 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraPHFormer: A Multimodal Graph Persistent Homology Transformer for the Analysis of Neuroscience Morphologies
Mar 21, 2026Neuronal morphology encodes critical information about circuit function, development, and disease, yet current methods analyze topology or graph structure in isolation. We introduce GraPHFormer, a multimodal architecture that unifies these complementary views through CLIP-style contrastive learning. Our vision branch processes a novel three-channel persistence image encoding unweighted, persistence-weighted, and radius-weighted topological densities via DINOv2-ViT-S. In parallel, a TreeLSTM encoder captures geometric and radial attributes from skeleton graphs. Both project to a shared embedding space trained with symmetric InfoNCE loss, augmented by persistence-space transformations that preserve topological semantics. Evaluated on six benchmarks (BIL-6, ACT-4, JML-4, N7, M1-Cell, M1-REG) spanning self-supervised and supervised settings, GraPHFormer achieves state-of-the-art performance on five benchmarks, significantly outperforming topology-only, graph-only, and morphometrics baselines. We demonstrate practical utility by discriminating glial morphologies across cortical regions and species, and detecting signatures of developmental and degenerative processes. Code: https://github.com/Uzshah/GraPHFormer
Highlighting the Importance of Reducing Research Bias and Carbon Emissions in CNNs
Jun 06, 2021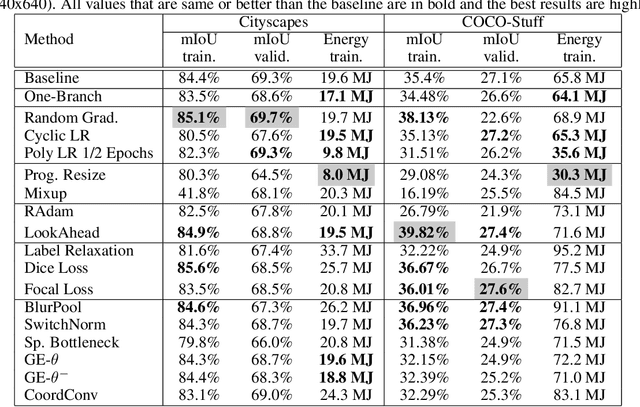

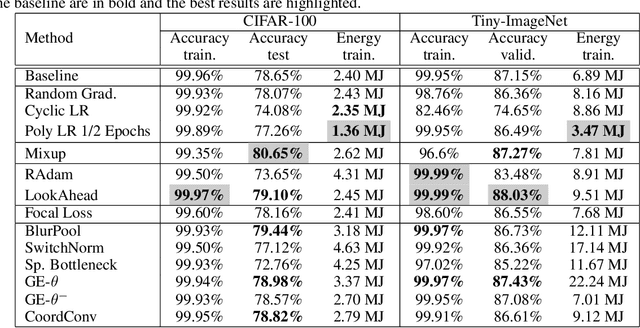
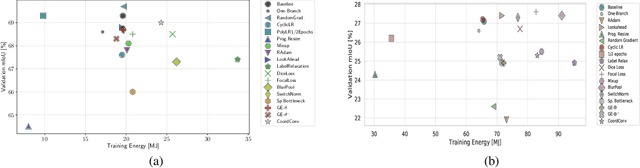
Convolutional neural networks (CNNs) have become commonplace in addressing major challenges in computer vision. Researchers are not only coming up with new CNN architectures but are also researching different techniques to improve the performance of existing architectures. However, there is a tendency to over-emphasize performance improvement while neglecting certain important variables such as simplicity, versatility, the fairness of comparisons, and energy efficiency. Overlooking these variables in architectural design and evaluation has led to research bias and a significantly negative environmental impact. Furthermore, this can undermine the positive impact of research in using deep learning models to tackle climate change. Here, we perform an extensive and fair empirical study of a number of proposed techniques to gauge the utility of each technique for segmentation and classification. Our findings restate the importance of favoring simplicity over complexity in model design (Occam's Razor). Furthermore, our results indicate that simple standardized practices can lead to a significant reduction in environmental impact with little drop in performance. We highlight that there is a need to rethink the design and evaluation of CNNs to alleviate the issue of research bias and carbon emissions.
Video Segmentation using Teacher-Student Adaptation in a Human Robot Interaction (HRI) Setting
Oct 17, 2018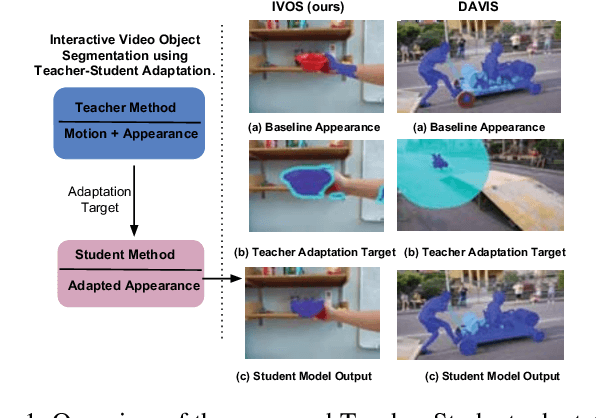


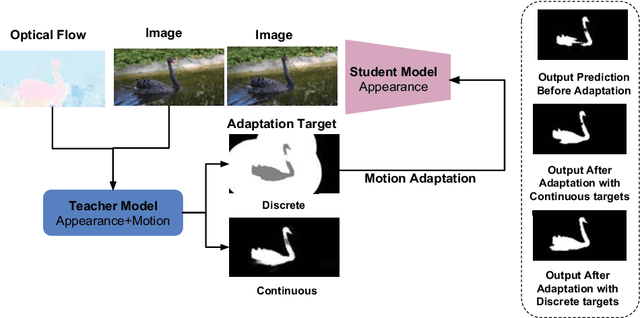
Video segmentation is a challenging task that has many applications in robotics. Learning segmentation from few examples on-line is important for robotics in unstructured environments. The total number of objects and their variation in the real world is intractable, but for a specific task the robot deals with a small subset. Our network is taught, by a human moving a hand-held object through different poses. A novel two-stream motion and appearance "teacher" network provides pseudo-labels. These labels are used to adapt an appearance "student" network. Segmentation can be used to support a variety of robot vision functionality, such as grasping or affordance segmentation. We propose different variants of motion adaptation training and extensively compare against the state-of-the-art methods. We collected a carefully designed dataset in the human robot interaction (HRI) setting. We denote our dataset as (L)ow-shot (O)bject (R)ecognition, (D)etection and (S)egmentation using HRI. Our dataset contains teaching videos of different hand-held objects moving in translation, scale and rotation. It contains kitchen manipulation tasks as well, performed by humans and robots. Our proposed method outperforms the state-of-the-art on DAVIS and FBMS with 7% and 1.2% in F-measure respectively. In our more challenging LORDS-HRI dataset, our approach achieves significantly better performance with 46.7% and 24.2% relative improvement in mIoU over the baseline.