 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning State Conditioned Linear Mappings for Low-Dimensional Control of Robotic Manipulators
Oct 28, 2024



Identifying an appropriate task space that simplifies control solutions is important for solving robotic manipulation problems. One approach to this problem is learning an appropriate low-dimensional action space. Linear and nonlinear action mapping methods have trade-offs between simplicity on the one hand and the ability to express motor commands outside of a single low-dimensional subspace on the other. We propose that learning local linear action representations that adapt based on the current configuration of the robot achieves both of these benefits. Our state-conditioned linear maps ensure that for any given state, the high-dimensional robotic actuations are linear in the low-dimensional action. As the robot state evolves, so do the action mappings, ensuring the ability to represent motions that are immediately necessary. These local linear representations guarantee desirable theoretical properties by design, and we validate these findings empirically through two user studies. Results suggest state-conditioned linear maps outperform conditional autoencoder and PCA baselines on a pick-and-place task and perform comparably to mode switching in a more complex pouring task.
* 7 Pages, 8 Figures, Presented at the 2023 IEEE International Conference on Robotics and Automation (ICRA)
A Quantitative Analysis of Activities of Daily Living: Insights into Improving Functional Independence with Assistive Robotics
Apr 08, 2021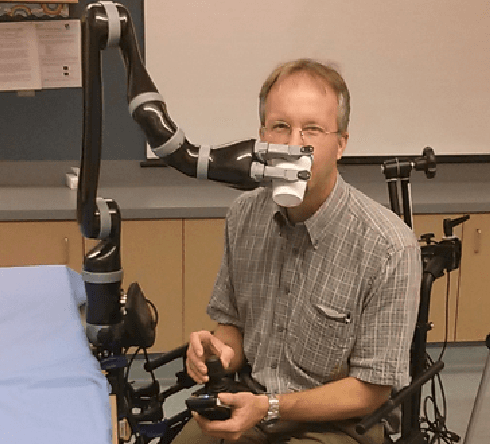
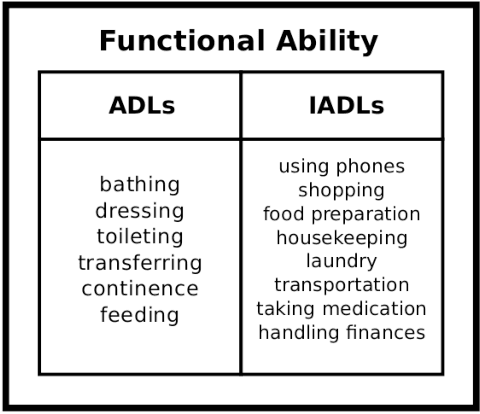
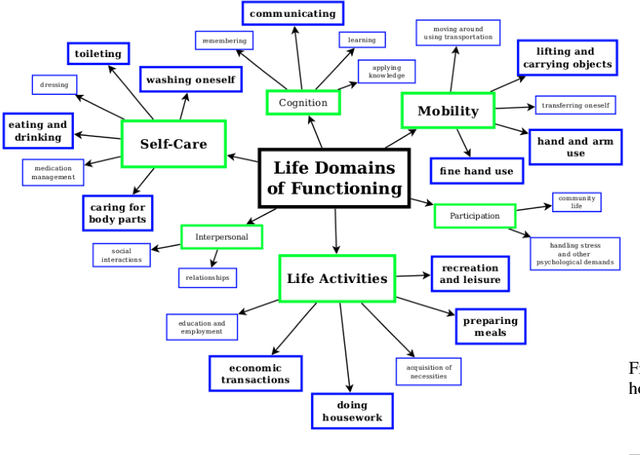
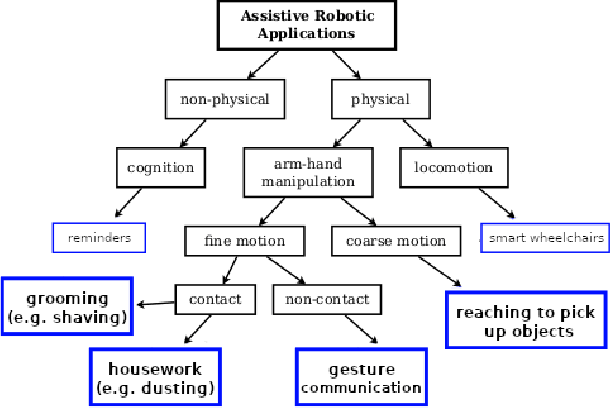
Human assistive robotics have the potential to help the elderly and individuals living with disabilities with their Activities of Daily Living (ADL). Robotics researchers focus on assistive tasks from the perspective of various control schemes and motion types. Health research on the other hand focuses on clinical assessment and rehabilitation, arguably leaving important differences between the two domains. In particular, little is known quantitatively on which ADLs are typically carried out in a persons everyday environment - at home, work, etc. Understanding what activities are frequently carried out during the day can help guide the development and prioritization of robotic technology for in-home assistive robotic deployment. This study targets several lifelogging databases, where we compute (i) ADL task frequency from long-term low sampling frequency video and Internet of Things (IoT) sensor data, and (ii) short term arm and hand movement data from 30 fps video data of domestic tasks. Robotics and health care communities have differing terms and taxonomies for representing tasks and motions. In this work, we derive and discuss a robotics-relevant taxonomy from quantitative ADL task and motion data in attempt to ameliorate taxonomic differences between the two communities. Our quantitative results provide direction for the development of better assistive robots to support the true demands of the healthcare community.
Assistive arm and hand manipulation: How does current research intersect with actual healthcare needs?
Jan 07, 2021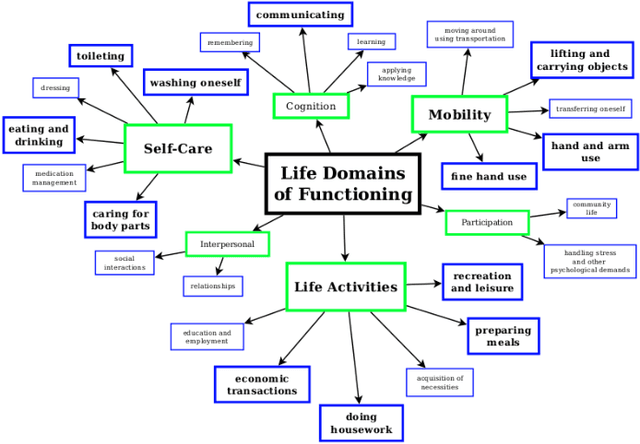
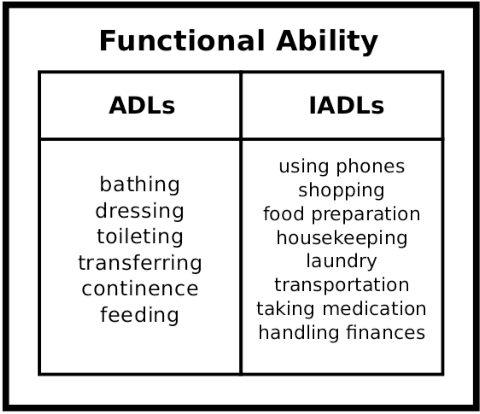
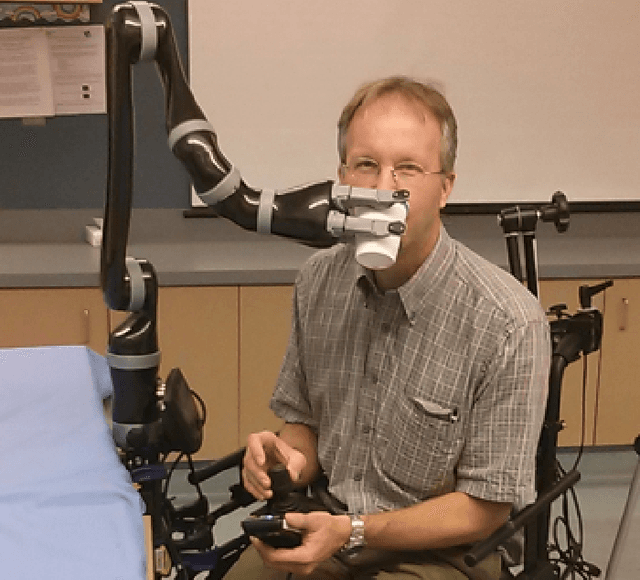
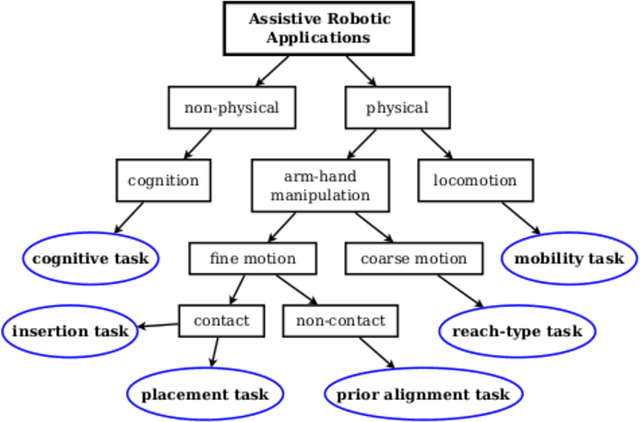
Human assistive robotics have the potential to help the elderly and individuals living with disabilities with their Activities of Daily Living (ADL). Robotics researchers present bottom up solutions using various control methods for different types of movements. Health research on the other hand focuses on clinical assessment and rehabilitation leaving arguably important differences between the two domains. In particular, little is known quantitatively on what ADLs humans perform in their everyday environment - at home, work etc. This information can help guide development and prioritization of robotic technology for in-home assistive robotic deployment. This study targets several lifelogging databases, where we compute (i) ADL task frequency from long-term low sampling frequency video and Internet of Things (IoT) sensor data, and (ii) short term arm and hand movement data from 30 fps video data of domestic tasks. Robotics and health care communities have different terms and taxonomies for representing tasks and motions. We derive and discuss a robotics-relevant taxonomy from this quantitative ADL task and ICF motion data in attempt to ameliorate these taxonomic differences. Our statistics quantify that humans reach, open drawers, doors, and retrieve and use objects hundreds of times a day. Commercial wheelchair mounted robot arms can help 150,000 upper body disabled in the USA alone, but only a few hundred robots are deployed. Better user interfaces, and more capable robots can increase the potential user base and number of ADL tasks solved significantly.
A Geometric Perspective on Visual Imitation Learning
Mar 05, 2020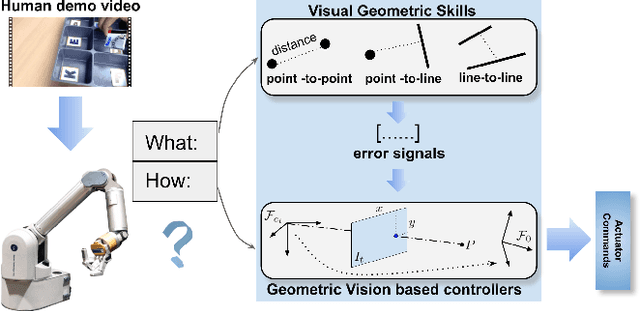
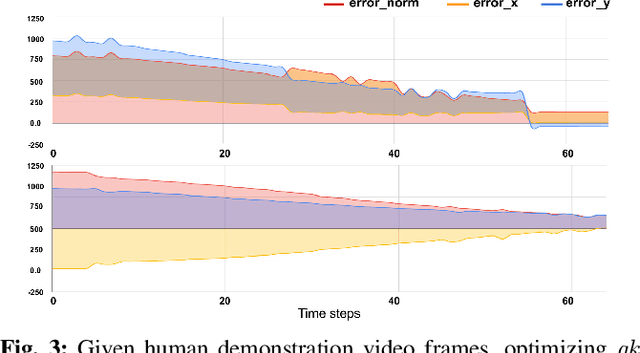
We consider the problem of visual imitation learning without human supervision (e.g. kinesthetic teaching or teleoperation), nor access to an interactive reinforcement learning (RL) training environment. We present a geometric perspective to derive solutions to this problem. Specifically, we propose VGS-IL (Visual Geometric Skill Imitation Learning), an end-to-end geometry-parameterized task concept inference method, to infer globally consistent geometric feature association rules from human demonstration video frames. We show that, instead of learning actions from image pixels, learning a geometry-parameterized task concept provides an explainable and invariant representation across demonstrator to imitator under various environmental settings. Moreover, such a task concept representation provides a direct link with geometric vision based controllers (e.g. visual servoing), allowing for efficient mapping of high-level task concepts to low-level robot actions.
Visual Geometric Skill Inference by Watching Human Demonstration
Nov 08, 2019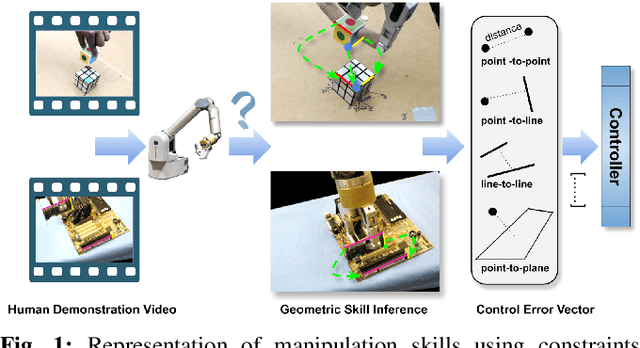
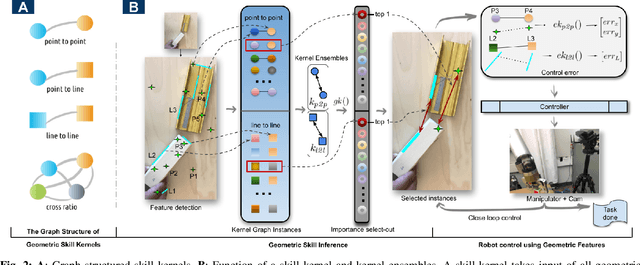
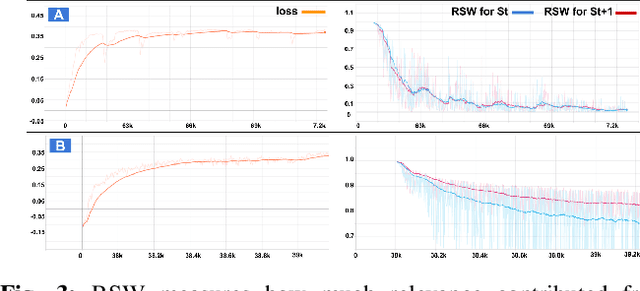

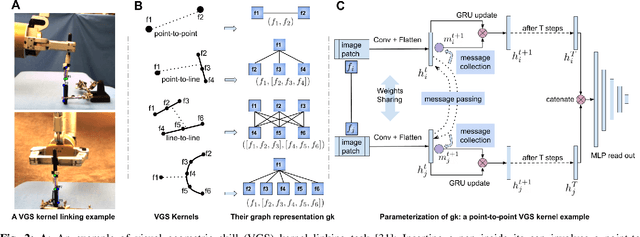
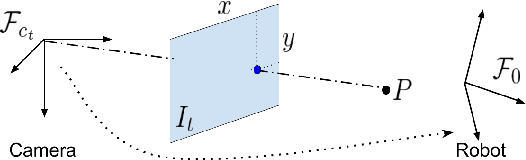
We study the problem of learning manipulation skills from human demonstration video by inferring association relationship between geometric features. Our motivation comes from the observation in human eye-hand coordination that a set of manipulation skills are actually minimizing the Euclidean distance between geometric primitives while regressing their association constraints in non-Euclidean space. We propose a graph based kernel regression method to directly infer the underlying association constraints from human demonstration video using Incremental Maximum Entropy Inverse Reinforcement Learning (InMaxEnt IRL). The learned skill inference provides human readable task definition and outputs control errors that can be directly plugged into traditional controllers. Our method removes the need of tedious feature selection and robust feature trackers in traditional approaches (e.g. feature based visual servoing). Experiments show our method reaches high accuracy even with only one human demonstration video and generalize well under variances.
Long range teleoperation for fine manipulation tasks under time-delay network conditions
Mar 21, 2019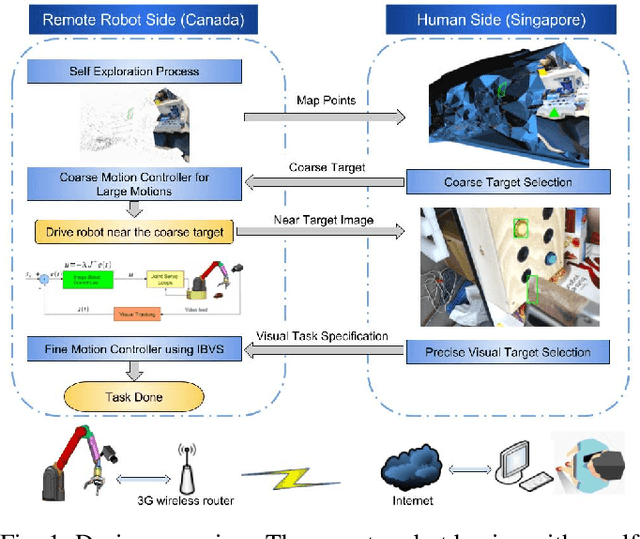
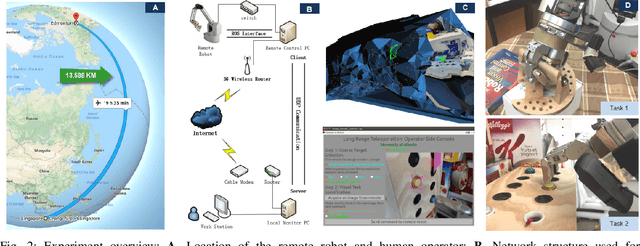
We present a coarse-to-fine approach based semi-autonomous teleoperation system using vision guidance. The system is optimized for long range teleoperation tasks under time-delay network conditions and does not require prior knowledge of the remote scene. Our system initializes with a self exploration behavior that senses the remote surroundings through a freely mounted eye-in-hand web cam. The self exploration stage estimates hand-eye calibration and provides a telepresence interface via real-time 3D geometric reconstruction. The human operator is able to specify a visual task through the interface and a coarse-to-fine controller guides the remote robot enabling our system to work in high latency networks. Large motions are guided by coarse 3D estimation, whereas fine motions use image cues (IBVS). Network data transmission cost is minimized by sending only sparse points and a final image to the human side. Experiments from Singapore to Canada on multiple tasks were conducted to show our system's capability to work in long range teleoperation tasks.
Evaluation of state representation methods in robot hand-eye coordination learning from demonstration
Mar 02, 2019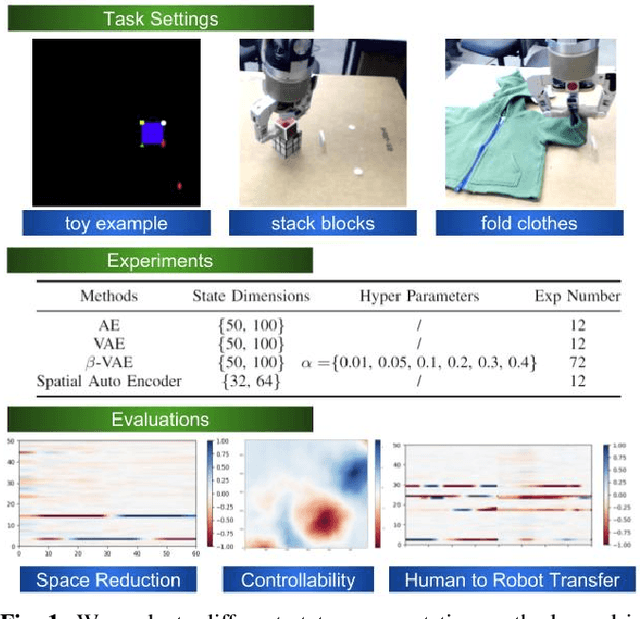

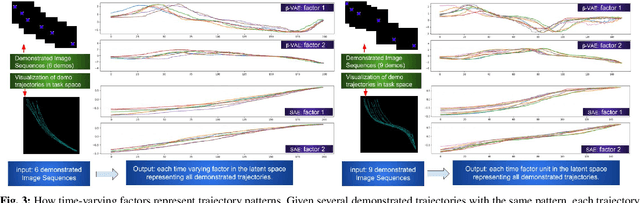
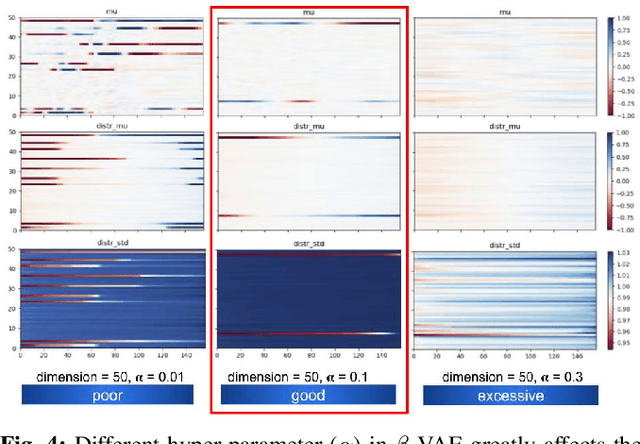
We evaluate different state representation methods in robot hand-eye coordination learning on different aspects. Regarding state dimension reduction: we evaluates how these state representation methods capture relevant task information and how much compactness should a state representation be. Regarding controllability: experiments are designed to use different state representation methods in a traditional visual servoing controller and a REINFORCE controller. We analyze the challenges arisen from the representation itself other than from control algorithms. Regarding embodiment problem in LfD: we evaluate different method's capability in transferring learned representation from human to robot. Results are visualized for better understanding and comparison.
Online Object and Task Learning via Human Robot Interaction
Feb 27, 2019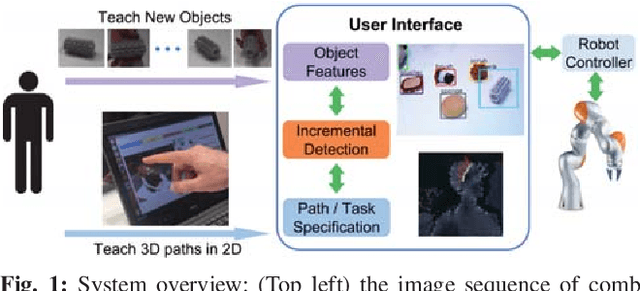
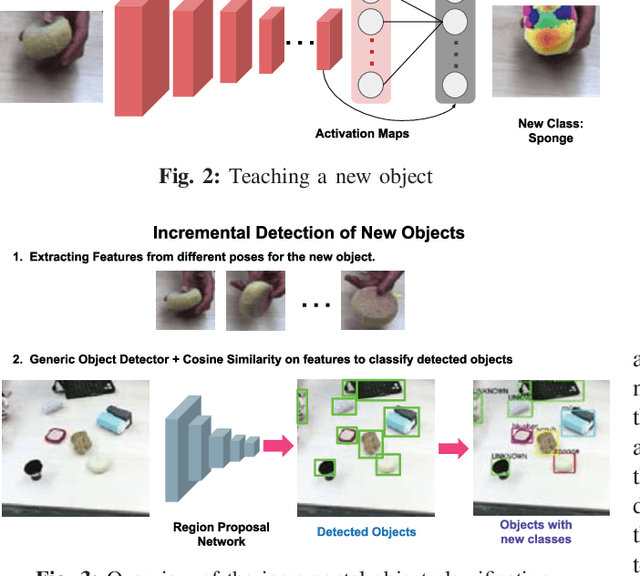
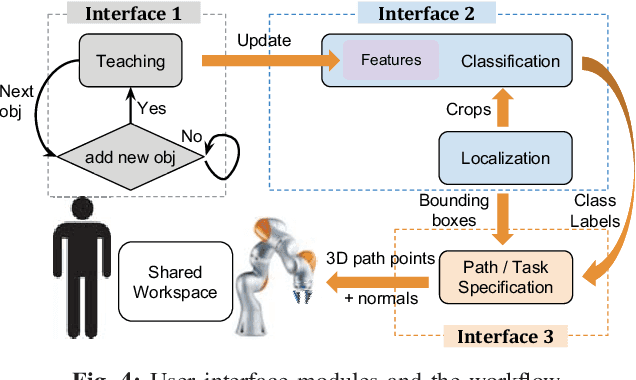

This work describes the development of a robotic system that acquires knowledge incrementally through human interaction where new tools and motions are taught on the fly. The robotic system developed was one of the five finalists in the KUKA Innovation Award competition and demonstrated during the Hanover Messe 2018 in Germany. The main contributions of the system are a) a novel incremental object learning module - a deep learning based localization and recognition system - that allows a human to teach new objects to the robot, b) an intuitive user interface for specifying 3D motion task associated with the new object, c) a hybrid force-vision control module for performing compliant motion on an unstructured surface. This paper describes the implementation and integration of the main modules of the system and summarizes the lessons learned from the competition.
Robot eye-hand coordination learning by watching human demonstrations: a task function approximation approach
Feb 27, 2019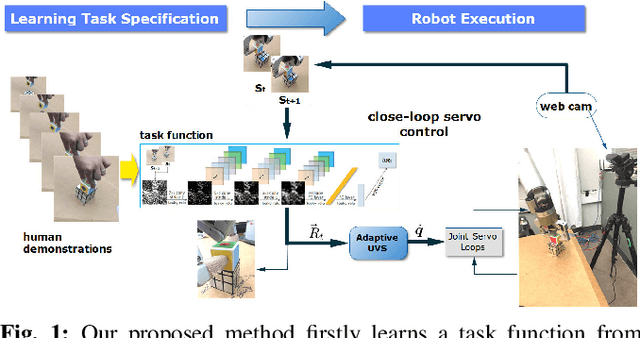
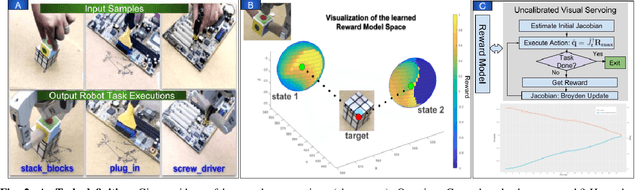


We present a robot eye-hand coordination learning method that can directly learn visual task specification by watching human demonstrations. Task specification is represented as a task function, which is learned using inverse reinforcement learning(IRL) by inferring differential rewards between state changes. The learned task function is then used as continuous feedbacks in an uncalibrated visual servoing(UVS) controller designed for the execution phase. Our proposed method can directly learn from raw videos, which removes the need for hand-engineered task specification. It can also provide task interpretability by directly approximating the task function. Besides, benefiting from the use of a traditional UVS controller, our training process is efficient and the learned policy is independent from a particular robot platform. Various experiments were designed to show that, for a certain DOF task, our method can adapt to task/environment variances in target positions, backgrounds, illuminations, and occlusions without prior retraining.
Video Segmentation using Teacher-Student Adaptation in a Human Robot Interaction (HRI) Setting
Oct 17, 2018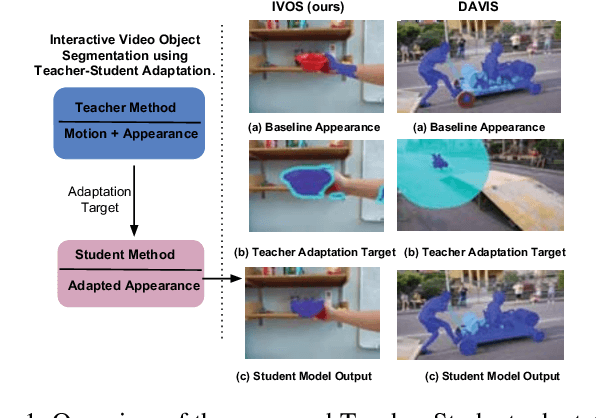


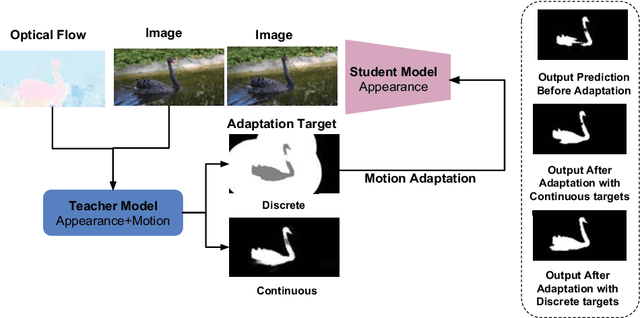
Video segmentation is a challenging task that has many applications in robotics. Learning segmentation from few examples on-line is important for robotics in unstructured environments. The total number of objects and their variation in the real world is intractable, but for a specific task the robot deals with a small subset. Our network is taught, by a human moving a hand-held object through different poses. A novel two-stream motion and appearance "teacher" network provides pseudo-labels. These labels are used to adapt an appearance "student" network. Segmentation can be used to support a variety of robot vision functionality, such as grasping or affordance segmentation. We propose different variants of motion adaptation training and extensively compare against the state-of-the-art methods. We collected a carefully designed dataset in the human robot interaction (HRI) setting. We denote our dataset as (L)ow-shot (O)bject (R)ecognition, (D)etection and (S)egmentation using HRI. Our dataset contains teaching videos of different hand-held objects moving in translation, scale and rotation. It contains kitchen manipulation tasks as well, performed by humans and robots. Our proposed method outperforms the state-of-the-art on DAVIS and FBMS with 7% and 1.2% in F-measure respectively. In our more challenging LORDS-HRI dataset, our approach achieves significantly better performance with 46.7% and 24.2% relative improvement in mIoU over the baseline.