 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Multilingual Encoders Learn Cross-lingual Representation?
Paper and Code
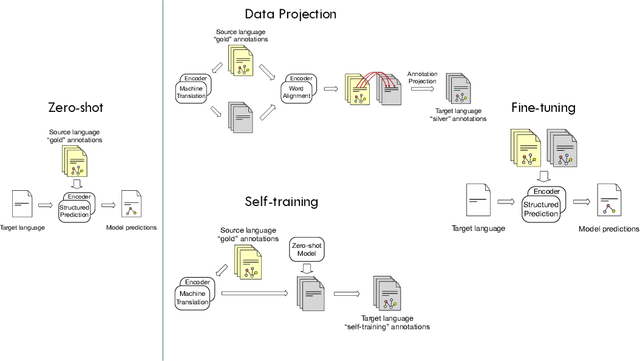

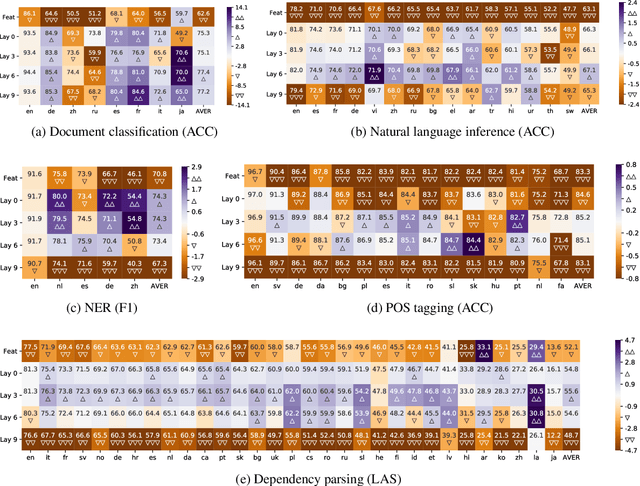
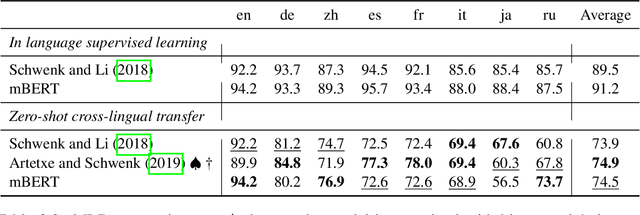
NLP systems typically require support for more than one language. As different languages have different amounts of supervision, cross-lingual transfer benefits languages with little to no training data by transferring from other languages. From an engineering perspective, multilingual NLP benefits development and maintenance by serving multiple languages with a single system. Both cross-lingual transfer and multilingual NLP rely on cross-lingual representations serving as the foundation. As BERT revolutionized representation learning and NLP, it also revolutionized cross-lingual representations and cross-lingual transfer. Multilingual BERT was released as a replacement for single-language BERT, trained with Wikipedia data in 104 languages. Surprisingly, without any explicit cross-lingual signal, multilingual BERT learns cross-lingual representations in addition to representations for individual languages. This thesis first shows such surprising cross-lingual effectiveness compared against prior art on various tasks. Naturally, it raises a set of questions, most notably how do these multilingual encoders learn cross-lingual representations. In exploring these questions, this thesis will analyze the behavior of multilingual models in a variety of settings on high and low resource languages. We also look at how to inject different cross-lingual signals into multilingual encoders, and the optimization behavior of cross-lingual transfer with these models. Together, they provide a better understanding of multilingual encoders on cross-lingual transfer. Our findings will lead us to suggested improvements to multilingual encoders and cross-lingual transfer.