 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Automatic Trace Gas Plume Detection
May 05, 2026Future imaging spectrometers will increase data volumes by orders of magnitude, requiring automated detection of trace gas point sources. We present a fully automated framework that combines machine learning-based morphological analysis with physics-based spectroscopic fitting to detect plumes without human participation. Applied to EMIT imaging spectrometer data, the system operates in two modes: "daily digest" that runs automatically on all downlinked data, flagging the largest events for immediate response, and a retrospective analysis that identifies plumes missed by prior human review. The daily digest demonstrates that a significant fraction of the largest plumes can be detected automatically with negligible false positives, while retrospective analysis suggests at least 25% of plumes may have been overlooked. In addition to the previously observed methane point sources, we extend detection to three understudied trace gases: NH3, NO2 and the first observations of carbon monoxide (CO) plume in EMIT imagery.
MOMO: Mars Orbital Model Foundation Model for Mars Orbital Applications
Apr 03, 2026We introduce MOMO, the first multi-sensor foundation model for Mars remote sensing. MOMO uses model merge to integrate representations learned independently from three key Martian sensors (HiRISE, CTX, and THEMIS), spanning resolutions from 0.25 m/pixel to 100 m/pixel. Central to our method is our novel Equal Validation Loss (EVL) strategy, which aligns checkpoints across sensors based on validation loss similarity before fusion via task arithmetic. This ensures models are merged at compatible convergence stages, leading to improved stability and generalization. We train MOMO on a large-scale, high-quality corpus of $\sim 12$ million samples curated from Mars orbital data and evaluate it on 9 downstream tasks from Mars-Bench. MOMO achieves better overall performance compared to ImageNet pre-trained, earth observation foundation model, sensor-specific pre-training, and fully-supervised baselines. Particularly on segmentation tasks, MOMO shows consistent and significant performance improvement. Our results demonstrate that model merging through an optimal checkpoint selection strategy provides an effective approach for building foundation models for multi-resolution data. The model weights, pretraining code, pretraining data, and evaluation code are available at: https://github.com/kerner-lab/MOMO.
Uncertainty Quantification for Surface Ozone Emulators using Deep Learning
Aug 06, 2025Air pollution is a global hazard, and as of 2023, 94\% of the world's population is exposed to unsafe pollution levels. Surface Ozone (O3), an important pollutant, and the drivers of its trends are difficult to model, and traditional physics-based models fall short in their practical use for scales relevant to human-health impacts. Deep Learning-based emulators have shown promise in capturing complex climate patterns, but overall lack the interpretability necessary to support critical decision making for policy changes and public health measures. We implement an uncertainty-aware U-Net architecture to predict the Multi-mOdel Multi-cOnstituent Chemical data assimilation (MOMO-Chem) model's surface ozone residuals (bias) using Bayesian and quantile regression methods. We demonstrate the capability of our techniques in regional estimation of bias in North America and Europe for June 2019. We highlight the uncertainty quantification (UQ) scores between our two UQ methodologies and discern which ground stations are optimal and sub-optimal candidates for MOMO-Chem bias correction, and evaluate the impact of land-use information in surface ozone residual modeling.
Leveraging Deep Learning for Physical Model Bias of Global Air Quality Estimates
Aug 06, 2025Air pollution is the world's largest environmental risk factor for human disease and premature death, resulting in more than 6 million permature deaths in 2019. Currently, there is still a challenge to model one of the most important air pollutants, surface ozone, particularly at scales relevant for human health impacts, with the drivers of global ozone trends at these scales largely unknown, limiting the practical use of physics-based models. We employ a 2D Convolutional Neural Network based architecture that estimate surface ozone MOMO-Chem model residuals, referred to as model bias. We demonstrate the potential of this technique in North America and Europe, highlighting its ability better to capture physical model residuals compared to a traditional machine learning method. We assess the impact of incorporating land use information from high-resolution satellite imagery to improve model estimates. Importantly, we discuss how our results can improve our scientific understanding of the factors impacting ozone bias at urban scales that can be used to improve environmental policy.
Evaluating the Retrieval Robustness of Large Language Models
May 28, 2025


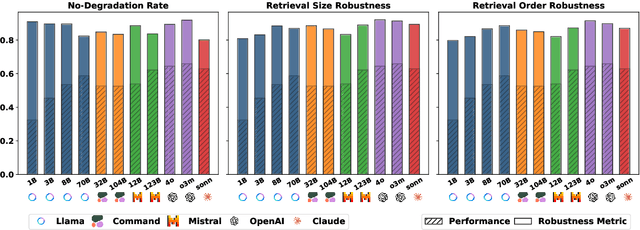
Retrieval-augmented generation (RAG) generally enhances large language models' (LLMs) ability to solve knowledge-intensive tasks. But RAG may also lead to performance degradation due to imperfect retrieval and the model's limited ability to leverage retrieved content. In this work, we evaluate the robustness of LLMs in practical RAG setups (henceforth retrieval robustness). We focus on three research questions: (1) whether RAG is always better than non-RAG; (2) whether more retrieved documents always lead to better performance; (3) and whether document orders impact results. To facilitate this study, we establish a benchmark of 1500 open-domain questions, each with retrieved documents from Wikipedia. We introduce three robustness metrics, each corresponds to one research question. Our comprehensive experiments, involving 11 LLMs and 3 prompting strategies, reveal that all of these LLMs exhibit surprisingly high retrieval robustness; nonetheless, different degrees of imperfect robustness hinders them from fully utilizing the benefits of RAG.
MixCE: Training Autoregressive Language Models by Mixing Forward and Reverse Cross-Entropies
May 26, 2023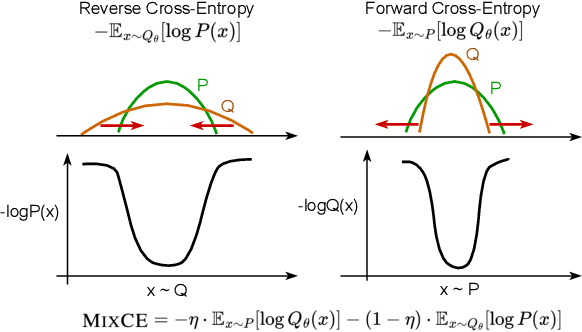
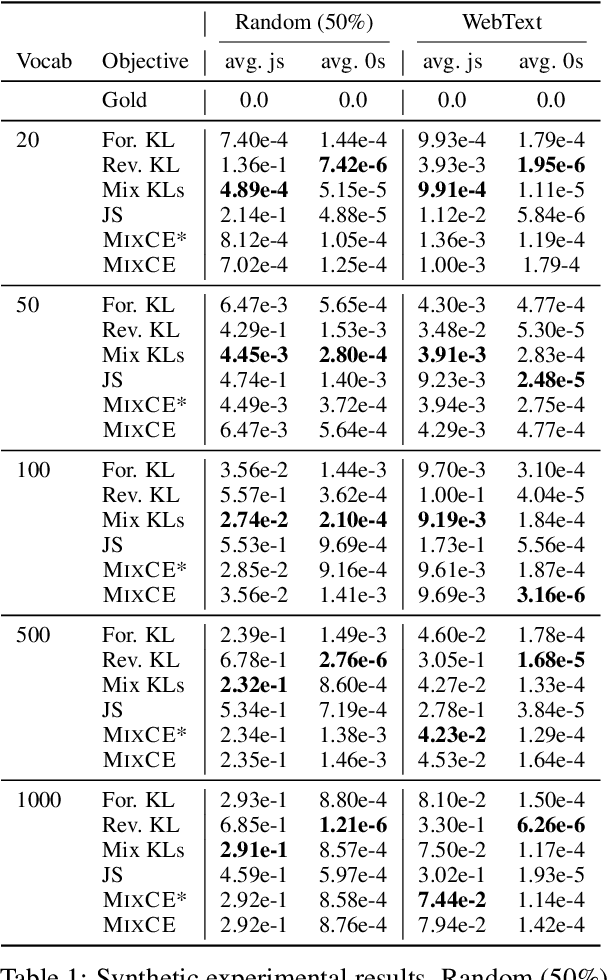
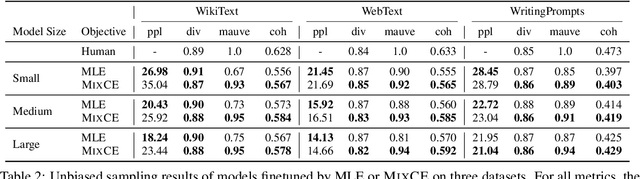
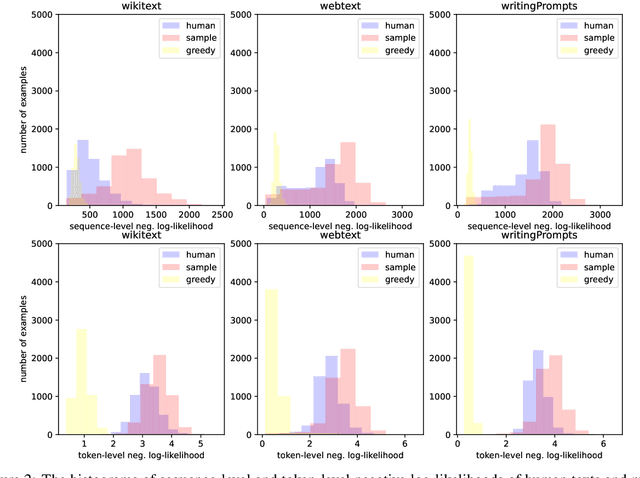
Autoregressive language models are trained by minimizing the cross-entropy of the model distribution Q relative to the data distribution P -- that is, minimizing the forward cross-entropy, which is equivalent to maximum likelihood estimation (MLE). We have observed that models trained in this way may "over-generalize", in the sense that they produce non-human-like text. Moreover, we believe that reverse cross-entropy, i.e., the cross-entropy of P relative to Q, is a better reflection of how a human would evaluate text generated by a model. Hence, we propose learning with MixCE, an objective that mixes the forward and reverse cross-entropies. We evaluate models trained with this objective on synthetic data settings (where P is known) and real data, and show that the resulting models yield better generated text without complex decoding strategies. Our code and models are publicly available at https://github.com/bloomberg/mixce-acl2023
BloombergGPT: A Large Language Model for Finance
Mar 30, 2023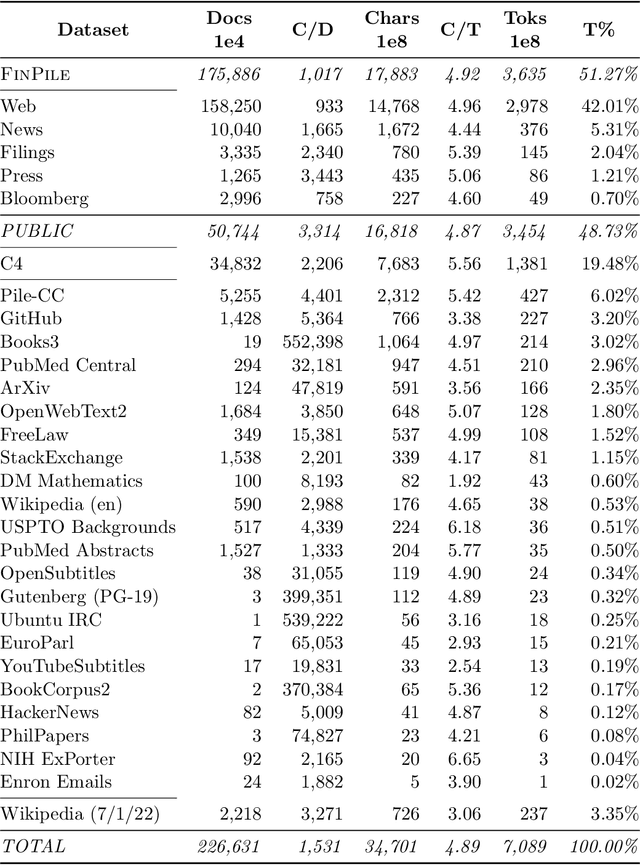
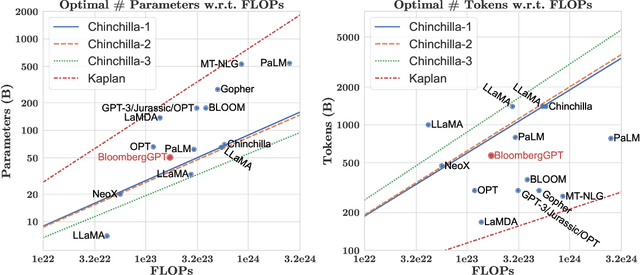
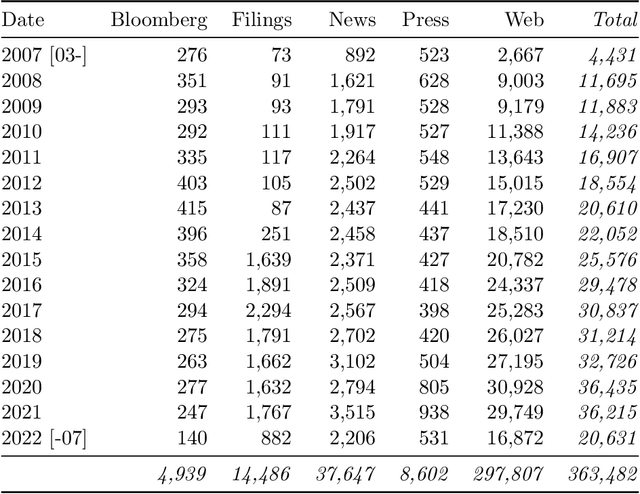
The use of NLP in the realm of financial technology is broad and complex, with applications ranging from sentiment analysis and named entity recognition to question answering. Large Language Models (LLMs) have been shown to be effective on a variety of tasks; however, no LLM specialized for the financial domain has been reported in literature. In this work, we present BloombergGPT, a 50 billion parameter language model that is trained on a wide range of financial data. We construct a 363 billion token dataset based on Bloomberg's extensive data sources, perhaps the largest domain-specific dataset yet, augmented with 345 billion tokens from general purpose datasets. We validate BloombergGPT on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that most accurately reflect our intended usage. Our mixed dataset training leads to a model that outperforms existing models on financial tasks by significant margins without sacrificing performance on general LLM benchmarks. Additionally, we explain our modeling choices, training process, and evaluation methodology. As a next step, we plan to release training logs (Chronicles) detailing our experience in training BloombergGPT.
Cosmic Microwave Background Recovery: A Graph-Based Bayesian Convolutional Network Approach
Feb 24, 2023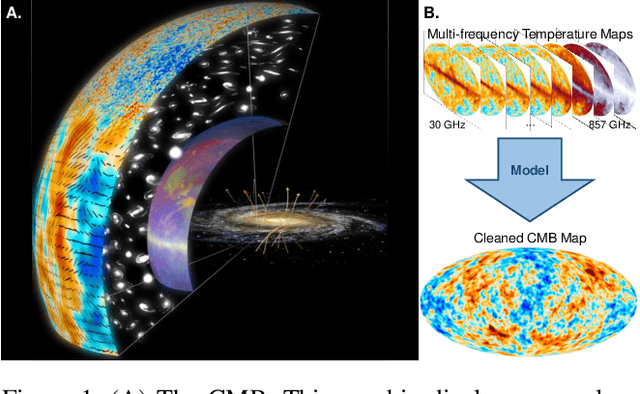
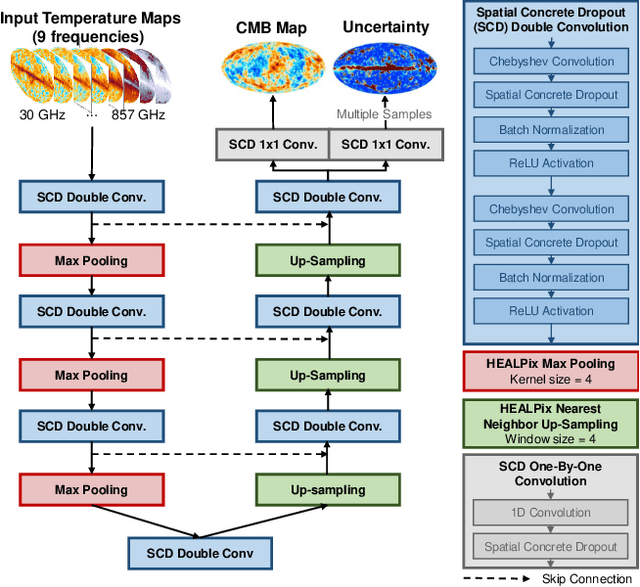

The cosmic microwave background (CMB) is a significant source of knowledge about the origin and evolution of our universe. However, observations of the CMB are contaminated by foreground emissions, obscuring the CMB signal and reducing its efficacy in constraining cosmological parameters. We employ deep learning as a data-driven approach to CMB cleaning from multi-frequency full-sky maps. In particular, we develop a graph-based Bayesian convolutional neural network based on the U-Net architecture that predicts cleaned CMB with pixel-wise uncertainty estimates. We demonstrate the potential of this technique on realistic simulated data based on the Planck mission. We show that our model accurately recovers the cleaned CMB sky map and resulting angular power spectrum while identifying regions of uncertainty. Finally, we discuss the current challenges and the path forward for deploying our model for CMB recovery on real observations.
Mars Image Content Classification: Three Years of NASA Deployment and Recent Advances
Feb 09, 2021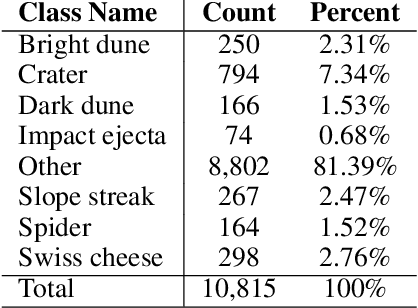


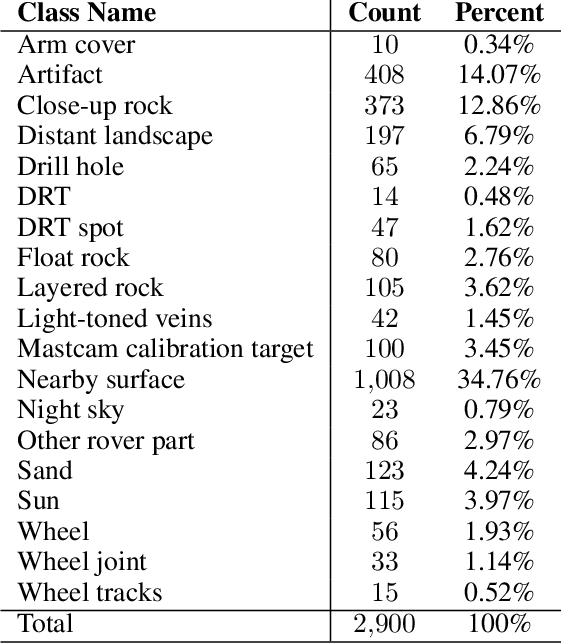
The NASA Planetary Data System hosts millions of images acquired from the planet Mars. To help users quickly find images of interest, we have developed and deployed content-based classification and search capabilities for Mars orbital and surface images. The deployed systems are publicly accessible using the PDS Image Atlas. We describe the process of training, evaluating, calibrating, and deploying updates to two CNN classifiers for images collected by Mars missions. We also report on three years of deployment including usage statistics, lessons learned, and plans for the future.
Constructing Dynamic Knowledge Graph for Visual Semantic Understanding and Applications in Autonomous Robotics
Sep 16, 2019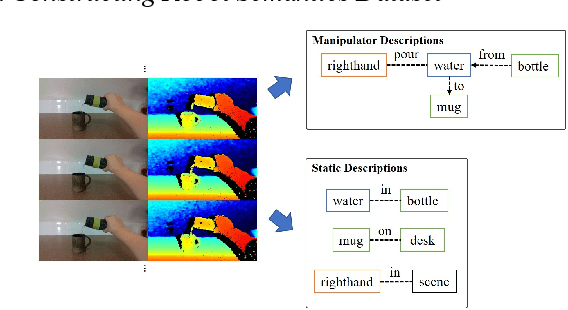
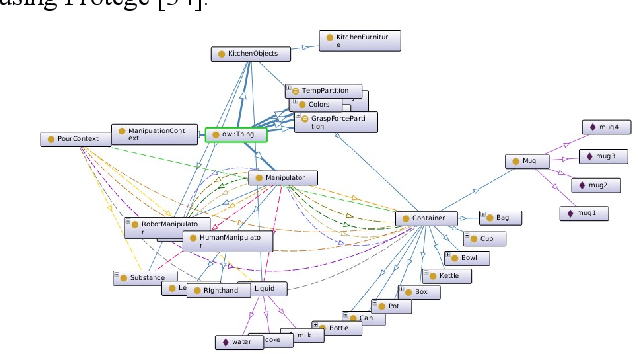

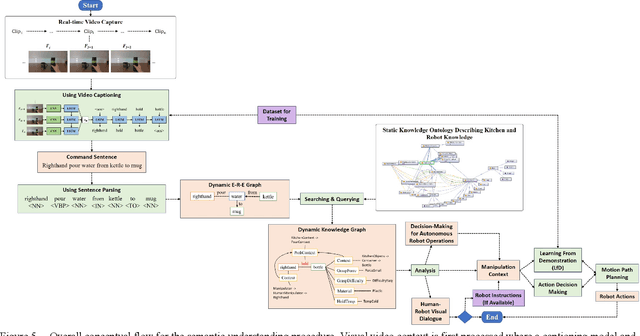
Interpreting semantic knowledge describing entities, relations and attributes explicitly with visuals and implicitly with in behind-scene common senses gain more attention in autonomous robotics. By incorporating vision and language modeling with common-sense knowledge, we can provide rich features indicating strong semantic meanings for human and robot action relationships, which can be utilized further in autonomous robotic controls. In this paper, we propose a systematic scheme to generate high-conceptual dynamic knowledge graphs representing Entity-Relation-Entity (E-R-E) and Entity-Attribute-Value (E-A-V) knowledges by "watching" a video clip. A combination of Vision-Language model and static ontology tree is used to illustrate workspace, configurations, functions and usages for both human and robot. The proposed method is flexible and well-versed. It will serve as our first positioning investigation for further research in various applications for autonomous robots.