 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Semantic Atomic Skills for Multi-Task Robotic Manipulation
Dec 20, 2025While imitation learning has shown impressive results in single-task robot manipulation, scaling it to multi-task settings remains a fundamental challenge due to issues such as suboptimal demonstrations, trajectory noise, and behavioral multi-modality. Existing skill-based methods attempt to address this by decomposing actions into reusable abstractions, but they often rely on fixed-length segmentation or environmental priors that limit semantic consistency and cross-task generalization. In this work, we propose AtomSkill, a novel multi-task imitation learning framework that learns and leverages a structured Atomic Skill Space for composable robot manipulation. Our approach is built on two key technical contributions. First, we construct a Semantically Grounded Atomic Skill Library by partitioning demonstrations into variable-length skills using gripper-state keyframe detection and vision-language model annotation. A contrastive learning objective ensures the resulting skill embeddings are both semantically consistent and temporally coherent. Second, we propose an Action Generation module with Keypose Imagination, which jointly predicts a skill's long-horizon terminal keypose and its immediate action sequence. This enables the policy to reason about overarching motion goals and fine-grained control simultaneously, facilitating robust skill chaining. Extensive experiments in simulated and real-world environments show that AtomSkill consistently outperforms state-of-the-art methods across diverse manipulation tasks.
Sample from What You See: Visuomotor Policy Learning via Diffusion Bridge with Observation-Embedded Stochastic Differential Equation
Dec 08, 2025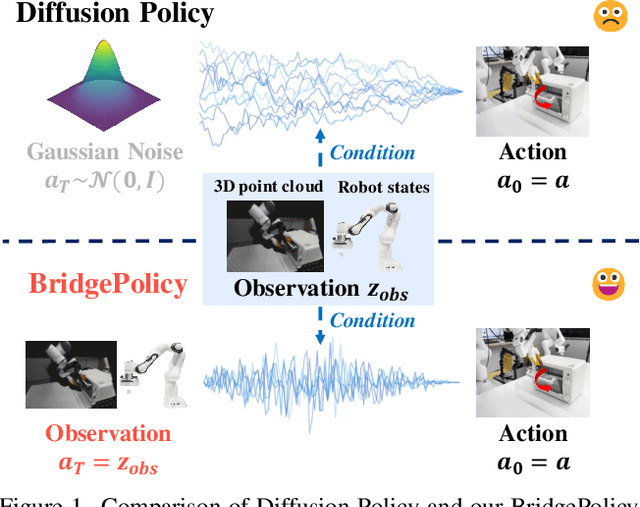
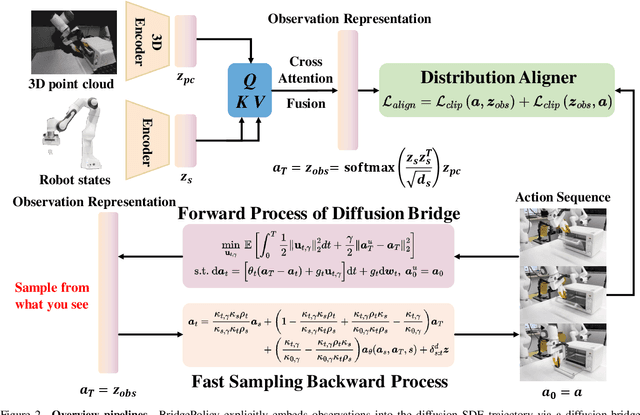
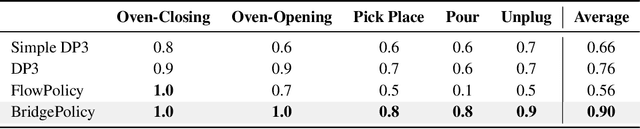
Imitation learning with diffusion models has advanced robotic control by capturing multi-modal action distributions. However, existing approaches typically treat observations as high-level conditioning inputs to the denoising network, rather than integrating them into the stochastic dynamics of the diffusion process itself. As a result, sampling must begin from random Gaussian noise, weakening the coupling between perception and control and often yielding suboptimal performance. We introduce BridgePolicy, a generative visuomotor policy that explicitly embeds observations within the stochastic differential equation via a diffusion-bridge formulation. By constructing an observation-informed trajectory, BridgePolicy enables sampling to start from a rich, informative prior rather than random noise, substantially improving precision and reliability in control. A key challenge is that classical diffusion bridges connect distributions with matched dimensionality, whereas robotic observations are heterogeneous and multi-modal and do not naturally align with the action space. To address this, we design a multi-modal fusion module and a semantic aligner that unify visual and state inputs and align observation and action representations, making the bridge applicable to heterogeneous robot data. Extensive experiments across 52 simulation tasks on three benchmarks and five real-world tasks demonstrate that BridgePolicy consistently outperforms state-of-the-art generative policies.
One-Step Generative Policies with Q-Learning: A Reformulation of MeanFlow
Nov 17, 2025We introduce a one-step generative policy for offline reinforcement learning that maps noise directly to actions via a residual reformulation of MeanFlow, making it compatible with Q-learning. While one-step Gaussian policies enable fast inference, they struggle to capture complex, multimodal action distributions. Existing flow-based methods improve expressivity but typically rely on distillation and two-stage training when trained with Q-learning. To overcome these limitations, we propose to reformulate MeanFlow to enable direct noise-to-action generation by integrating the velocity field and noise-to-action transformation into a single policy network-eliminating the need for separate velocity estimation. We explore several reformulation variants and identify an effective residual formulation that supports expressive and stable policy learning. Our method offers three key advantages: 1) efficient one-step noise-to-action generation, 2) expressive modelling of multimodal action distributions, and 3) efficient and stable policy learning via Q-learning in a single-stage training setup. Extensive experiments on 73 tasks across the OGBench and D4RL benchmarks demonstrate that our method achieves strong performance in both offline and offline-to-online reinforcement learning settings. Code is available at https://github.com/HiccupRL/MeanFlowQL.
OpenHOI: Open-World Hand-Object Interaction Synthesis with Multimodal Large Language Model
May 25, 2025Understanding and synthesizing realistic 3D hand-object interactions (HOI) is critical for applications ranging from immersive AR/VR to dexterous robotics. Existing methods struggle with generalization, performing well on closed-set objects and predefined tasks but failing to handle unseen objects or open-vocabulary instructions. We introduce OpenHOI, the first framework for open-world HOI synthesis, capable of generating long-horizon manipulation sequences for novel objects guided by free-form language commands. Our approach integrates a 3D Multimodal Large Language Model (MLLM) fine-tuned for joint affordance grounding and semantic task decomposition, enabling precise localization of interaction regions (e.g., handles, buttons) and breakdown of complex instructions (e.g., "Find a water bottle and take a sip") into executable sub-tasks. To synthesize physically plausible interactions, we propose an affordance-driven diffusion model paired with a training-free physics refinement stage that minimizes penetration and optimizes affordance alignment. Evaluations across diverse scenarios demonstrate OpenHOI's superiority over state-of-the-art methods in generalizing to novel object categories, multi-stage tasks, and complex language instructions. Our project page at \href{https://openhoi.github.io}
GenPO: Generative Diffusion Models Meet On-Policy Reinforcement Learning
May 24, 2025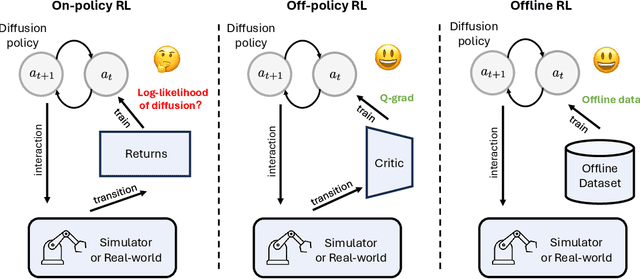

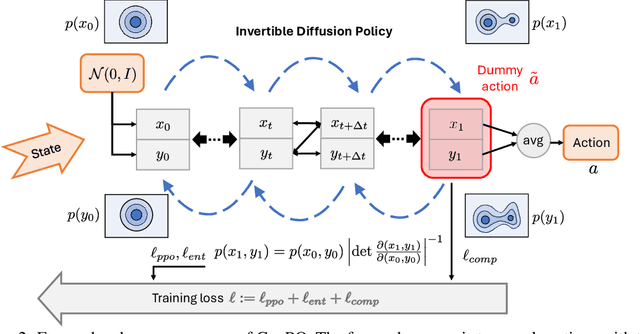
Recent advances in reinforcement learning (RL) have demonstrated the powerful exploration capabilities and multimodality of generative diffusion-based policies. While substantial progress has been made in offline RL and off-policy RL settings, integrating diffusion policies into on-policy frameworks like PPO remains underexplored. This gap is particularly significant given the widespread use of large-scale parallel GPU-accelerated simulators, such as IsaacLab, which are optimized for on-policy RL algorithms and enable rapid training of complex robotic tasks. A key challenge lies in computing state-action log-likelihoods under diffusion policies, which is straightforward for Gaussian policies but intractable for flow-based models due to irreversible forward-reverse processes and discretization errors (e.g., Euler-Maruyama approximations). To bridge this gap, we propose GenPO, a generative policy optimization framework that leverages exact diffusion inversion to construct invertible action mappings. GenPO introduces a novel doubled dummy action mechanism that enables invertibility via alternating updates, resolving log-likelihood computation barriers. Furthermore, we also use the action log-likelihood for unbiased entropy and KL divergence estimation, enabling KL-adaptive learning rates and entropy regularization in on-policy updates. Extensive experiments on eight IsaacLab benchmarks, including legged locomotion (Ant, Humanoid, Anymal-D, Unitree H1, Go2), dexterous manipulation (Shadow Hand), aerial control (Quadcopter), and robotic arm tasks (Franka), demonstrate GenPO's superiority over existing RL baselines. Notably, GenPO is the first method to successfully integrate diffusion policies into on-policy RL, unlocking their potential for large-scale parallelized training and real-world robotic deployment.
One Policy but Many Worlds: A Scalable Unified Policy for Versatile Humanoid Locomotion
May 24, 2025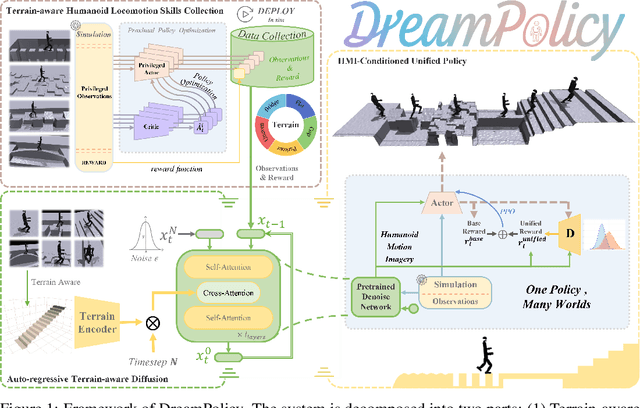
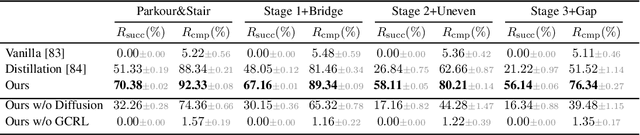

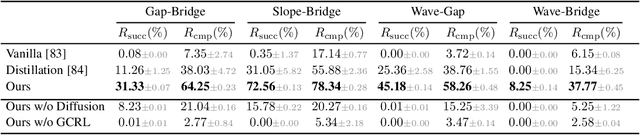
Humanoid locomotion faces a critical scalability challenge: traditional reinforcement learning (RL) methods require task-specific rewards and struggle to leverage growing datasets, even as more training terrains are introduced. We propose DreamPolicy, a unified framework that enables a single policy to master diverse terrains and generalize zero-shot to unseen scenarios by systematically integrating offline data and diffusion-driven motion synthesis. At its core, DreamPolicy introduces Humanoid Motion Imagery (HMI) - future state predictions synthesized through an autoregressive terrain-aware diffusion planner curated by aggregating rollouts from specialized policies across various distinct terrains. Unlike human motion datasets requiring laborious retargeting, our data directly captures humanoid kinematics, enabling the diffusion planner to synthesize "dreamed" trajectories that encode terrain-specific physical constraints. These trajectories act as dynamic objectives for our HMI-conditioned policy, bypassing manual reward engineering and enabling cross-terrain generalization. DreamPolicy addresses the scalability limitations of prior methods: while traditional RL fails to exploit growing datasets, our framework scales seamlessly with more offline data. As the dataset expands, the diffusion prior learns richer locomotion skills, which the policy leverages to master new terrains without retraining. Experiments demonstrate that DreamPolicy achieves average 90% success rates in training environments and an average of 20% higher success on unseen terrains than the prevalent method. It also generalizes to perturbed and composite scenarios where prior approaches collapse. By unifying offline data, diffusion-based trajectory synthesis, and policy optimization, DreamPolicy overcomes the "one task, one policy" bottleneck, establishing a paradigm for scalable, data-driven humanoid control.
UniDB: A Unified Diffusion Bridge Framework via Stochastic Optimal Control
Feb 09, 2025



Recent advances in diffusion bridge models leverage Doob's $h$-transform to establish fixed endpoints between distributions, demonstrating promising results in image translation and restoration tasks. However, these approaches frequently produce blurred or excessively smoothed image details and lack a comprehensive theoretical foundation to explain these shortcomings. To address these limitations, we propose UniDB, a unified framework for diffusion bridges based on Stochastic Optimal Control (SOC). UniDB formulates the problem through an SOC-based optimization and derives a closed-form solution for the optimal controller, thereby unifying and generalizing existing diffusion bridge models. We demonstrate that existing diffusion bridges employing Doob's $h$-transform constitute a special case of our framework, emerging when the terminal penalty coefficient in the SOC cost function tends to infinity. By incorporating a tunable terminal penalty coefficient, UniDB achieves an optimal balance between control costs and terminal penalties, substantially improving detail preservation and output quality. Notably, UniDB seamlessly integrates with existing diffusion bridge models, requiring only minimal code modifications. Extensive experiments across diverse image restoration tasks validate the superiority and adaptability of the proposed framework. Our code is available at https://github.com/UniDB-SOC/UniDB/.
Evaluating Image Caption via Cycle-consistent Text-to-Image Generation
Jan 08, 2025



Evaluating image captions typically relies on reference captions, which are costly to obtain and exhibit significant diversity and subjectivity. While reference-free evaluation metrics have been proposed, most focus on cross-modal evaluation between captions and images. Recent research has revealed that the modality gap generally exists in the representation of contrastive learning-based multi-modal systems, undermining the reliability of cross-modality metrics like CLIPScore. In this paper, we propose CAMScore, a cyclic reference-free automatic evaluation metric for image captioning models. To circumvent the aforementioned modality gap, CAMScore utilizes a text-to-image model to generate images from captions and subsequently evaluates these generated images against the original images. Furthermore, to provide fine-grained information for a more comprehensive evaluation, we design a three-level evaluation framework for CAMScore that encompasses pixel-level, semantic-level, and objective-level perspectives. Extensive experiment results across multiple benchmark datasets show that CAMScore achieves a superior correlation with human judgments compared to existing reference-based and reference-free metrics, demonstrating the effectiveness of the framework.
AffordDP: Generalizable Diffusion Policy with Transferable Affordance
Dec 04, 2024



Diffusion-based policies have shown impressive performance in robotic manipulation tasks while struggling with out-of-domain distributions. Recent efforts attempted to enhance generalization by improving the visual feature encoding for diffusion policy. However, their generalization is typically limited to the same category with similar appearances. Our key insight is that leveraging affordances--manipulation priors that define "where" and "how" an agent interacts with an object--can substantially enhance generalization to entirely unseen object instances and categories. We introduce the Diffusion Policy with transferable Affordance (AffordDP), designed for generalizable manipulation across novel categories. AffordDP models affordances through 3D contact points and post-contact trajectories, capturing the essential static and dynamic information for complex tasks. The transferable affordance from in-domain data to unseen objects is achieved by estimating a 6D transformation matrix using foundational vision models and point cloud registration techniques. More importantly, we incorporate affordance guidance during diffusion sampling that can refine action sequence generation. This guidance directs the generated action to gradually move towards the desired manipulation for unseen objects while keeping the generated action within the manifold of action space. Experimental results from both simulated and real-world environments demonstrate that AffordDP consistently outperforms previous diffusion-based methods, successfully generalizing to unseen instances and categories where others fail.
NLPrompt: Noise-Label Prompt Learning for Vision-Language Models
Dec 02, 2024



The emergence of vision-language foundation models, such as CLIP, has revolutionized image-text representation, enabling a broad range of applications via prompt learning. Despite its promise, real-world datasets often contain noisy labels that can degrade prompt learning performance. In this paper, we demonstrate that using mean absolute error (MAE) loss in prompt learning, named PromptMAE, significantly enhances robustness against noisy labels while maintaining high accuracy. Though MAE is straightforward and recognized for its robustness, it is rarely used in noisy-label learning due to its slow convergence and poor performance outside prompt learning scenarios. To elucidate the robustness of PromptMAE, we leverage feature learning theory to show that MAE can suppress the influence of noisy samples, thereby improving the signal-to-noise ratio and enhancing overall robustness. Additionally, we introduce PromptOT, a prompt-based optimal transport data purification method to enhance the robustness further. PromptOT employs text encoder representations in vision-language models as prototypes to construct an optimal transportation matrix. This matrix effectively partitions datasets into clean and noisy subsets, allowing for the application of cross-entropy loss to the clean subset and MAE loss to the noisy subset. Our Noise-Label Prompt Learning method, named NLPrompt, offers a simple and efficient approach that leverages the expressive representation and precise alignment capabilities of vision-language models for robust prompt learning. We validate NLPrompt through extensive experiments across various noise settings, demonstrating significant performance improvements.