 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBloombergGPT: A Large Language Model for Finance
Mar 30, 2023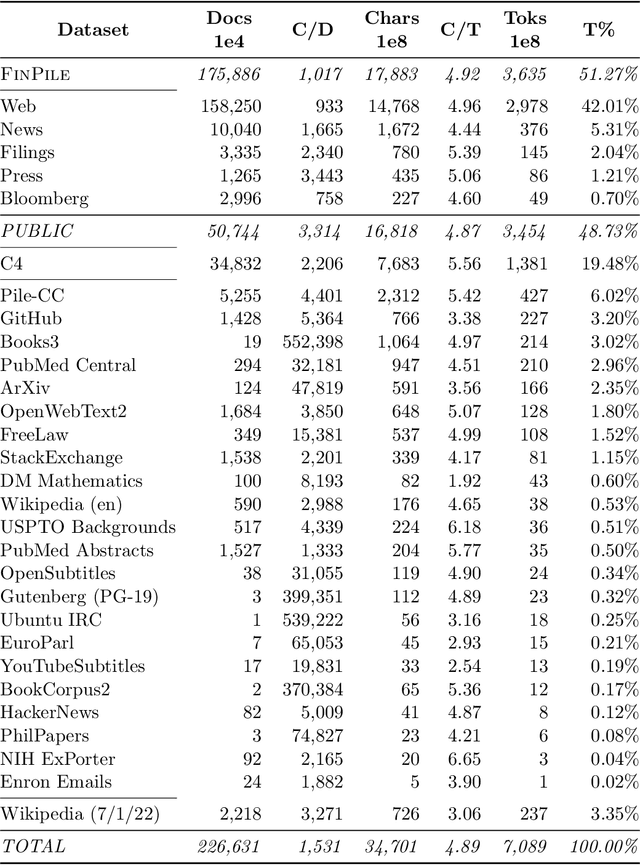
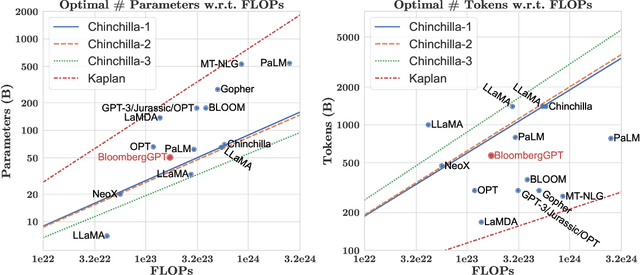
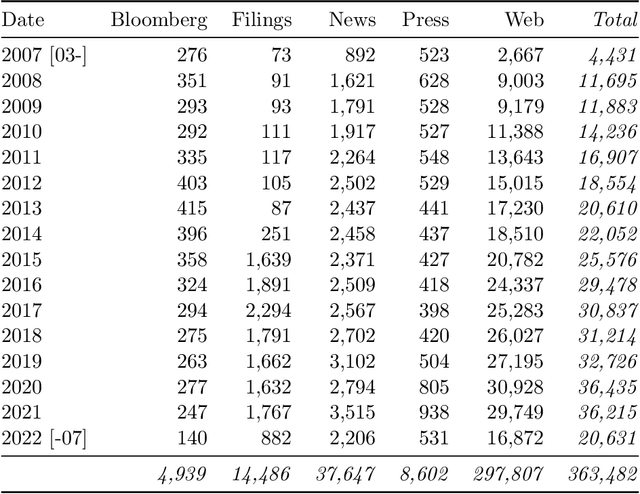
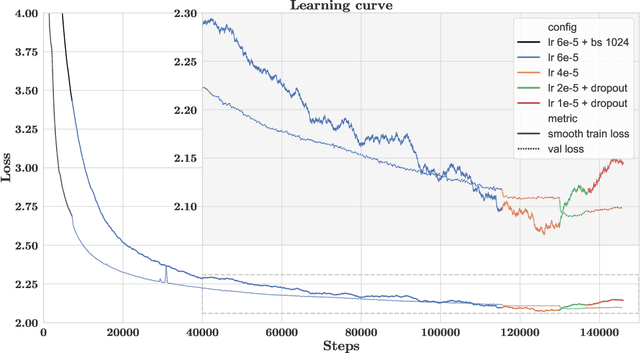
The use of NLP in the realm of financial technology is broad and complex, with applications ranging from sentiment analysis and named entity recognition to question answering. Large Language Models (LLMs) have been shown to be effective on a variety of tasks; however, no LLM specialized for the financial domain has been reported in literature. In this work, we present BloombergGPT, a 50 billion parameter language model that is trained on a wide range of financial data. We construct a 363 billion token dataset based on Bloomberg's extensive data sources, perhaps the largest domain-specific dataset yet, augmented with 345 billion tokens from general purpose datasets. We validate BloombergGPT on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that most accurately reflect our intended usage. Our mixed dataset training leads to a model that outperforms existing models on financial tasks by significant margins without sacrificing performance on general LLM benchmarks. Additionally, we explain our modeling choices, training process, and evaluation methodology. As a next step, we plan to release training logs (Chronicles) detailing our experience in training BloombergGPT.
Dual Reinforcement-Based Specification Generation for Image De-Rendering
Mar 02, 2021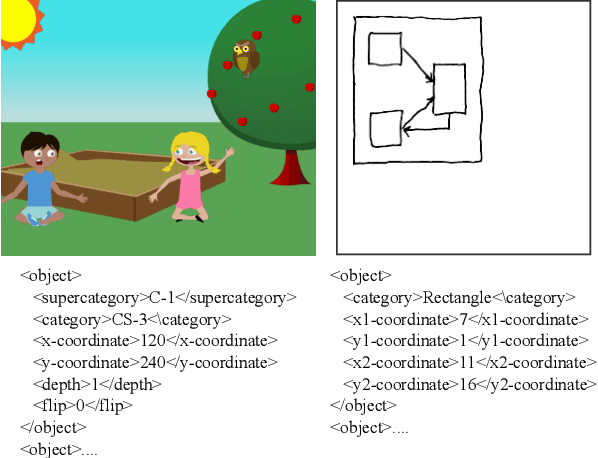
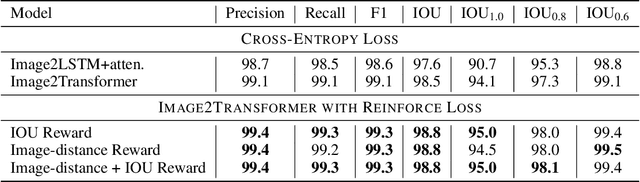
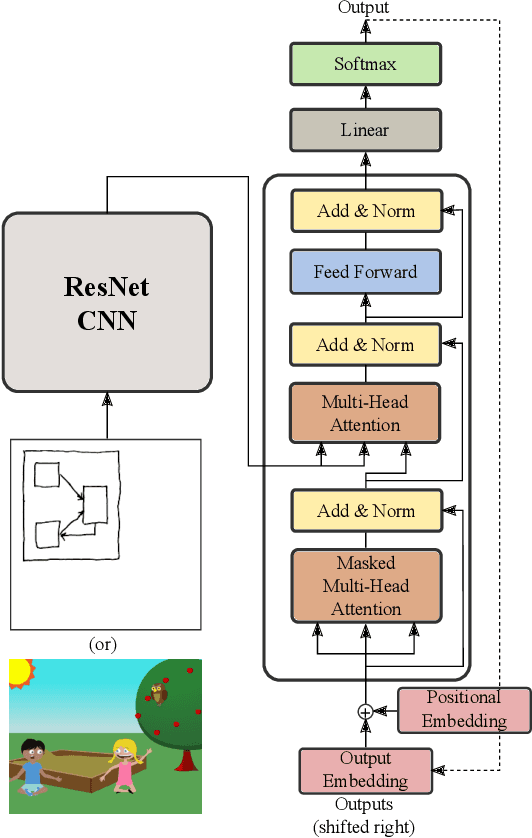
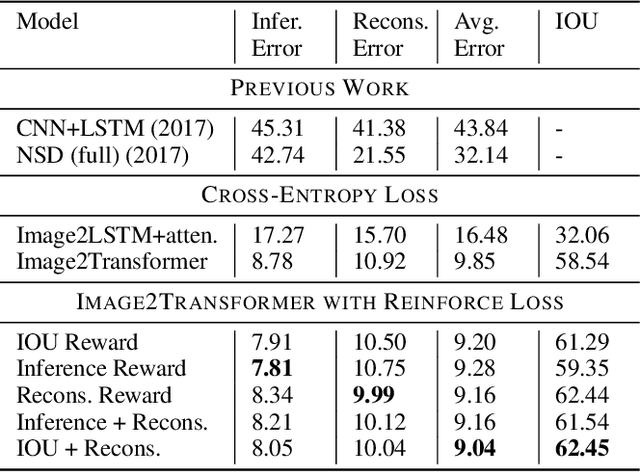
Advances in deep learning have led to promising progress in inferring graphics programs by de-rendering computer-generated images. However, current methods do not explore which decoding methods lead to better inductive bias for inferring graphics programs. In our work, we first explore the effectiveness of LSTM-RNN versus Transformer networks as decoders for order-independent graphics programs. Since these are sequence models, we must choose an ordering of the objects in the graphics programs for likelihood training. We found that the LSTM performance was highly sensitive to the sequence ordering (random order vs. pattern-based order), while Transformer performance was roughly independent of the sequence ordering. Further, we present a policy gradient based reinforcement learning approach for better inductive bias in the decoder via multiple diverse rewards based both on the graphics program specification and the rendered image. We also explore the combination of these complementary rewards. We achieve state-of-the-art results on two graphics program generation datasets.
Improving Grey-Box Fuzzing by Modeling Program Behavior
Nov 21, 2018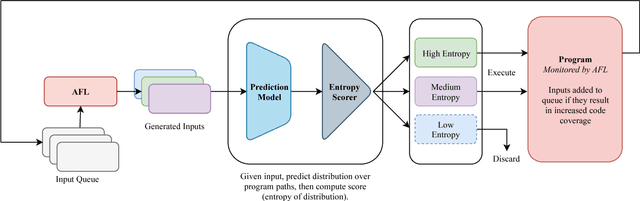

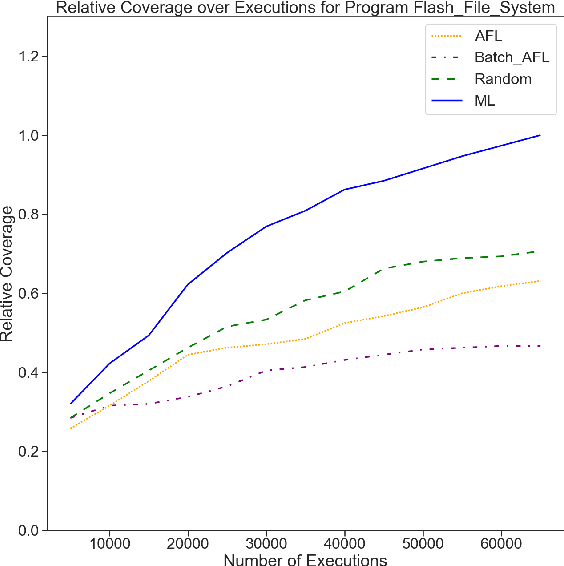
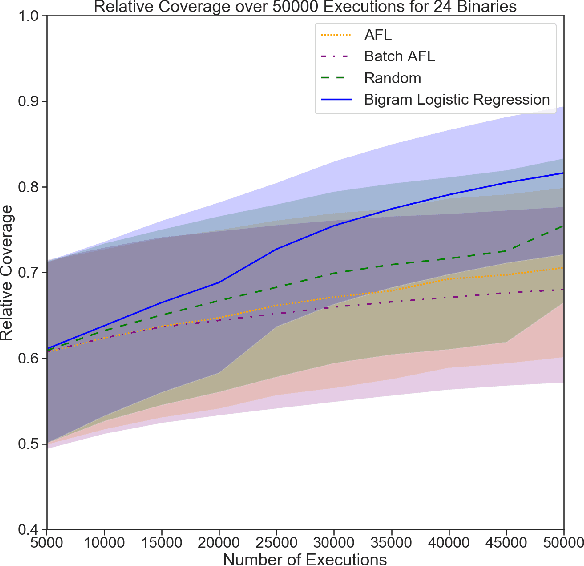
Grey-box fuzzers such as American Fuzzy Lop (AFL) are popular tools for finding bugs and potential vulnerabilities in programs. While these fuzzers have been able to find vulnerabilities in many widely used programs, they are not efficient; of the millions of inputs executed by AFL in a typical fuzzing run, only a handful discover unseen behavior or trigger a crash. The remaining inputs are redundant, exhibiting behavior that has already been observed. Here, we present an approach to increase the efficiency of fuzzers like AFL by applying machine learning to directly model how programs behave. We learn a forward prediction model that maps program inputs to execution traces, training on the thousands of inputs collected during standard fuzzing. This learned model guides exploration by focusing on fuzzing inputs on which our model is the most uncertain (measured via the entropy of the predicted execution trace distribution). By focusing on executing inputs our learned model is unsure about, and ignoring any input whose behavior our model is certain about, we show that we can significantly limit wasteful execution. Through testing our approach on a set of binaries released as part of the DARPA Cyber Grand Challenge, we show that our approach is able to find a set of inputs that result in more code coverage and discovered crashes than baseline fuzzers with significantly fewer executions.
Adaptive Grey-Box Fuzz-Testing with Thompson Sampling
Aug 24, 2018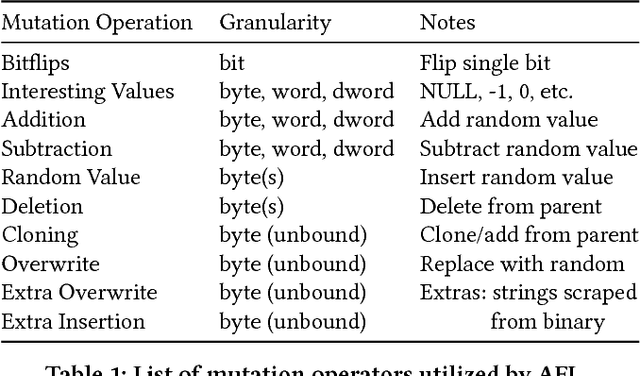
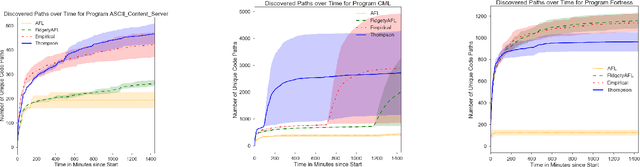
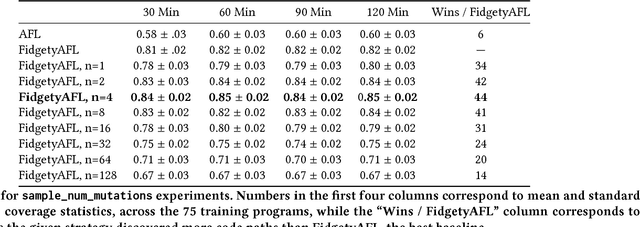
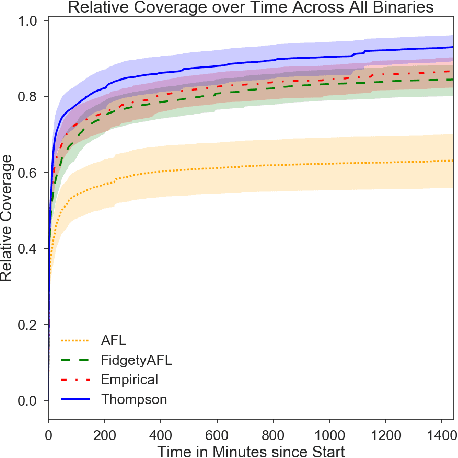
Fuzz testing, or "fuzzing," refers to a widely deployed class of techniques for testing programs by generating a set of inputs for the express purpose of finding bugs and identifying security flaws. Grey-box fuzzing, the most popular fuzzing strategy, combines light program instrumentation with a data driven process to generate new program inputs. In this work, we present a machine learning approach that builds on AFL, the preeminent grey-box fuzzer, by adaptively learning a probability distribution over its mutation operators on a program-specific basis. These operators, which are selected uniformly at random in AFL and mutational fuzzers in general, dictate how new inputs are generated, a core part of the fuzzer's efficacy. Our main contributions are two-fold: First, we show that a sampling distribution over mutation operators estimated from training programs can significantly improve performance of AFL. Second, we introduce a Thompson Sampling, bandit-based optimization approach that fine-tunes the mutator distribution adaptively, during the course of fuzzing an individual program. A set of experiments across complex programs demonstrates that tuning the mutational operator distribution generates sets of inputs that yield significantly higher code coverage and finds more crashes faster and more reliably than both baseline versions of AFL as well as other AFL-based learning approaches.
Twitter as a Source of Global Mobility Patterns for Social Good
Jun 20, 2016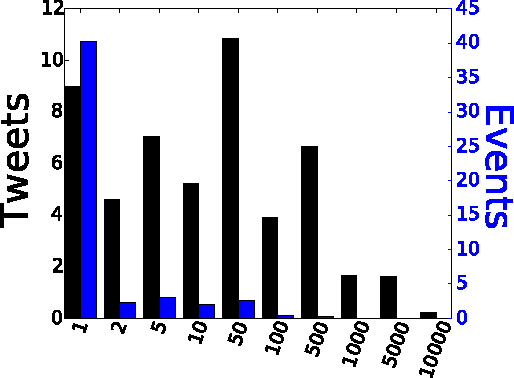
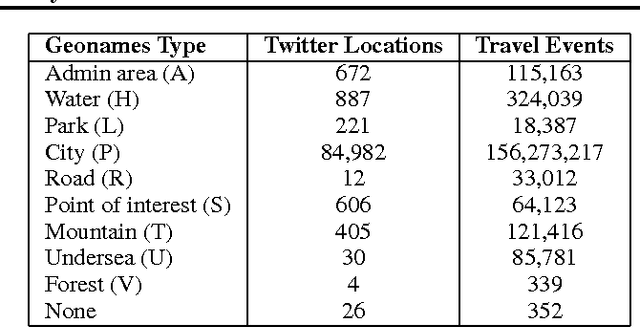
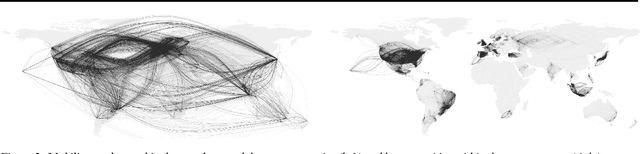
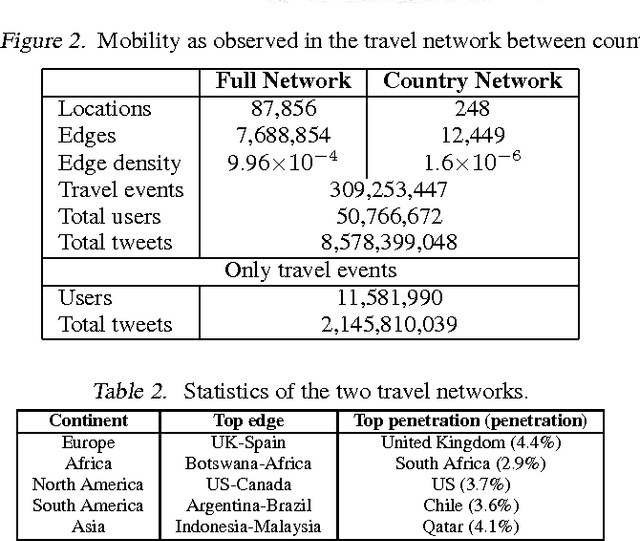
Data on human spatial distribution and movement is essential for understanding and analyzing social systems. However existing sources for this data are lacking in various ways; difficult to access, biased, have poor geographical or temporal resolution, or are significantly delayed. In this paper, we describe how geolocation data from Twitter can be used to estimate global mobility patterns and address these shortcomings. These findings will inform how this novel data source can be harnessed to address humanitarian and development efforts.