 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoloBrain-0 Technical Report
Feb 12, 2026In this work, we introduce HoloBrain-0, a comprehensive Vision-Language-Action (VLA) framework that bridges the gap between foundation model research and reliable real-world robot deployment. The core of our system is a novel VLA architecture that explicitly incorporates robot embodiment priors, including multi-view camera parameters and kinematic descriptions (URDF), to enhance 3D spatial reasoning and support diverse embodiments. We validate this design through a scalable ``pre-train then post-train" paradigm, achieving state-of-the-art results on simulation benchmarks such as RoboTwin 2.0, LIBERO, and GenieSim, as well as strong results on challenging long-horizon real-world manipulation tasks. Notably, our efficient 0.2B-parameter variant rivals significantly larger baselines, enabling low-latency on-device deployment. To further accelerate research and practical adoption, we fully open-source the entire HoloBrain ecosystem, which includes: (1) powerful pre-trained VLA foundations; (2) post-trained checkpoints for multiple simulation suites and real-world tasks; and (3) RoboOrchard, a full-stack VLA infrastructure for data curation, model training and deployment. Together with standardized data collection protocols, this release provides the community with a complete, reproducible path toward high-performance robotic manipulation.
Learning Semantic Atomic Skills for Multi-Task Robotic Manipulation
Dec 20, 2025While imitation learning has shown impressive results in single-task robot manipulation, scaling it to multi-task settings remains a fundamental challenge due to issues such as suboptimal demonstrations, trajectory noise, and behavioral multi-modality. Existing skill-based methods attempt to address this by decomposing actions into reusable abstractions, but they often rely on fixed-length segmentation or environmental priors that limit semantic consistency and cross-task generalization. In this work, we propose AtomSkill, a novel multi-task imitation learning framework that learns and leverages a structured Atomic Skill Space for composable robot manipulation. Our approach is built on two key technical contributions. First, we construct a Semantically Grounded Atomic Skill Library by partitioning demonstrations into variable-length skills using gripper-state keyframe detection and vision-language model annotation. A contrastive learning objective ensures the resulting skill embeddings are both semantically consistent and temporally coherent. Second, we propose an Action Generation module with Keypose Imagination, which jointly predicts a skill's long-horizon terminal keypose and its immediate action sequence. This enables the policy to reason about overarching motion goals and fine-grained control simultaneously, facilitating robust skill chaining. Extensive experiments in simulated and real-world environments show that AtomSkill consistently outperforms state-of-the-art methods across diverse manipulation tasks.
AffordDP: Generalizable Diffusion Policy with Transferable Affordance
Dec 04, 2024



Diffusion-based policies have shown impressive performance in robotic manipulation tasks while struggling with out-of-domain distributions. Recent efforts attempted to enhance generalization by improving the visual feature encoding for diffusion policy. However, their generalization is typically limited to the same category with similar appearances. Our key insight is that leveraging affordances--manipulation priors that define "where" and "how" an agent interacts with an object--can substantially enhance generalization to entirely unseen object instances and categories. We introduce the Diffusion Policy with transferable Affordance (AffordDP), designed for generalizable manipulation across novel categories. AffordDP models affordances through 3D contact points and post-contact trajectories, capturing the essential static and dynamic information for complex tasks. The transferable affordance from in-domain data to unseen objects is achieved by estimating a 6D transformation matrix using foundational vision models and point cloud registration techniques. More importantly, we incorporate affordance guidance during diffusion sampling that can refine action sequence generation. This guidance directs the generated action to gradually move towards the desired manipulation for unseen objects while keeping the generated action within the manifold of action space. Experimental results from both simulated and real-world environments demonstrate that AffordDP consistently outperforms previous diffusion-based methods, successfully generalizing to unseen instances and categories where others fail.
MixCE: Training Autoregressive Language Models by Mixing Forward and Reverse Cross-Entropies
May 26, 2023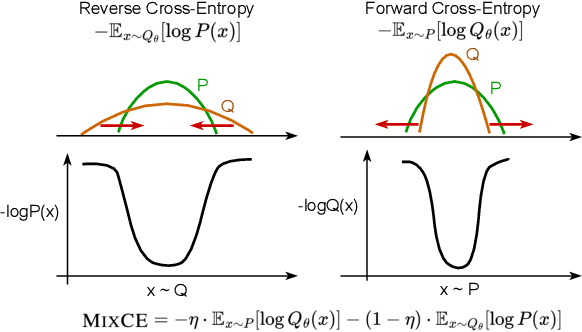
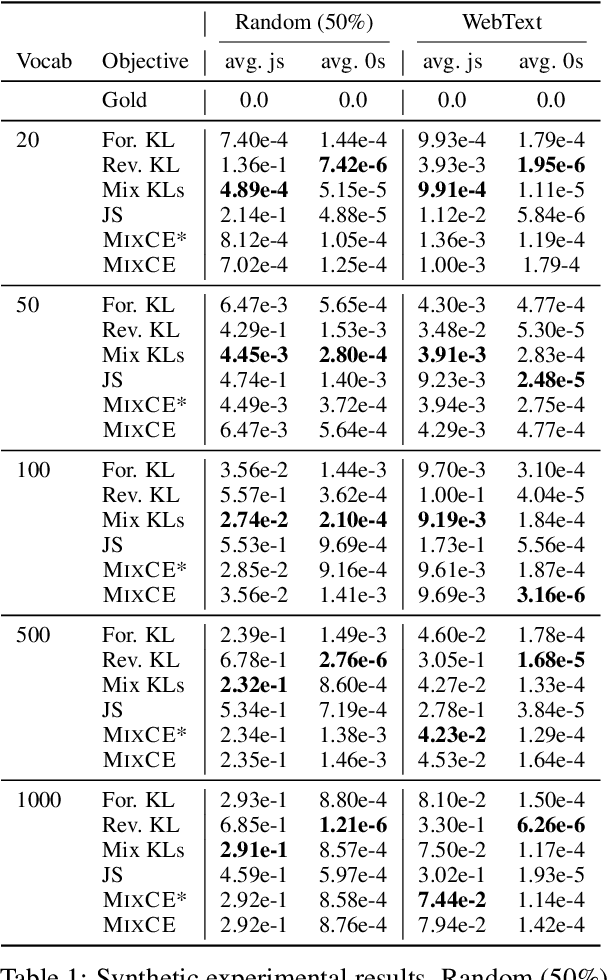
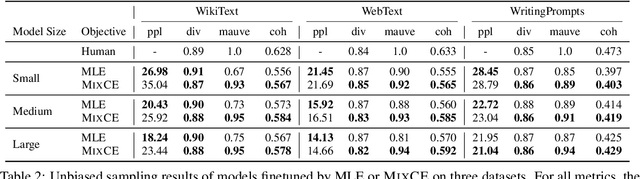
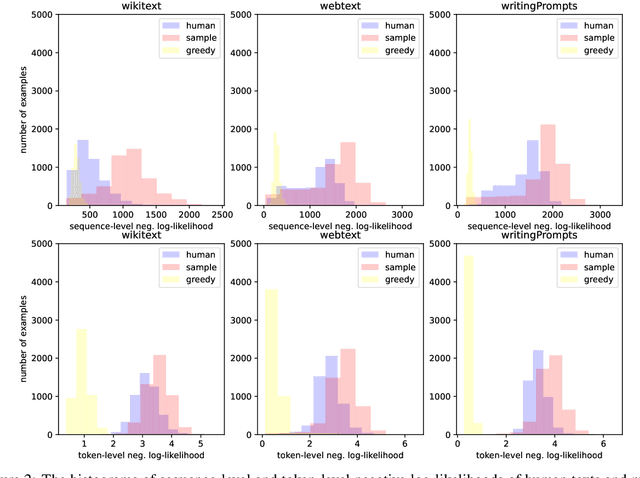
Autoregressive language models are trained by minimizing the cross-entropy of the model distribution Q relative to the data distribution P -- that is, minimizing the forward cross-entropy, which is equivalent to maximum likelihood estimation (MLE). We have observed that models trained in this way may "over-generalize", in the sense that they produce non-human-like text. Moreover, we believe that reverse cross-entropy, i.e., the cross-entropy of P relative to Q, is a better reflection of how a human would evaluate text generated by a model. Hence, we propose learning with MixCE, an objective that mixes the forward and reverse cross-entropies. We evaluate models trained with this objective on synthetic data settings (where P is known) and real data, and show that the resulting models yield better generated text without complex decoding strategies. Our code and models are publicly available at https://github.com/bloomberg/mixce-acl2023
Overcoming Catastrophic Forgetting in Massively Multilingual Continual Learning
May 25, 2023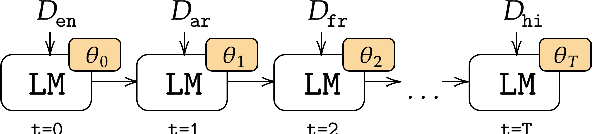
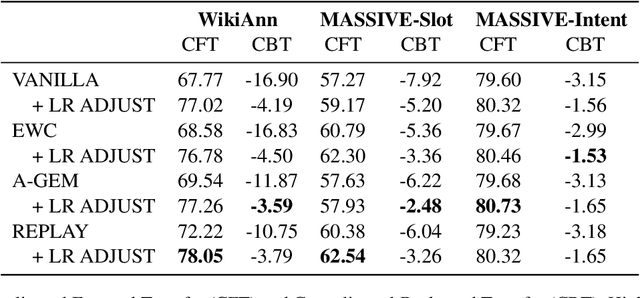
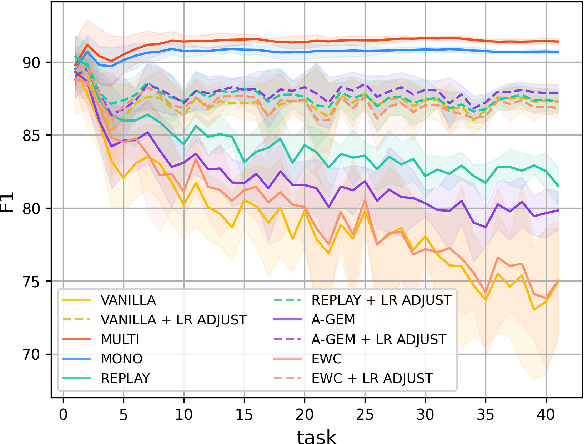
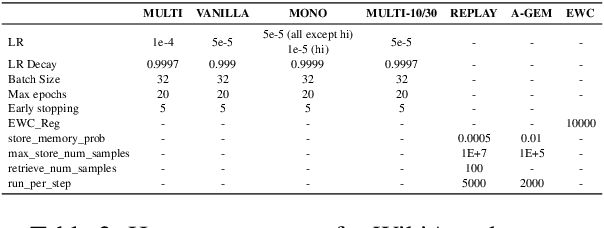
Real-life multilingual systems should be able to efficiently incorporate new languages as data distributions fed to the system evolve and shift over time. To do this, systems need to handle the issue of catastrophic forgetting, where the model performance drops for languages or tasks seen further in its past. In this paper, we study catastrophic forgetting, as well as methods to minimize this, in a massively multilingual continual learning framework involving up to 51 languages and covering both classification and sequence labeling tasks. We present LR ADJUST, a learning rate scheduling method that is simple, yet effective in preserving new information without strongly overwriting past knowledge. Furthermore, we show that this method is effective across multiple continual learning approaches. Finally, we provide further insights into the dynamics of catastrophic forgetting in this massively multilingual setup.
BloombergGPT: A Large Language Model for Finance
Mar 30, 2023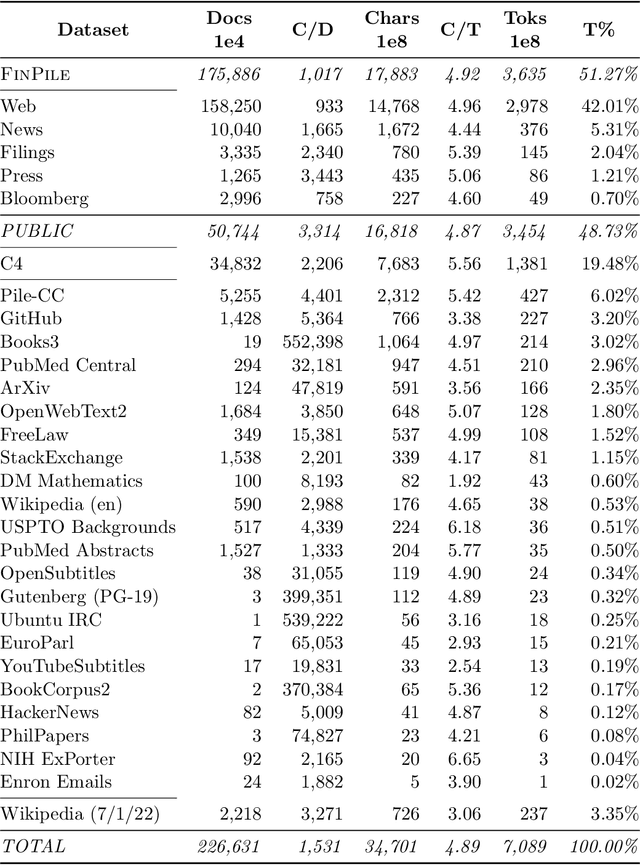
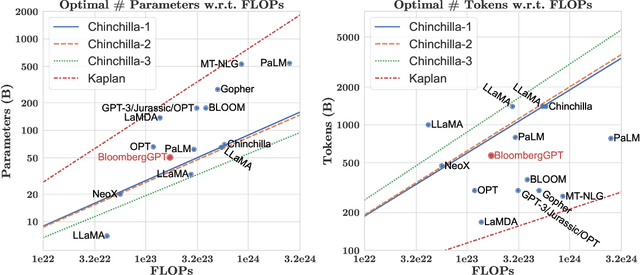
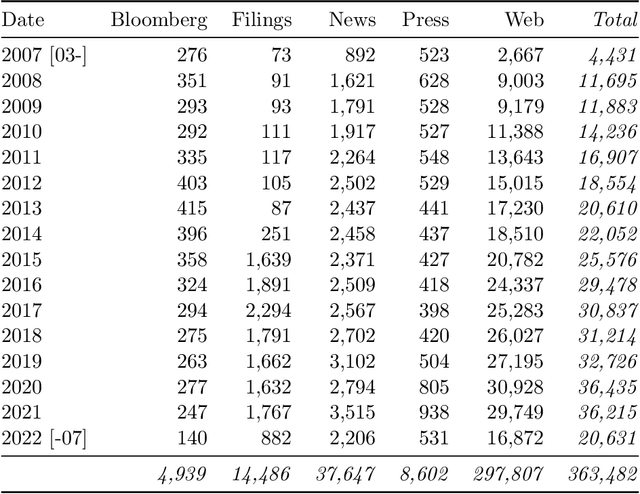
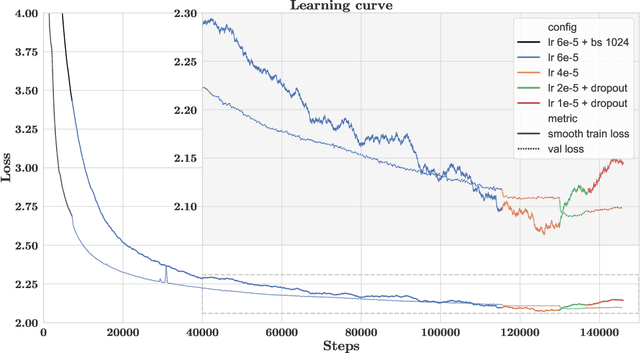
The use of NLP in the realm of financial technology is broad and complex, with applications ranging from sentiment analysis and named entity recognition to question answering. Large Language Models (LLMs) have been shown to be effective on a variety of tasks; however, no LLM specialized for the financial domain has been reported in literature. In this work, we present BloombergGPT, a 50 billion parameter language model that is trained on a wide range of financial data. We construct a 363 billion token dataset based on Bloomberg's extensive data sources, perhaps the largest domain-specific dataset yet, augmented with 345 billion tokens from general purpose datasets. We validate BloombergGPT on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that most accurately reflect our intended usage. Our mixed dataset training leads to a model that outperforms existing models on financial tasks by significant margins without sacrificing performance on general LLM benchmarks. Additionally, we explain our modeling choices, training process, and evaluation methodology. As a next step, we plan to release training logs (Chronicles) detailing our experience in training BloombergGPT.
BoundaryFace: A mining framework with noise label self-correction for Face Recognition
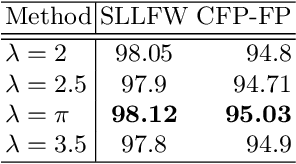
Oct 10, 2022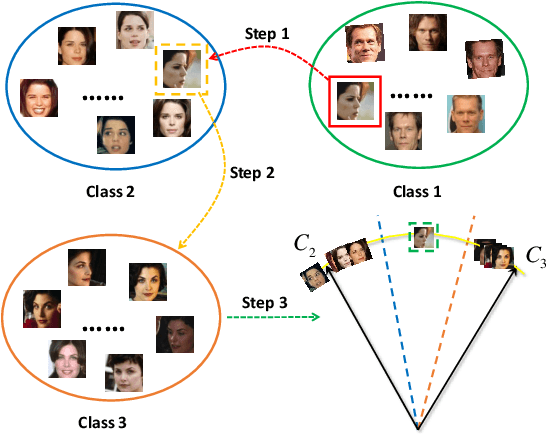


Face recognition has made tremendous progress in recent years due to the advances in loss functions and the explosive growth in training sets size. A properly designed loss is seen as key to extract discriminative features for classification. Several margin-based losses have been proposed as alternatives of softmax loss in face recognition. However, two issues remain to consider: 1) They overlook the importance of hard sample mining for discriminative learning. 2) Label noise ubiquitously exists in large-scale datasets, which can seriously damage the model's performance. In this paper, starting from the perspective of decision boundary, we propose a novel mining framework that focuses on the relationship between a sample's ground truth class center and its nearest negative class center. Specifically, a closed-set noise label self-correction module is put forward, making this framework work well on datasets containing a lot of label noise. The proposed method consistently outperforms SOTA methods in various face recognition benchmarks. Training code has been released at https://github.com/SWJTU-3DVision/BoundaryFace.
How Do Multilingual Encoders Learn Cross-lingual Representation?
Jul 12, 2022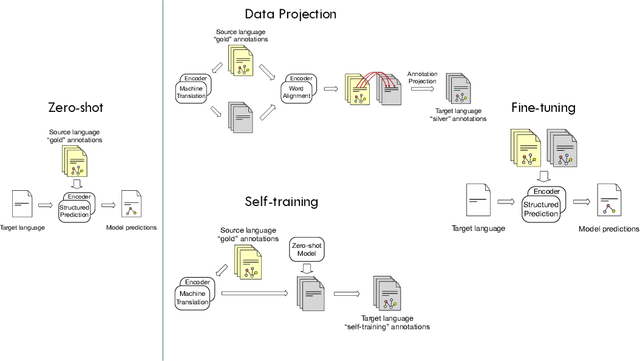

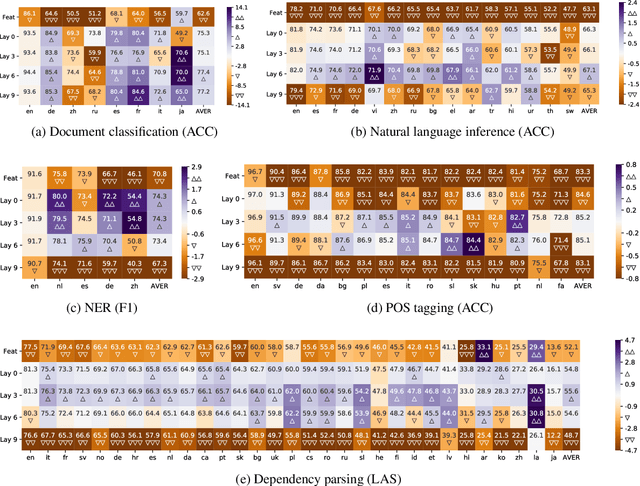
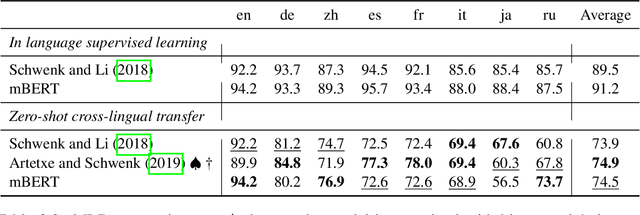
NLP systems typically require support for more than one language. As different languages have different amounts of supervision, cross-lingual transfer benefits languages with little to no training data by transferring from other languages. From an engineering perspective, multilingual NLP benefits development and maintenance by serving multiple languages with a single system. Both cross-lingual transfer and multilingual NLP rely on cross-lingual representations serving as the foundation. As BERT revolutionized representation learning and NLP, it also revolutionized cross-lingual representations and cross-lingual transfer. Multilingual BERT was released as a replacement for single-language BERT, trained with Wikipedia data in 104 languages. Surprisingly, without any explicit cross-lingual signal, multilingual BERT learns cross-lingual representations in addition to representations for individual languages. This thesis first shows such surprising cross-lingual effectiveness compared against prior art on various tasks. Naturally, it raises a set of questions, most notably how do these multilingual encoders learn cross-lingual representations. In exploring these questions, this thesis will analyze the behavior of multilingual models in a variety of settings on high and low resource languages. We also look at how to inject different cross-lingual signals into multilingual encoders, and the optimization behavior of cross-lingual transfer with these models. Together, they provide a better understanding of multilingual encoders on cross-lingual transfer. Our findings will lead us to suggested improvements to multilingual encoders and cross-lingual transfer.
Zero-shot Cross-lingual Transfer is Under-specified Optimization
Jul 12, 2022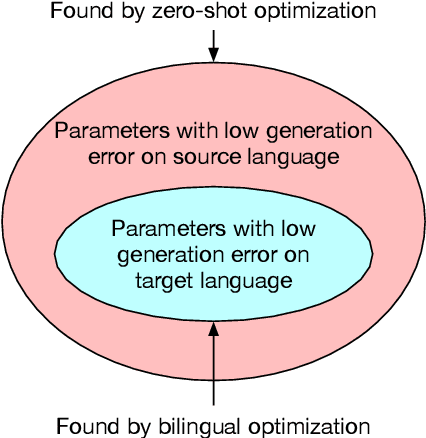
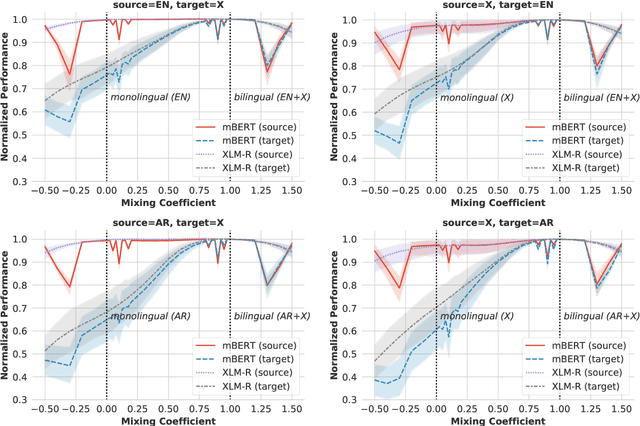
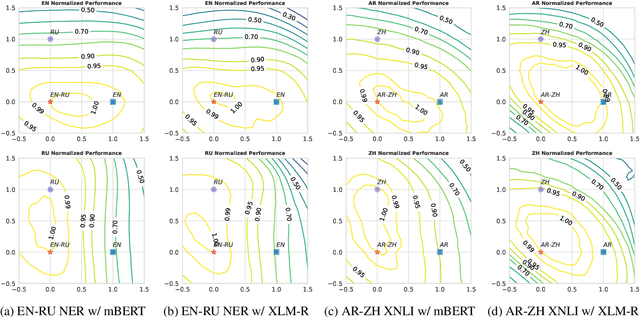
Pretrained multilingual encoders enable zero-shot cross-lingual transfer, but often produce unreliable models that exhibit high performance variance on the target language. We postulate that this high variance results from zero-shot cross-lingual transfer solving an under-specified optimization problem. We show that any linear-interpolated model between the source language monolingual model and source + target bilingual model has equally low source language generalization error, yet the target language generalization error reduces smoothly and linearly as we move from the monolingual to bilingual model, suggesting that the model struggles to identify good solutions for both source and target languages using the source language alone. Additionally, we show that zero-shot solution lies in non-flat region of target language error generalization surface, causing the high variance.
Everything Is All It Takes: A Multipronged Strategy for Zero-Shot Cross-Lingual Information Extraction
Sep 14, 2021

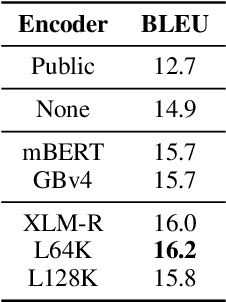

Zero-shot cross-lingual information extraction (IE) describes the construction of an IE model for some target language, given existing annotations exclusively in some other language, typically English. While the advance of pretrained multilingual encoders suggests an easy optimism of "train on English, run on any language", we find through a thorough exploration and extension of techniques that a combination of approaches, both new and old, leads to better performance than any one cross-lingual strategy in particular. We explore techniques including data projection and self-training, and how different pretrained encoders impact them. We use English-to-Arabic IE as our initial example, demonstrating strong performance in this setting for event extraction, named entity recognition, part-of-speech tagging, and dependency parsing. We then apply data projection and self-training to three tasks across eight target languages. Because no single set of techniques performs the best across all tasks, we encourage practitioners to explore various configurations of the techniques described in this work when seeking to improve on zero-shot training.