiments demonstrate that our dataset is challenging and worthy of further research about multiple human-object interactions and behavior analysis. Our HOI-M3 dataset, corresponding codes, and pre-trained models will be disseminated to the community for future research.